概要描述
本文主要描述 TDS (2.x及以上版本)数据加载的基本原理。
详细说明
Transporter 概述
以下简称 Transporter 为 TDT 。
定位与变迁
TDT 组件在很早的版本就有,在 TDS 还没有从 TDH 中独立出来(版本号为 transwarp-xxx)一直到 TDS 1.x,其定位一直都是 Inceptor 的 ETL 工具,具备数据流、批量数据流等功能模块。
在 TDS 2.x 时代,TDT 的定位发生了变化,主要用于 ELT 。所以 2.x 以后的 TDT 主要保留了批量数据流的功能,而不再保留数据流功能。
ETL 与 ELT
上面提到了 TDT 在不同时期的定位分别是 ETL 和 ELT 。
什么是 ETL ?顾名思义,它是指 Extract-Transform-Load ,用来描述将数据从源端经过抽取、转换和加载至目标端的过程。
那什么是 ELT 呢?类推可以知道它是指 Extract-Load-Transform ,它跟 ETL 的区别在于它是先加载再转换数据。随着现代数据存储系统的计算能力不断提高,在越来越多的场景下,先加载再转换会更为有效,这也是 TDT 定位发生变迁的原因。
数据流与批量数据流
上面提到在 1.x 及之前版本的 TDT 中,其包含数据流和批量数据流功能。
所谓数据流,就是一次将数据抽取、转换、加载到 Inceptor 的过程。整个过程又分为两个阶段,分别是编译和运行。编译阶段主要是一些准备工作,如上传驱动文件、获取表的大小、确认目标表的分区分桶信息等;运行阶段主要是运行SQL和监控任务的状态。在 TDT 的数据流功能中,支持多样的算子来实现转换过程,并且支持DAG图的拖拉拽操作,非常便捷和灵活。
