概要描述
本文主要描述数据血缘的生成原理及在星环平台中的应用。
详细说明
什么是数据血缘
数据血缘(Data Lineage)指的是数据之间的关系和依赖的追踪过程。简单来说,就是数据从哪里来,到哪里去,中间发生了什么变化的全过程。
数据库的数据血缘主要包括:
- 源数据:数据最初的输入源,比如用户输入,传感器采集等。
- 数据处理:源数据经过什么样的处理、计算、聚合或者过滤得到了新的数据。
- 数据传播:数据给哪些系统、应用或者用户使用了。
- 数据存储:数据存储在哪些表、文件中。
数据血缘对很多场景都很重要:
- 数据质量:通过数据血缘可以轻易找到造成数据质量问题的源头,比如错误的源数据输入、软件BUG等。
- 审计和合规:通过数据血缘可以审核数据是如何被创建和使用的,满足法规遵从性要求。
- 数据生命周期管理:跟踪数据从入库到删除/归档的完整过程。
- 数据安全和隐私:通过数据血缘判断哪些人员和系统访问使用过数据,控制数据的安全性和隐私性。
数据库一般通过系统的审计日志来重构数据血缘,相比应用层的数据血缘追踪要全面和准确得多。许多数据治理工具也提供了数据血缘管理和追踪的功能。
所以总体来说,数据血缘可以让企业全面了解企业数据的来源、流通和用途,这对许多场景下的合规性、数据安全性、数据质量管理等都非常关键。
星环 TDS 产品可以查看数据库的血缘关系,如图。
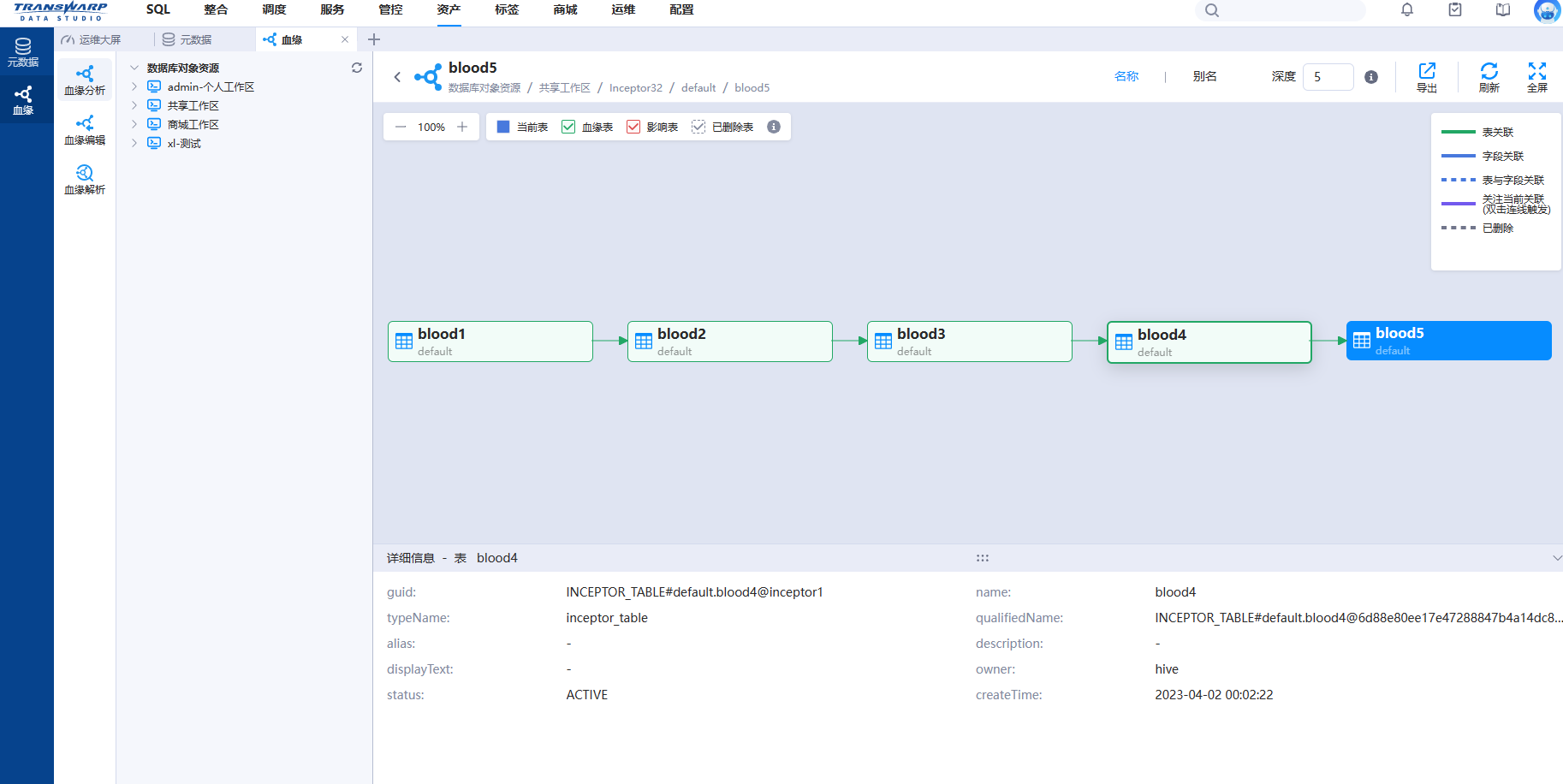
以上血缘关系是根据下面这段SQL生成的:
drop table IF EXISTS default.blood1;
drop table IF EXISTS default.blood2;
drop table IF EXISTS default.blood3;
drop table IF EXISTS default.blood4;
drop table IF EXISTS default.blood5;
create table default.blood1(id int, name string, age int, address string) CLUSTERED BY (age) INTO 2 BUCKETS STORED AS ORC TBLPROPERTIES ("transactional"="true");
insert into table default.blood1 values(1, "jack", 18, "shanghai");
create table default.blood2 as select id,name,age,address from default.blood1;
create table default.blood3 as select id,name,age,address from default.blood2;
create table default.blood4 as select id,name,age,address from default.blood3;
create table default.blood5 as select id,name,age,address from default.blood4;血缘生成的逻辑
可生成血缘的SQL操作
下面以星环 Inceptor 数据库为例,介绍哪些SQL操作可以生成血缘。
| 关系单位A | 关系单位B | SQL操作 | 备注 |
|---|---|---|---|
| 任何表 | 任何表 | CTAS | |
| 任何表 | 任何表 | ALTER/RENAME TABLE | |
| 任何表 | 某字段 | ALTER ADD/DELETE/CHANGE COLUMN | REPLACE COLUMN 操作会破坏原有血缘 |
| 外表 | 范围分区表 | INSERT INTO SELECT | |
| 外表 | 单值分区表 | 多条件的 INSERT INTO SELECT | 必须存在真实的数据流向才能生成血缘 |
