概要描述
Checkpoint机制是用户保证Job HA的一个手段,Slipstream可以通过定期触发任务检查点(Checkpoint),将对应时刻的任务状态持久化到分布式存储上来保证系统崩溃下计算的一致性,以此来实现流任务的高可用。
详细说明
开启Checkpoint示例
DROP STREAMJOB xlstreamjob;
CREATE STREAMJOB xlstreamjob AS("insert into xl select * from demoxxll")
jobproperties(
"morphling.result.auto.flush"="true",--自动Sink,只要有数据产生就立刻flush到目标表
"morphling.job.enable.auto.failover"="true",--是否开启失败任务自动恢复
"morphling.task.max.failures"="5",--任务失败重试次数
"morphling.job.enable.checkpoint"="true",--任务启用HA
"morphling.job.checkpoint.interval"="60000"--Checkpoint的频率。单位:毫秒
);Checkpoint 原理介绍
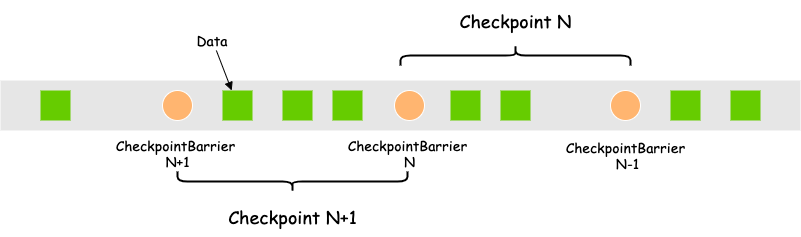
当任务开启Checkpoint时,有一个Checkpoint管理者:CheckpointCoordinator会根据设置的Checkpoint Interval来定期生成CheckpointBarrier,并将该CheckpointBarrier注入到流中,随数据一起经过各个Operator处理。
数据流转如上图所示:
CheckpointBarrier(N-1,N) 之间的状态会保存为Checkpoint N,CheckpointBarrier(N,N+1) 之间的状态会保存为Checkpoint N+1。若当CheckpointBarrier N+1还未处理完任务就失败了,则任务会从Checkpoint N恢复,重新拉取CheckpointBarrier N与N+1之间的数据进行计算。
这种异步注入的方式不会阻塞数据的处理,不打乱数据的顺序。
两种语义
在流任务高可用中,存在两种语义:At-Least-Once 和 Exactly-Once。
状态 Exactly-Once
Slipstream天然支持状态Exactly-Once,即每条数据在一个Operator里只会被计算一次,比如在word count场景,一个时间窗口内,无论任务重启几次,同一条记录不会被计数两次。
端到端 At-Least-Once
端到端At-Least-Once即至少输出一次,确保数据不丢失,但会存在输出重复的情况。
任务重启,会从上一个checkpoint恢复。虽然计算结果是一致的,但是结果可能会被重复输出。
如果当输出存储支持幂等操作(比如hbase相同key值的记录会覆盖),则效果与Exactly-Once相同。

端到端 Exactly-Once
端到端 Exactly-Once对输出来说,一次计算结果只会存一份,不会有重复数据。
端到端Exactly-Once依靠两阶段提交来确保checkpoint完成,数据才对外可见,需要下游存储提供事务功能来支持。
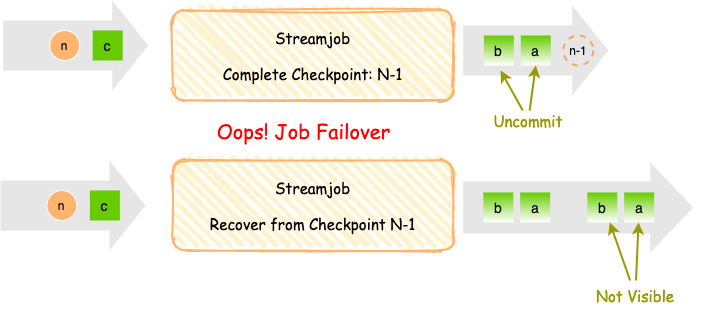
