概要描述
hdfs 作为 hyperbase、inceptor 的文件存储系统,当出现 hyperbase、inceptor 读写慢的情况时,需要考虑 hdfs 的读写性能是否出现问题,本文主要介绍 HDFS 的读写性能排查思路。
详细说明
- 日志关键字
- 网络监控
- 磁盘io
网络监控
日志关键字
hdfs 性能日志
使用 egrep 过滤 Slow 关键词,并统计每种情况的具体数量:
egrep -o "Slow.*?(took|cost)" hadoop-hdfs-datanode*.log | sort | uniq -c

总结一下几种情况:
| 日志 | 原因 |
|---|---|
| Slow BlockReceiver write packet to mirror | 这表明在网络上写入块时有延迟 |
| Slow BlockReceiver write data to disk cost | 这表示在将块写入OS缓存或磁盘时存在延迟 |
| Slow flushOrSync | 这表示在将块写入OS缓存或磁盘时存在延迟 |
| Slow manageWriterOsCache | 这表示在将块写入OS缓存或磁盘时存在延迟 |
需要注意的时,这些日志信息在正常集群上也有可能出现;只有当这些错误信息异常多,或者单节点个别时间段内数量异常多,或者多节点对比发现个别节点数量异常时,才算是异常情况;
当单个节点具有比正常情况更多的上述WARN消息时,表明存在底层硬件问题。然后结合dmesg -T | grep -i error 查看硬件信息确定是否存在硬件故障。
错误日志
检查hdfs datanode运行日志,搜索关键词:IOException、error、fatal等。
| 日志 | 原因 |
|---|---|
| IOExceptionxceiver count 4097 exceeds the limit of concurrent xcievers hdfs datanode | 文件读写线程数不够,集群并发读写高,任务批处理多。 |
| java.net.SocketTimeoutException Read timed out | 客户端操作datanode socket 超时,可能是线程数不够,或者内存GC不够 |
1、脚本 nettyThroughputCheck.sh