| TEXT表 | 单值分区表 | 多条件的 UPDATE | 必须存在真实的数据流向才能生成血缘 |
| TEXT表 | ORC表 | MERGE INTO | |
| CSV/TEXT/ORC表 | ORC表 | 带条件的INNER/LEFT/RIGHT JOIN CTAS | |
| CSV/TEXT/ORC表 | ORC表 | PLSQL背景下,具体的血缘SQL来源于字段血缘 | |
| 视图 | ORC表 | 多条件的 INSERT INTO SELECT | |
| 视图 | ORC表 | WITH … AS | |
| 多字段 | 某字段 | INSERT INTO 字段数据通过计算得到新的字段 |
一些注意事项的说明
关于TDS数据加载
TDS 数据加载最终也是 INSERT INTO 操作,但即使是同库不同表的数据加载任务也不会产生血缘。这是因为数据加载会用到一些中间视图,且中间视图在任务执行完毕后被清理掉了,这会造成血缘的断裂。
即使不清理中间临时数据也可能不会生成血缘,这是因为默认配置下 Catalog 过滤了 TDT 临时表。
关于视图
视图被看作是虚拟表,从视图到目标表最中数据流向会体现为真实的数据表到目标表,例如:
create table test_table1(col1 int,col2 string) stored as ORC;
create view test_view as select * from test_table1;
create table test_table2 as select * from test_view;该操作生成的血缘如下图:
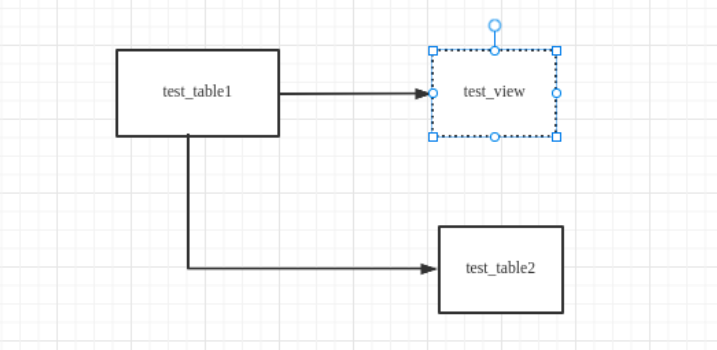
但如果是物化视图,那么 test_view -> test_table2 这条血缘就会存在。
关于单值分区表
单值分区表的分区键是一个目录,转换成血缘的要求是有真实的数据流向,即必须实际新增或更新了数据,例如 INSERT INTO SELECT 操作,SELECT 必须能查出实际的结果(且不能为常数),不能是空查询。
一些典型操作案例
--测试 alter 操作
create table test_alter_table(col1 int,col2 string, col3 varchar(10));
--生成血缘表,血缘关系test_alter_table(col1,col2,col3) --> test_table(col1,col2,col3)
create table test_table as select * from test_alter_table;
--原来的血缘被破坏,test_alter_table这张表变成只有col4,col5 两个字段的表
Alter table test_alter_table replace columns (col4 string,col5 int);
--生成新的血缘,血缘关系:test_table(col2,col1)-->test_alter_table(col4,col5)
insert into test_alter_table select col2,col1 from test_table;
----
--测试 INSERT 操作
create table test1.table91(id int, name string, age int, address string) CLUSTERED BY (age) INTO 2 BUCKETS STORED AS ORC TBLPROPERTIES ("transactional"="true");
create table test1.table92(id int, name string, age int, address string) CLUSTERED BY (age) INTO 2 BUCKETS STORED AS ORC TBLPROPERTIES ("transactional"="true");
--直接导入常数,不涉及字段之间的数据流向,不生成血缘