而批量数据流则是一个支持批量构建多个数据流的过程,它大大简化了多次创建和调用的过程,但代价是无法实现数据流灵活的转换能力,不支持DAG的拖拉拽。
数据加载任务的请求过程
数据加载任务主要是 TDT 与 Inceptor (或 ArgoDB、Quark 等,以下都用 Inceptor 替代)之间协作完成的。整体的流程图如下所示:
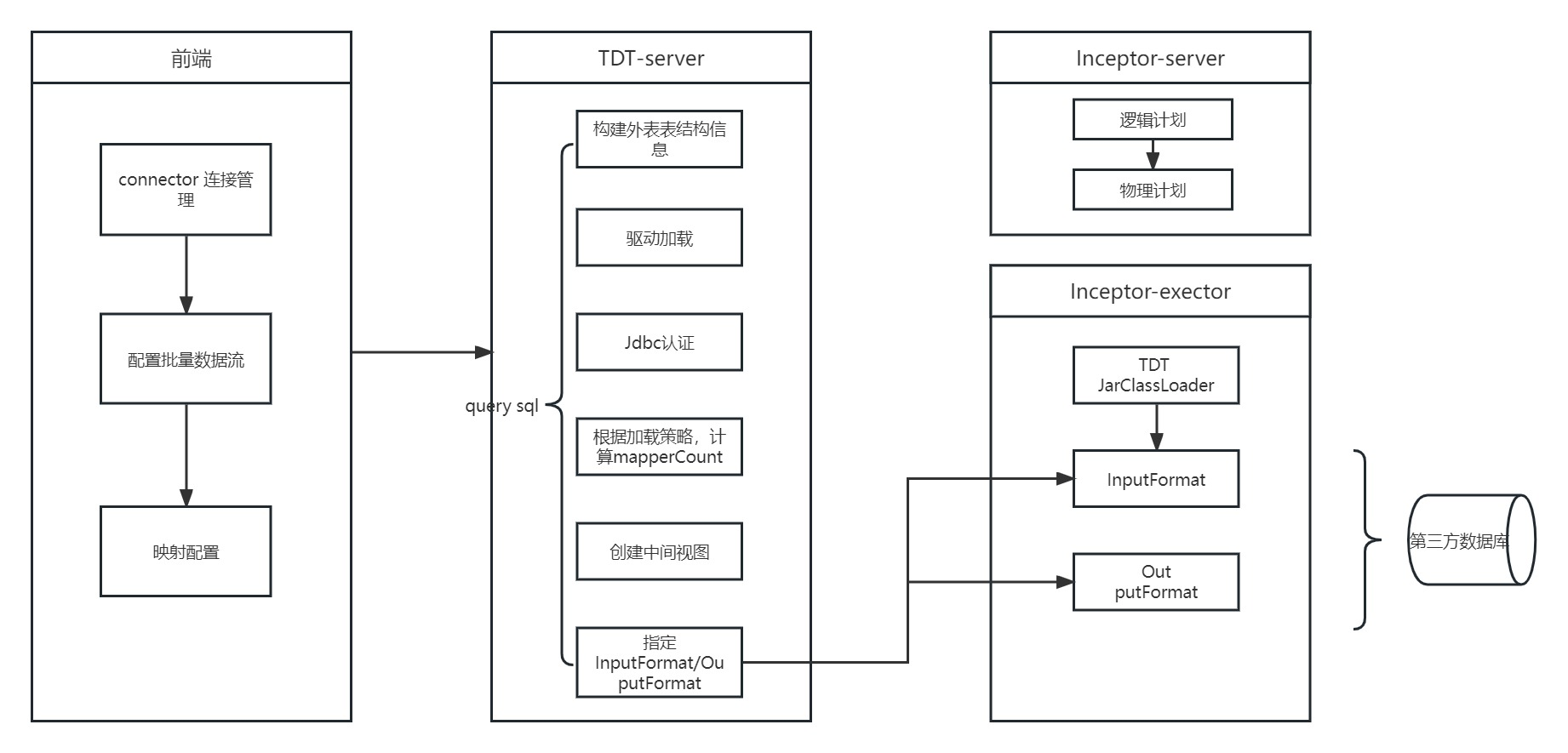
可以看出,整个流程大体可以分为前端配置、TDT Server、Inceptor Server、Inceptor Executor 四个过程。
前端配置
整个前端配置过程就是在 TDS 的数据加载任务配置界面完成的。
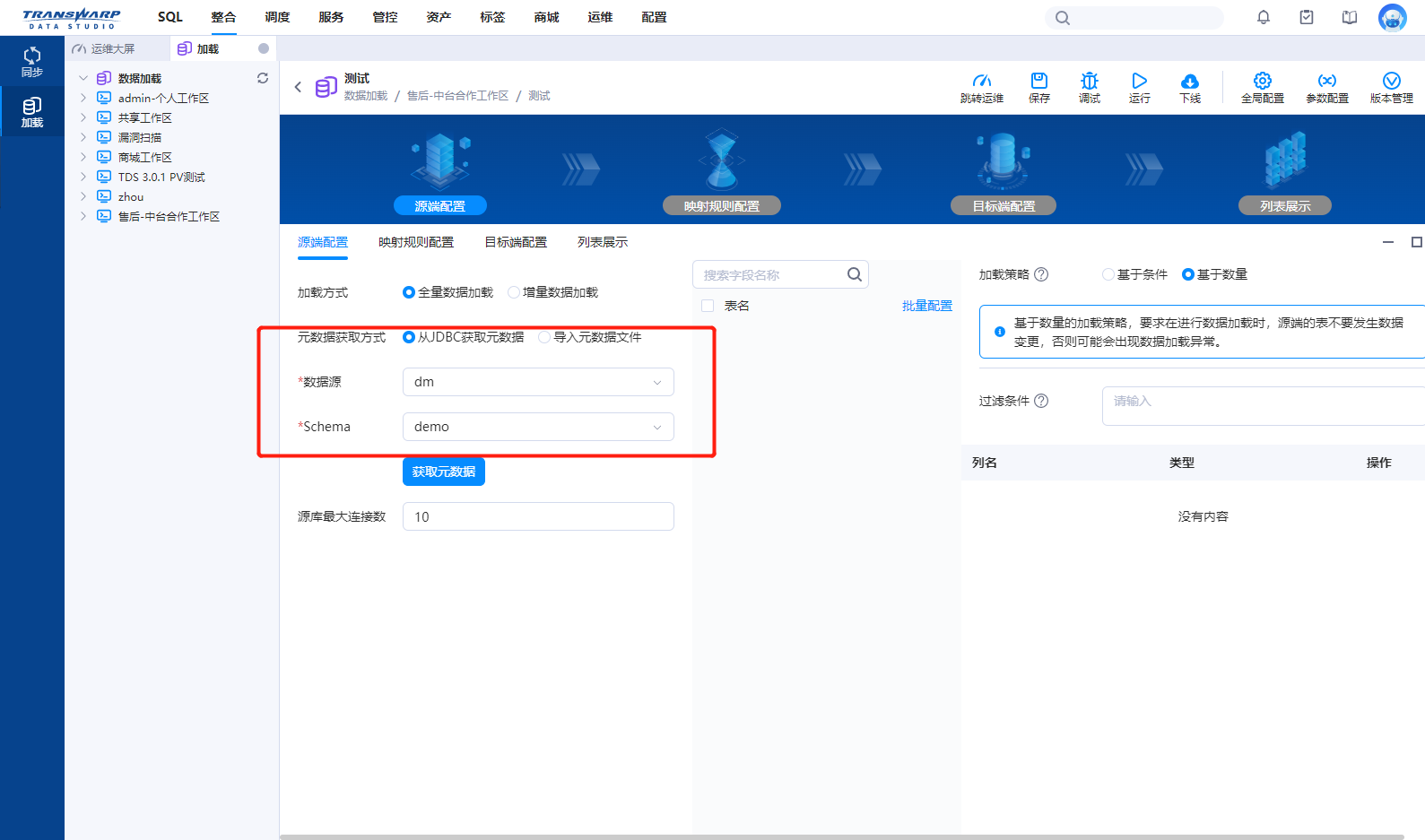
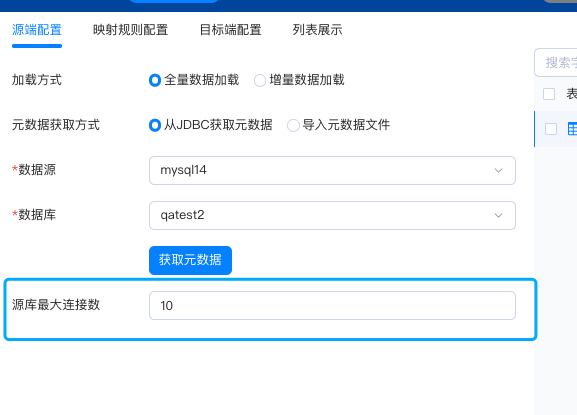
Step 1. 源端配置
Step 2. 映射规则配置
Step 3. 目标端配置
在整个过程中,源端和目标端的选择是通过 Connector (即 Foundation 的 Connector 角色)的 API 调用完成的,如果在该过程出现报错,需要查看 TDT 和 Connector 的日志。
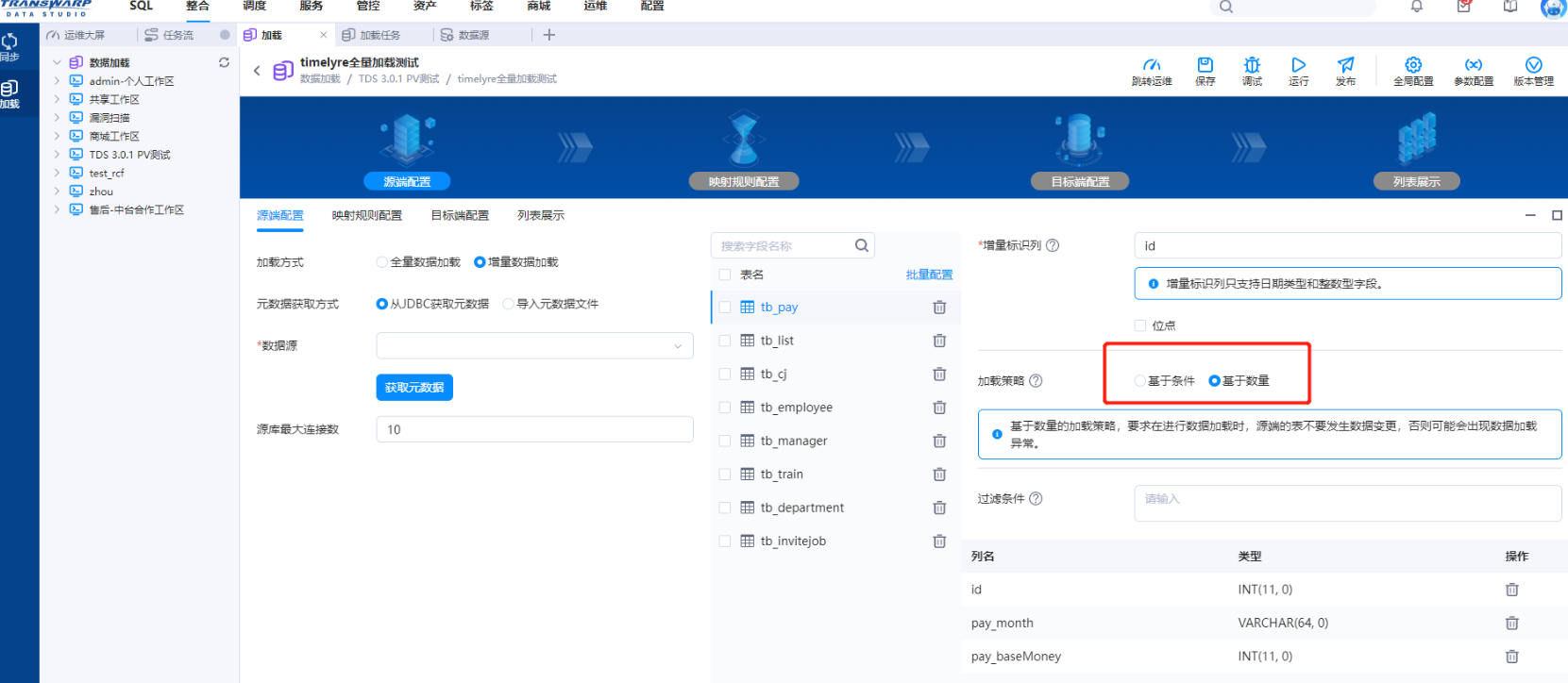
