概要描述
Linux 手册中有一个介绍 Linux 命名空间的定义:
A namespace wraps a global system resource in an abstraction that makes it appear to the processes within the namespace that they have their own isolated instance of the global resource. Changes to the global resource are visible to other processes that are members of the namespace, but are invisible to other processes.namespace 将全局系统资源包装在一个抽象中,这使得 namespace 中的进程似乎具有自己的全局资源的独立实例。对全局资源的更改对作为 namespace 成员的其他进程可见,但对其他进程不可见。
Linux network namespaces 是 Linux 内核的一项功能,允许我们通过虚拟化隔离网络环境。例如,使用 network namespaces ,可以创建独立的网络接口和路由表,这些网络接口和表与系统的其余部分隔离并独立运行。
Linux namespaces 是 Docker 和 Kubernetes 等容器技术的基础。
详细说明
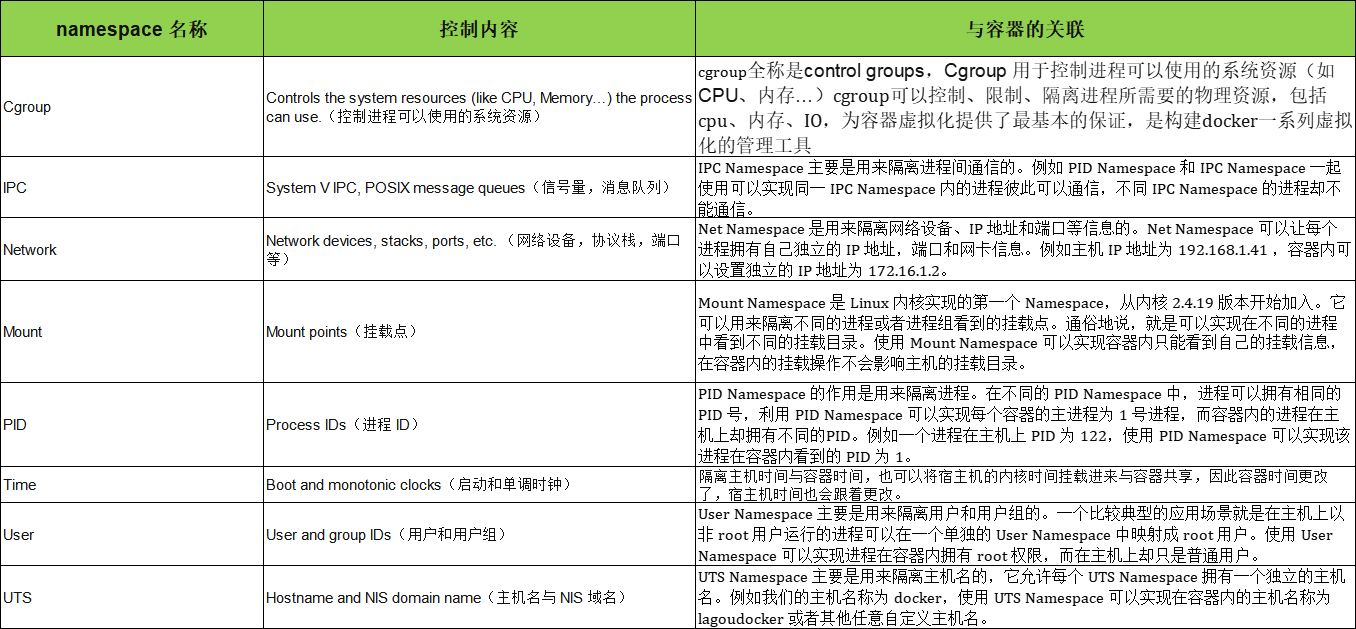
1. 各种 Namespace 的作用
Namespace 是 Linux 内核的一个特性,该特性可以实现在同一主机系统中,对进程 ID、主机名、用户 ID、文件名、网络和进程间通信等资源的隔离。Docker 利用 Linux 内核的 Namespace 特性,实现了每个容器的资源相互隔离,从而保证容器内部只能访问到自己 Namespace 的资源。
目前 Linux 内核中提供了 8 种类型的 Namespace:
下载链接:
为什么构建容器需要 Namespace
2. 为什么 Docker 需要 Namespace?
Linux 内核从 2002 年 2.4.19 版本开始加入了 Mount Namespace,而直到内核 3.8 版本加入了 User Namespace 才为容器提供了足够的支持功能。
当 Docker 新建一个容器时, 它会创建这六种 Namespace,然后将容器中的进程加入这些 Namespace 之中,使得 Docker 容器中的进程只能看到当前 Namespace 中的系统资源。
正是由于 Docker 使用了 Linux 的这些 Namespace 技术,才实现了 Docker 容器的隔离,可以说没有 Namespace,就没有 Docker 容器。
3. Docker exec 原理
在了解了 Linux Namespace 的隔离机制后,你应该会很自然地想到一个问题:docker exec 是怎么做到进入容器里的呢?