insert into table test1.table91 values(1, "jack", 18, "shanghai");
--数据来源自己,生成table91=>table91成环血缘
INSERT INTO test1.table91 SELECT a.id,a.name,a.age,a.address FROM test1.table91 a WHERE a.id=1;
--虽然有自己的字段条件,但是数据流向是常数,故不生成血缘
INSERT INTO test1.table91 SELECT 1, "jack", 18, "shanghai" FROM test1.table91 a WHERE a.id=1;
--生成table91=>table92血缘
INSERT INTO test1.table92 SELECT a.id,a.name,a.age,a.address FROM test1.table91 a WHERE a.id=1;
--不生成血缘
INSERT INTO test1.table92 SELECT 1, "jack", 18, "shanghai" FROM test1.table91 a WHERE a.id=1;
--测试 UPDATE 操作
create table test1.table93(id int, name string, age int, address string) CLUSTERED BY (age) INTO 2 BUCKETS STORED AS ORC TBLPROPERTIES ("transactional"="true");
create table test1.table94(id int, name string, age int, address string) CLUSTERED BY (age) INTO 2 BUCKETS STORED AS ORC TBLPROPERTIES ("transactional"="true");
--不生成血缘
update test1.table93 set name='jack11' where age=18;
--生成table93=>table93成环血缘
UPDATE test1.table93 a SET a.name=(SELECT b.name FROM test1.table93 b WHERE b.id=a.id) WHERE a.id=1;
--不生成血缘
UPDATE test1.table93 a SET a.name=(SELECT 'jack222' FROM test1.table93 b WHERE b.id=a.id) WHERE a.id=1;
--生成table93=>table94血缘
UPDATE test1.table94 a SET a.name=(SELECT b.name FROM test1.table93 b WHERE b.id=a.id) WHERE a.id=1;
--不生成血缘
UPDATE test1.table94 a SET a.name=(SELECT 'jack222' FROM test1.table93 b WHERE b.id=a.id) WHERE a.id=1;
--测试LIKE操作
create table test_like(name string,age smallint);
--不生成血缘,因为只有表结构的复制,不涉及数据流向
create table test_1 like test_like;
--生成血缘,不经复制了表结构,表里面的数据也同样的复制
create table test_2 as select * from test_like;星环平台数据血缘功能兼容的数据库
在星环平台中,数据血缘功能是通过 TDS 产品实现的,具体支持的数据库请参考:
若要查看某个数据库的血缘,请确保正确安装 TDS 产品的 Catalog 组件,并在目标数据库中安装 Catalog 插件。