流任务场景中常用Kafka作为结果输出,如果想要支持端到端Exactly-Once,需要开启Kafka事务,每一次Checkpoint时都会产生一个对应的事务ID,只有当Checkpoint完成时,才提交对应事务,该事务对应的数据对下游可见。
注: 下游消费对应的topic时,也需要开启参数,只消费已提交事务的数据。
因为两阶段提交需要等checkpoint完成,期间数据才可见,所以会有一个checkpoint interval的延时。
开启Checkpoint时,Kafka Consumer的偏移量重置策略
启动流任务时,从kafka中读取record起始offset策略。若无checkpoint,或checkpoint中无偏移量,则使用策略。
重置策略:
-
若任务没有开启checkpoint
- 没有设置 transwarp.consumer.reset.offset.strategy 情况下,offset以kafka默认方式,最新或者上一次commit的位置开始消费
- 若设置了 transwarp.consumer.reset.offset.strategy 则根据表1中的操作进行offset重置
-
若任务开启了checkpoint
- 如果第一次执行,或者新增了kafka partition,offset重置方式同“没有开启checkpoint”相同
- 如果任务已经存在checkpoint数据,offset重置从checkpoint中获取,transwarp.consumer.reset.offset.strategy 这个参数无效
Checkpoint 不同模式
Standalone(8.0开始已不支持)
该模式下,Task状态数据写入HDFS,并将对应元信息汇报给Server。Server接收Checkpoint元信息,并将其保存在内存中。所以如果当Server异常退出或重启,对应的元数据会丢失,实用性不强。所以该模式在TDH 8.0后将不再支持。
Zookeeper
从TDH 6.2.2开始,默认开启Zookeeper模式。
该模式与Standalone模式相同的是,Task状态数据会写入HDFS。
不同之处在于,Checkpoint元数据会写入zookeeper。所以当Server重启也不影响这部分数据的存储,任务依然可以从上一次退出时的状态开始计算。
Kafka
从TDH 8.0开始,Slipstream增加了Kafka模式。
Zookeeper模式虽然稳定,但是存在两个问题:
-
当状态不大的情况下,写HDFS会出现小文件问题,若Checkpoint Interval较小,Task数量较多,会给HDFS带来压力。
-
Executor需要将元信息通过Akka通信汇报给Server,当Task较多,Checkpoint频率较高的情况下会给Server带来压力。
Kafka模式下,Task状态数据会写入Kafka对应的Topic中,Server会消费该topic来确认Checkpoint是否完成,并将元信息再写入另一个Topic中。该方式解耦了Executor与Server之间的Akka通信,并且借助Kafka的高吞吐能力,轻松应对Checkpoint频繁且Task较多的场景。
使用时,任务在开启Checkpoint时默认选择Zookeeper模式,如果要选择Kafka模式需要在任务参数中添加morphling.checkpoint.backend=kafka来指定。
引擎支持同时运行Zookeeper模式的任务和Kafka模式的任务。