需要特别注意源端配置可以选择基于条件或基于数量的加载策略。两种加载策略的原理会在后文详述。
TDT Server
前端配置完成后,点击运行或调试或者加载任务被调度时,请求就发给了后端,到达 TDT Server。
Step 1. 加载驱动并上传到 HDFS
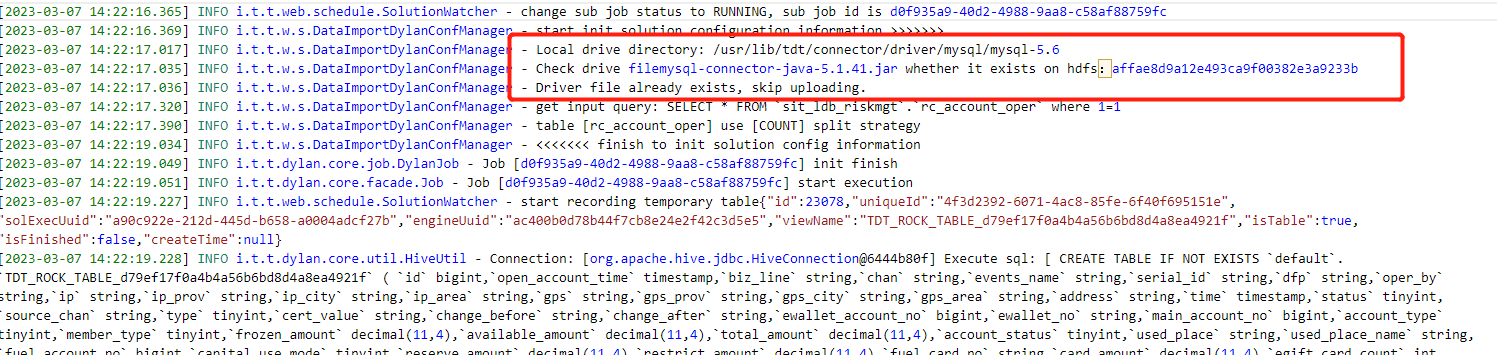
Step 2. 查询源库并确定 JDBC 读取源库需要使用的连接数
Step 3. 解析映射规则并生成创建外表
Step 4. 根据外表创建中间视图
Step 5. 从最后一个中间视图通过 INSERT INTO SELECT FROM 的方式加载到目标表
其中步骤1是 TDT 配合 Connector 完成的,步骤2是 TDT 连接源库查询,步骤3-5是 TDT 生成 SQL 后提交到执行端 Inceptor 执行的。
Inceptor Server
TDT Server 步骤3-5中的 SQL 都会被提交到 Inceptor Server 上。SQL 提交到 Inceptor Server 后,主要会做词法分析和语法分析,如果词法分析或语法分析有错误会抛出异常,例如:
Inceptor Executor
Inceptor Server 上词法分析和语法分析通过后,编译成功的 SQL 会被提交到 Inceptor Executor 上。
Step 1. Inceptor Executor 的 pod 中会启动一个 tdt 的进程用来处理 InputFormat/OutputFormat 逻辑