/usr/lib/inspection/bin/nettyThroughputCheck.sh
脚本使用说明:
1.1 前置文件: /usr/lib/inspection/lib/inspectionAgent-x.x.x.jar
需要再每个服务器上创建 /usr/lib/inspection/lib/ 给普通权限即可
每个节点 /usr/lib/inspection/lib/ 放置 inspectionAgent-*.jar
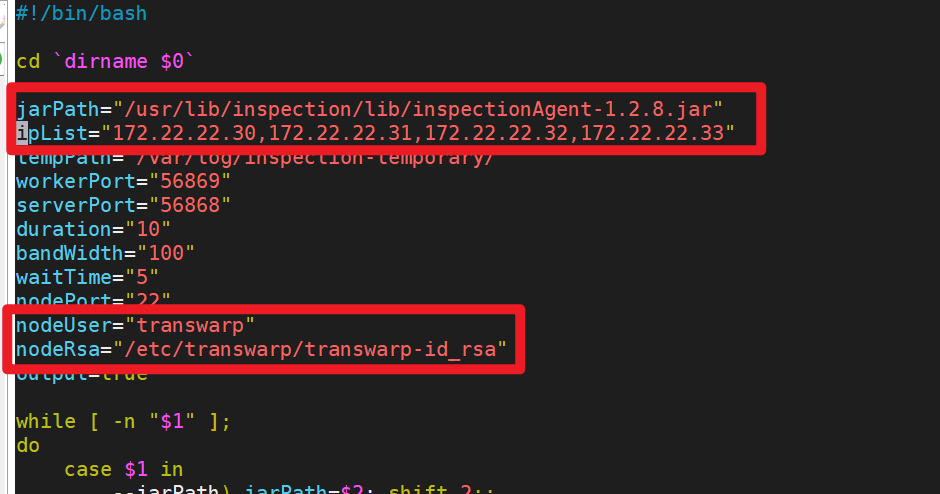
1.2 配置:
将脚本 nettyThroughputCheck.sh 中的 inspectionAgent-x.x.x.jar 修改为现有版本;
- ipList:必须至少包含集群一个非 Manager 节点;
- nodeUser:使用巡检工具平时巡检的用户
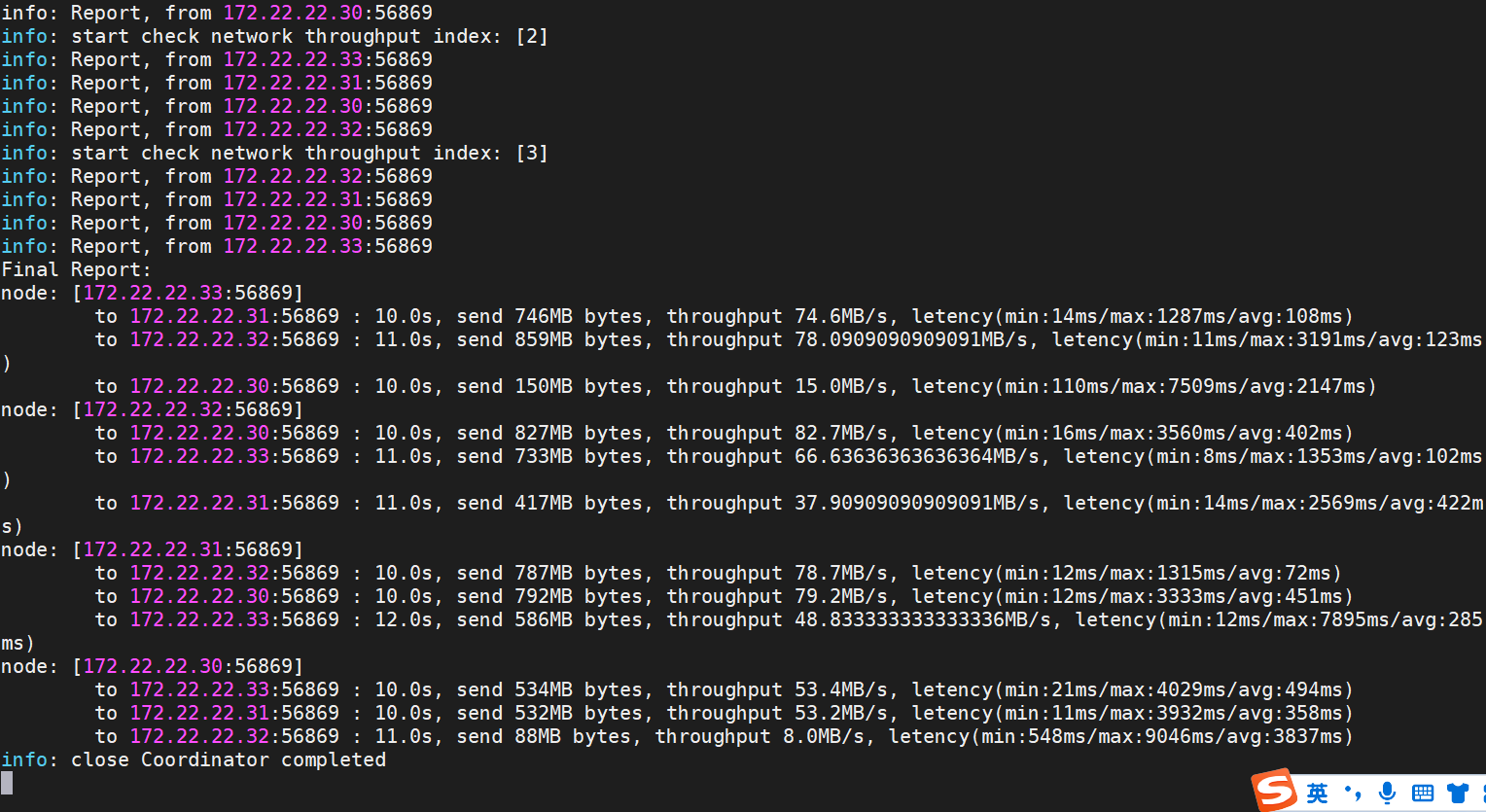
1.3 执行网络巡检
sudo sh -x /usr/lib/inspection/bin/nettyThroughputCheck.sh
默认结果中接近100MB/s ,网络即为无问题
PS:脚本使用前置条件比较复杂,可以考虑改造一下脚本,使用 transwarp 的密钥cp 文件:
ssh -p $nodePort -o StrictHostKeyChecking=no -i $nodeRsa $nodeUser@$ip sudo mkdir -p /usr/lib/inspection/lib/
scp -i $nodeRsa -r $jarPath $nodeUser@$ip:/tmp/
ssh -p $nodePort -o StrictHostKeyChecking=no -i $nodeRsa $nodeUser@$ip sudo mv /tmp/inspectionAgent-1.2.8.jar /usr/lib/inspection/lib/磁盘 io
iostat -xmd 2 10
%util: 采用周期内用于IO操作的时间比率,即一秒中有百分之多少的时间用于 I/O;
如果%util接近100%,说明产生的I/O请求太多,I/O系统已经满负荷;
确认磁盘 io 使用率接近 100% 时,则查看具体占用 io 的进程信息:
pidstat -dl -T ALL 3
查看具体占用磁盘 io 的进程是哪些;