Checkpoint 的参数配置
引擎级别(server)参数
| 名称 | 描述 | 取值 |
|---|---|---|
| spark.morphling.recovery.mode | 采用的HA模式。如果需要支持Exactly Once,则应将此设置配置为Zookeeper。 | zookeeper |
| spark.morphling.taskstate.backend | Task状态信息的存储系统,当前只支持filesystem,即存放在文件系统。 | filesystem |
| spark.morphling.taskstate.checkpoint.directory | Morphling Task保存状态信息的checkpoints的地址。通常建议放在分布式文件系统,以保证不同的Executor都能访问。 | hdfs://xxx/checkpoints |
| spark.morphling.completed.checkpoints.storage.dir | spark.morphling.recovery.mode=zookeeper时需配置,用于配置Morphling Driver端保存任务状态的checkpoints地址。 | /morphling/completedcheckpoints |
| spark.morphling.zookeeper.quorum | Zookeeper的quorum。 | localhost:2181 |
| spark.morphling.zookeeper.root.path | Zookeeper存放状态信息的根节点。 | /morphling |
| spark.morphling.zookeeper.namespace | Zookeeper上存储信息的命名空间,用于区分多集群的环境,一般可以采用集群名,如slipstream1。 | /default |
| spark.morphling.zookeeper.checkpoints.path | Zookeeper存储checkpoint元信息的目录。 | /checkpoints |
| spark.morphling.submitted.job.path | Zookeeper存储当前提交的流任务信息的目录。 | /runningjobs |
任务级别(job)参数
| 名称 | 描述 | 取值 |
|---|---|---|
| morphling.task.max.failures | 任务失败重试次数,-1表示不进行重试恢复。 | -1/自定义 |
| morphling.job.enable.checkpoint | 决定该任务是否启用HA。 | true/false |
| morphling.job.checkpoint.interval | Checkpoint的频率。单位:毫秒。 | 60000/自定义 |
| morphling.job.enable.auto.failover | 是否允许失败任务自动恢复,配合morphling.task.max.failues使用。 | true/false |
Checkpoint 注意事项
Checkpoint Interval 大小设置
为了尽量减小Checkpoint对吞吐的影响,建议Checkpoint Interval大小设置分钟级别。
如果使用Zookeeper模式,推荐10分钟及以上;
如果使用Kafka模式,可以支持1分钟一次的频率。