这个进程是通过 TDT Plugin 启动的,当前只要 Inceptor 打过最新的 Patch 都会自动部署 TDT Plugin 。
Step 2. Inceptor Executor 通过 tdt 进程处理 InputFormat/OutputFormat 传过来的数据,频繁与源端数据库交互。
数据加载的两种策略
数据加载有两种加载策略,分别是基于数量和基于条件。本节将描述他们的原理与区别。
基于数量
- 确定 mapperCount
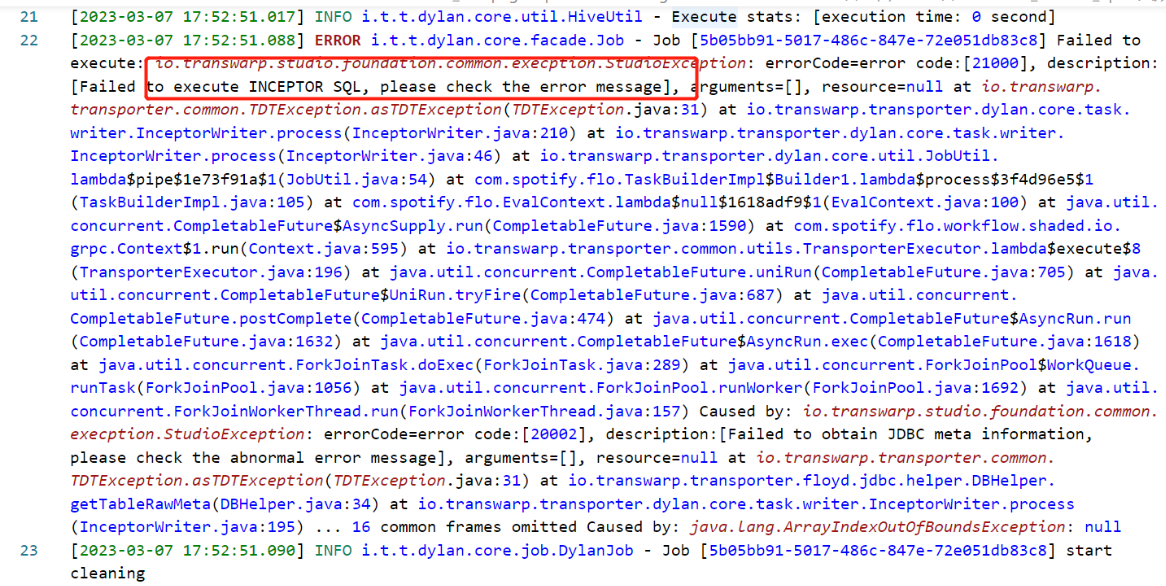
mapperCount 即为 TDT 生成的外表 SQL 中确定的 JDBC 读源库的连接数量。每个连接处理的数据量叫做 mapperSize ,通过参数 tdt.jdbc.mapper.size 确定,默认是 1024 即1GB。
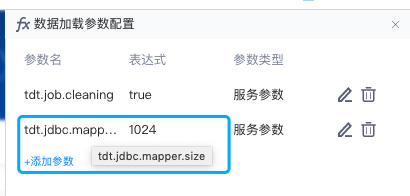
要计算 mapperCount ,还需要知道源表的数据量,这个一般是通过去源端的系统表中查询得到的,不同的数据库查询方式不一样。
但是 mapperCount 也绝不是简单的数据量大小 / mapperSize 就行了,因为它还受到源库最大连接数这个参数的制约。
所以 mapperCount 的结果应该是估算的源表数据量大小除以 mapperSize 后,向上取整,如果结果没有超过源库最大连接数的话这就是 mapperCount 的值,如果结果超过源库最大连接数,那么 mapperCount 的结果就是源库最大连接数。
