内容纲要
概要描述
本文主要介绍如何通过收集表的列统计信息,对TAB_COL_STATS的结果进行分析。
详细说明
首先我们创建样例表,并插入数据 (建表语句和插入语句见结尾内容),数据如下
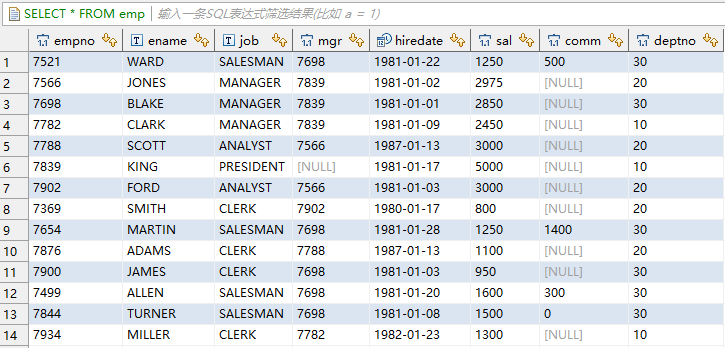
执行analyze命令,对表的列信息进行统计收集
> ANALYZE TABLE default.emp COMPUTE STATISTICS FOR COLUMNS;收集到的统计信息,需要到元数据库(txsql/kundb)进行查看:
> SELECT * FROM TAB_COL_STATS WHERE DB_NAME='default' and TABLE_NAME='emp' order by cs_id asc;下面是TAB_COL_STATS表的列信息说明
| 列名 | 列说明 |
|---|---|
| cs_id | id |
| db_name | 库名 |
| table_name | 表名 |
| column_name | 列名 |
| column_type | 列类型 |
| tbl_id | 表id |
| long_low_value | 整数列存储整数最小值 |
| long_high_value | 整数列存储整数最大值 |
| double_high_value | float列存储float最小值 |
| double_low_value | float列存储float最大值 |
| big_decimal_low_value | decimal列存储decimal最小值 |
| big_decimal_high_value | decimal列存储decimal最大值 |
| num_nulls | null的数目 |
| num_distincts | distinct值的数目 |
| avg_col_len | string列的平均列长度 |
| max_col_len | string列的最大列长度 |
| num_trues | boolean列true的数目 |
| num_falses | boolean列false的数目 |
| last_analyzed | 最后统计时间 |
比如:
我想知道emp员工表里面,员工的最高薪资和最低薪资是多少?
sal字段是int类型,可以参考long_low_value和long_high_value字段获取到最小值和最大值。。
我想知道emp员工表里面,没有comm奖金的人数?
- 可以参考
NUM_NULLS字段获取到sal列为null的数量。
我想知道emp员工表里面,哪一列数据重复值较多?
- 可以参考
num_distincts字段获取到distinct值的数目,值越大,代表重复率越低;反之越高。
我想知道emp员工表里面,列长度的最大值和平均值?
- 注意,
avg_col_len和max_col_len列仅对string类型的列有效。
还有很多其他重要的统计信息可以供分析,待大家深入挖掘其中的用法。