实际上,Linux Namespace 创建的隔离空间虽然看不见摸不着,但一个进程的 Namespace 信息在宿主机上是确确实实存在的,并且是以一个文件的方式存在。
首先创建一个容器:
$ docker run -p 4000:80 helloworld python app.py通过如下指令,你可以看到当前正在运行的 Docker 容器的进程号(PID)是 25686:
$ docker inspect --format '{{ .State.Pid }}' 4ddf4638572d25686这时,你可以通过查看宿主机的 proc 文件,看到这个 25686 进程的所有 Namespace 对应的文件:
$ ls -l /proc/25686/ns
total 0
lrwxrwxrwx 1 root root 0 Aug 13 14:05 cgroup -> cgroup:[4026531835]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 ipc -> ipc:[4026532278]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 mnt -> mnt:[4026532276]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 net -> net:[4026532281]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 pid -> pid:[4026532279]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 pid_for_children -> pid:[4026532279]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 uts -> uts:[4026532277]可以看到,一个进程的每种 Linux Namespace,都在它对应的 /proc/[进程号]/ns 下有一个对应的虚拟文件,并且链接到一个真实的 Namespace 文件上。
有了这样一个可以“hold 住”所有 Linux Namespace 的文件,我们就可以对 Namespace 做一些很有意义事情了,比如:加入到一个已经存在的 Namespace 当中。
这也就意味着:一个进程,可以选择加入到某个进程已有的 Namespace 当中,从而达到“进入”这个进程所在容器的目的,这正是 docker exec 的实现原理。
而这个操作所依赖的,乃是一个名叫 setns() 的 Linux 系统调用。它的调用方法,我可以用如下一段小程序为你说明:
#define _GNU_SOURCE
#include
#include
#include
#include
#include
#define errExit(msg) do { perror(msg); exit(EXIT_FAILURE);} while (0)
int main(int argc, char *argv[]) {
int fd;
fd = open(argv[1], O_RDONLY);
if (setns(fd, 0) == -1) {
errExit("setns");
}
execvp(argv[2], &argv[2]);
errExit("execvp");
}
这段代码功能非常简单:它一共接收两个参数,第一个参数是 argv[1],即当前进程要加入的 Namespace 文件的路径,比如 /proc/25686/ns/net;而第二个参数,则是你要在这个 Namespace 里运行的进程,比如 /bin/bash。
这段代码的核心操作,则是通过 open() 系统调用打开了指定的 Namespace 文件,并把这个文件的描述符 fd 交给 setns() 使用。在 setns() 执行后,当前进程就加入了这个文件对应的 Linux Namespace 当中了。
现在,你可以编译执行一下这个程序,加入到容器进程(PID=25686)的 Network Namespace 中:
$ gcc -o set_ns set_ns.c
$ ./set_ns /proc/25686/ns/net /bin/bash
$ ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:ac:11:00:02
inet addr:172.17.0.2 Bcast:0.0.0.0 Mask:255.255.0.0
inet6 addr: fe80::42:acff:fe11:2/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:12 errors:0 dropped:0 overruns:0 frame:0
TX packets:10 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:976 (976.0 B) TX bytes:796 (796.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
正如上所示,当我们执行 ifconfig 命令查看网络设备时,我会发现能看到的网卡“变少”了:只有两个。而我的宿主机则至少有四个网卡。这是怎么回事呢?
实际上,在 setns() 之后我看到的这两个网卡,正是我在前面启动的 Docker 容器里的网卡。也就是说,我新创建的这个 /bin/bash 进程,由于加入了该容器进程(PID=25686)的 Network Namepace,它看到的网络设备与这个容器里是一样的,即:/bin/bash 进程的网络设备视图,也被修改了。
而一旦一个进程加入到了另一个 Namespace 当中,在宿主机的 Namespace 文件上,也会有所体现。
在宿主机上,你可以用 ps 指令找到这个 set_ns 程序执行的 /bin/bash 进程,其真实的 PID 是 28499:
# 在宿主机上
ps aux | grep /bin/bash
root 28499 0.0 0.0 19944 3612 pts/0 S 14:15 0:00 /bin/bash
这时,如果查看一下这个 PID=28499 的进程的 Namespace,你就会发现这样一个事实:
$ ls -l /proc/28499/ns/net
lrwxrwxrwx 1 root root 0 Aug 13 14:18 /proc/28499/ns/net -> net:[4026532281]
$ ls -l /proc/25686/ns/net
lrwxrwxrwx 1 root root 0 Aug 13 14:05 /proc/25686/ns/net -> net:[4026532281]
在 /proc/[PID]/ns/net 目录下,这个 PID=28499 进程,与我们前面的 Docker 容器进程(PID=25686)指向的 Network Namespace 文件完全一样。这说明这两个进程,共享了这个名叫 net:[4026532281]的 Network Namespace。
此外,Docker 还专门提供了一个参数,可以让你启动一个容器并“加入”到另一个容器的 Network Namespace 里,这个参数就是 -net,比如:
$ docker run -it --net container:4ddf4638572d busybox ifconfig这样,我们新启动的这个容器,就会直接加入到 ID=4ddf4638572d 的容器,也就是我们前面的创建的应用容器(PID=25686)的 Network Namespace 中。所以,这里 ifconfig 返回的网卡信息,跟我前面那个小程序返回的结果一模一样,你也可以尝试一下。
而如果我指定–net=host,就意味着这个容器不会为进程启用 Network Namespace。这就意味着,这个容器拆除了 Network Namespace 的“隔离墙”,所以,它会和宿主机上的其他普通进程一样,直接共享宿主机的网络栈。这就为容器直接操作和使用宿主机网络提供了一个渠道。