用伪代码表示的话:
Long mapper.size = 1024
--利用源端数据库的sql计算出表的大小,不同的数据库的计算sql不一样
Long tabeleSize;
Long Count;
Long mapperCount;
Count=tableSize/mapper.size;
mapperCount=Min(Count,MaxConnection);
--进行切分时,每个offset=tableSize/mapperCount;举个例子,若 mapperSize 为 1GB,源表数量为5.5GB,则 mapperCount 为6;源表数量为 11 GB,则 mapperCount 为 10。
如果抽取的源端是普通视图,不存在物理大小概念的话,则直接使用数据量来进行切分。
mapperCount 会在 TDT 生成的外表 SQL 中体现,即mapreduce.jdbc.splits.number属性。
- 拆分策略
基于数量拆分的原理是 limit offset 进行分片,offset 的值是根据数据总条数和 mapperCount 确定的 ,每个线程处理同样的数据量,如图所示。

基于条件
基于条件策略的 mapperCount 计算逻辑与基于数量完全一致,只是拆分策略有所不同。
- 确定 mapperCount
mapperCount 即为 TDT 生成的外表 SQL 中确定的 JDBC 读源库的连接数量。每个连接处理的数据量叫做 mapperSize ,通过参数 tdt.jdbc.mapper.size 确定,默认是 1024 即1GB。
要计算 mapperCount ,还需要知道源表的数据量,这个一般是通过去源端的系统表中查询得到的,不同的数据库查询方式不一样。
但是 mapperCount 也绝不是简单的数据量大小 / mapperSize 就行了,因为它还受到源库最大连接数这个参数的制约。
所以 mapperCount 的结果应该是估算的源表数据量大小除以 mapperSize 后,向上取整,如果结果没有超过源库最大连接数的话这就是 mapperCount 的值,如果结果超过源库最大连接数,那么 mapperCount 的结果就是源库最大连接数。
用伪代码表示的话:
Long mapper.size = 1024
--利用源端数据库的sql计算出表的大小,不同的数据库的计算sql不一样
Long tabeleSize;
Long Count;
Long mapperCount;
Count=tableSize/mapper.size;
mapperCount=Min(Count,MaxConnection);
--进行切分时,每个offset=tableSize/mapperCount;举个例子,若 mapperSize 为 1GB,源表数量为5.5GB,则 mapperCount 为6;源表数量为 11 GB,则 mapperCount 为 10。
