概要描述
ZAB 协议的全称是 Zookeeper Atomic Broadcase,原子广播协议。
ZAB是为了保证Zookeeper数据一致性而产生的算法(指的是Zookeeper集群模式)。它不仅能解决正常情况下的数据一致性问题,还可以保证主节点发生宕机后的数据一致性问题。
通过这个 ZAB 协议可以进行集群间主备节点的数据同步,保证数据的一致性。
详细说明
在讲解 ZAB 协议之前,我们必须要了解 Zookeeper 的各节点的角色。
1.Zookeeper 各节点的角色
Leader
负责处理客户端发送的读、写事务请求
。这里的事务请求可以理解这个请求具有事务的 ACID 特性。
同步写事务请求
给其他节点,且需要保证事务的顺序性。
状态为 LEADING。
Follower
负责处理客户端发送的读请求
转发写事务请求给 Leader。
参与 Leader 的选举。
状态为 FOLLOWING。
FOLLOWING 已经存在leader,当前服务器为跟随者
Observer
和 Follower 一样,唯一不同的是,不参与 Leader 的选举,且状态为 OBSERING。
除非zookeeper集群很大,否则一般没有observer
还有一个特殊状态LOOKING :当前集群没有leader,准备选举
2.投票的依据
投票的依据就是下面的两个id,投票即是给所有服务器发送 (myid,zxid) 信息。
myid:用户在配置文件中自己配置,每个节点都要配置的一个唯一值,从1开始往后累加。



zxid:zxid有64位,分成两部分:
高32位是Leader的epoch:选举时钟,每次选出新的Leader,epoch累加1
低32位是在这轮epoch内的事务id:对于用户的每一次更新操作集群都会累加1。
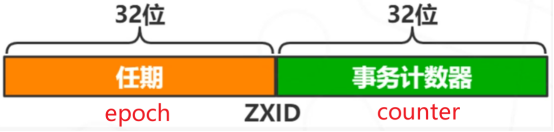
选举优先级:>选举优先级: epoch > counter > myid
Zxid查看方法:echo twzkstat | nc IP 2181
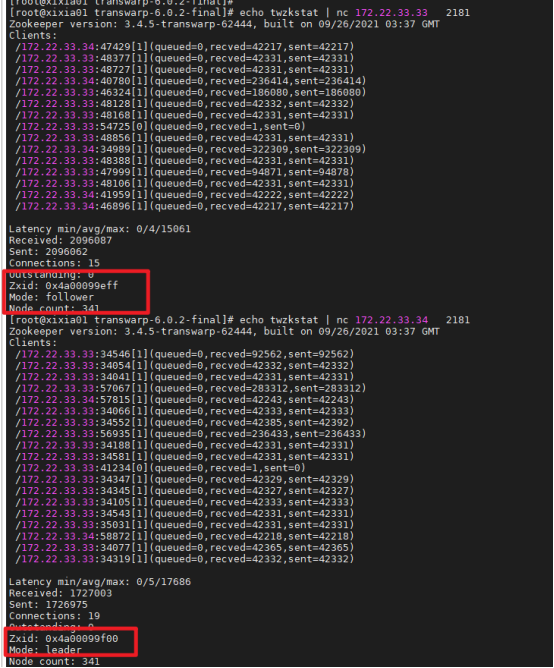
Zxid(Transaction id)类似于 RDBMS 中的事务 ID,用于标识一次更新操作的 Proposal(提议)ID。为了保证顺序性,该 zkid 必须单调递增。
注意:zk把epoch和事务id合在一起,每次epoch变化,都将低32位的序号重置,这样做是为了方便对比出最新的数据,保证了zxid的全局递增性
3.关于选举轮次
由于所有有效的投票都必须在同一轮次中。每开始新一轮投票自身的logicClock自增1。
接收到的logicClock大于自己的。说明自己落后了,更新logicClock后正常。 接收到的logicClock小于自己的。忽略该票。 接收到的logickClock与自己的相等,正常判断。
4.关于选票判断
对比自身的和接收到的(myid,zxid)
首先对比zxid高32位的选举时钟epoch 一致则对比zxid低32的事务id 仍然一致则对比用户自己配置的myid
选完后广播选出的(myid,zxid)
5.关于选举结束
过半服务器选了同一个,则投票结束,根据投票结果更新自身状态为leader或者follower