Checkpoint Expire
每个Checkpoint都设有过期时间(默认1分钟),当1分钟之内仍然没有确认所有的task都完成该Checkpoint的状态存储工作,则Server判断该Checkpoint过期。
从Server日志里就可以看到 Checkpoint[179] of job {default.ha_etl_job} expired before completing 的信息。
Checkpoint为什么会过期?
当数据处理时间太久、Task状态存储处理太久、checkpoint处理完成确认消息没有及时处理都会导致Checkpoint过期。
原因可能是数据量有波动、GC、网络抖动,因为一个Checkpoint过期,不会阻塞下一个Checkpoint的处理,这种情况一般会自行恢复。
若频繁Expire或者一直Expire,则需要引起重视,需要检查服务是否异常、Checkpoint是否太频繁。
为什么要设置过期时间?
在TDH7.0之前,CheckpointCoordinator会根据checkpoint interval定期产生checkpoint,若不设置过期时间,则会导致Server端保存的Checkpoint积压过多。
TDH7.0之后,CheckpointCoordinator增加了自适应功能,当Checkpoint有积压的时候,会暂停继续生成checkpoint,直到前面的checkpoint都被正确处理或过期抛弃,不会长期阻塞在一个checkpoint里。
Checkpoint过期会带来什么影响?
若Checkpoint被Server认为过期,则Sever不会再处理Task发送的迟到的处理信息。若此时任务重启,则从上一个checkpoint开始恢复;
开启Checkpoint时,Kafka consumer group对应Offset管理
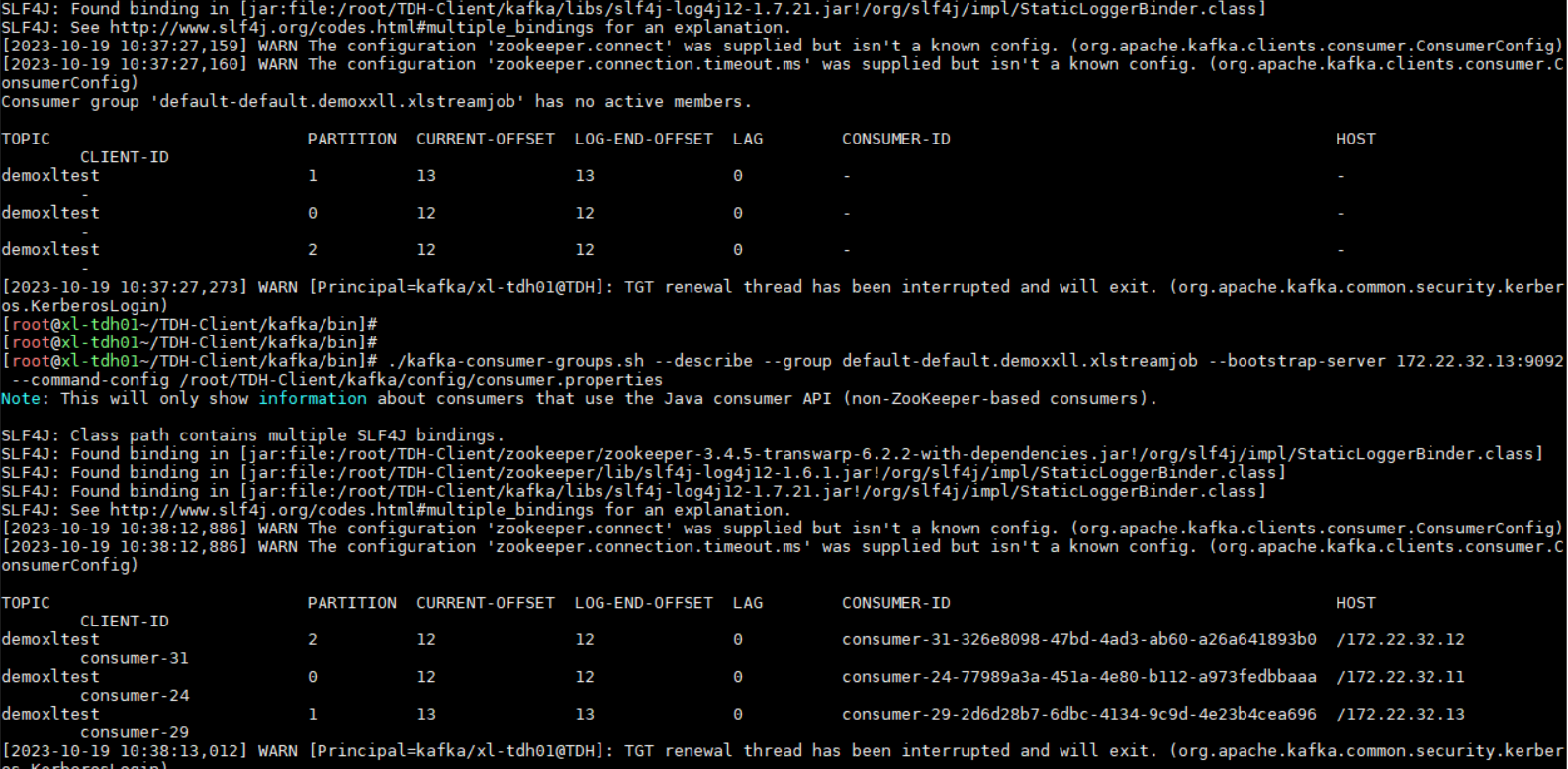
当开启Checkpoint时,Offset由引擎托管,构建KafkaConsumer时,设置auto.offset.commit为false。若引擎不提交offset到Kafka,用kafka-consumer-groups.sh list 结果找不到需要的consumer group。
并且describe group时,对应的topic也不会显示有对应client id。
因为引擎内部会定期提交Offset到Kafka,所以过一段时间describe结果可以看到对应的consumer group的offset变化,但这个offset消费情况会比实际消费的要迟滞上一段时间。
开启checkpoint 机制的情况下,是看不到对应的client id,如图,开启前后的消费组describe结果对比:
清理Checkpoint
每个任务只会保留最近的5个Checkpoint,更早的Checkpoint会被定时清理以保证Checkpoint数据不会占用太多空间。
如果要彻底清理一个任务的Checkpoint数据有两种方法:
-
执行drop streamjob job名,会删除Zookeeper及HDFS上的Checkpoint文件(推荐)
-
手动到Zookeeper和HDFS路径下删除对应文件。
Checkpoint恢复异常
如果当计算逻辑有更改,尤其是涉及有状态的计算,比如window、CEP,则原来的checkpoint则不再生效,需要清除原来的checkpoint。