如果抽取的源端是普通视图,不存在物理大小概念的话,则直接使用数据量来进行切分。
mapperCount 会在 TDT 生成的外表 SQL 中体现,即mapreduce.jdbc.splits.number属性。
- 拆分策略
基于条件的拆分必须指定切分列。
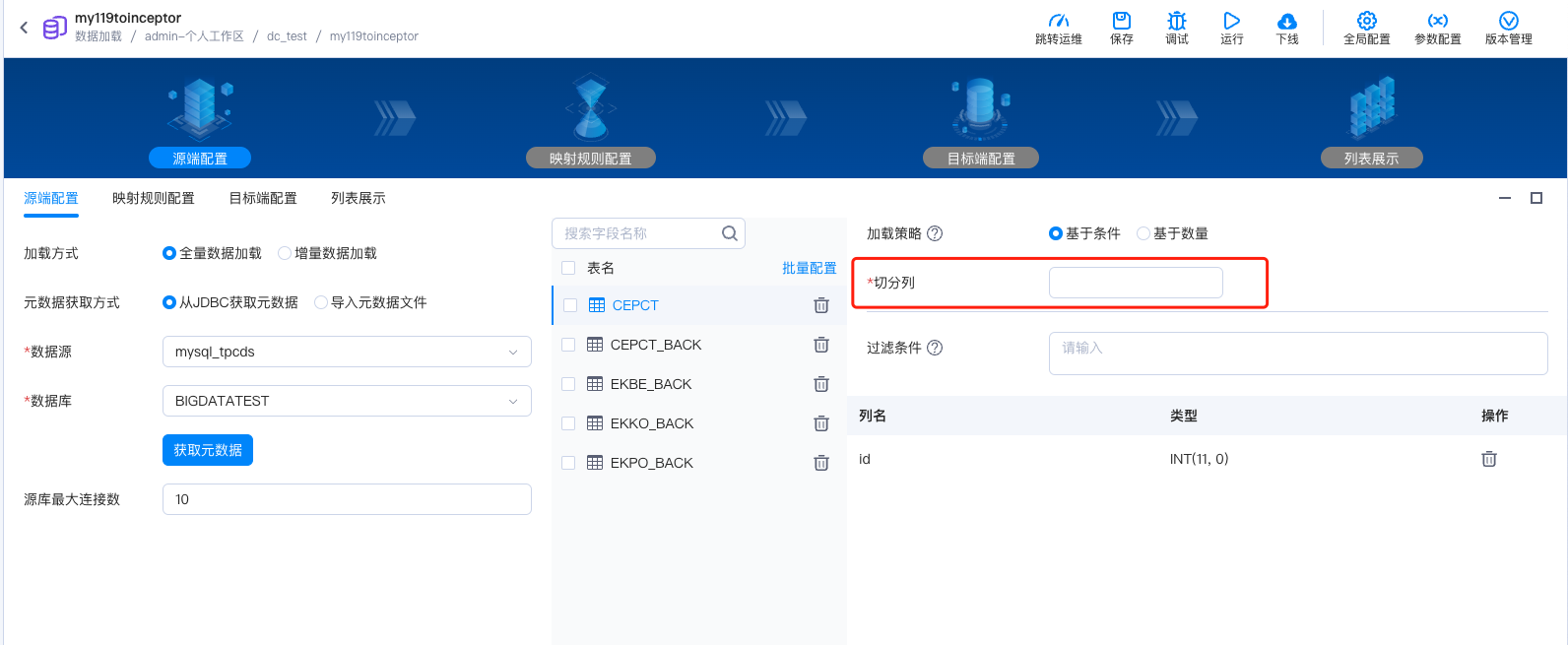
通过前端配置选择的切分列,通过 select max(切分列) from table;计算出切分列的最大值,然后按照 mapperCount 进行数据切分加载。所以要求切分列的数据分布均匀,否则容易出现数据切分倾斜;并且要求切分列数据类型支持比较,例如时间类型等。
基于条件策略的使用的方法是通过切分列进行数据范围的均匀切分。

两种策略的注意事项
-
基于数量策略不推荐用于源端有大量变化的场景,否则容易出现丢数或重复数据的问题
-
基于数量策略的性能影响因素主要有 count(*) 语句执行效率和均分数据的 SQL 执行效率
-
基于条件策略建议切分列的数值分布均匀,否则会出现某些线程数据倾斜的问题,影响整个任务执行的性能
-
基于条件策略的切分列最好是数值型或时间型
任务连接数及并发度
TDT 通过任务配置的源端最大连接数及允许最大并发度来限制人物的执行。
-
任务执行前,会先获取源表数据信息,获取数据量、计算表大小
-
允许最大并发度限制的是同时执行的子任务的数量
-
实际执行受到源端最大连接数与目标端最大并发度的共同限制
-
子任务执行结束,会释放占有的连接数及并发数