概要描述
使用holodesk on shiva能够实现基于闪存的列式存储格式,可以获得优秀的分析性能;同时也支持多种辅助索引技术,极大地增强了数据的检索性能,能更好地适配混合型的业务场景。
本案例简单介绍holodesk on shiva的安装和配置方法,以及使用过程中的注意事项;
本案例环境:TDH 5.2.2、inceptor 5.2.2
详细说明
holodesk on zookeeper存在一系列的问题,包括但不限于以下几种;对holodesk表执行select、drop、truncate等操作时,在waterdrop或者日志中发现以下报错:
EXECUTION FAILED: Task MAPRED-SPARK error EOFException: [Error 1] java.io.EOFExceptionSQL 错误[10] [42000]: FAILED: Error in handle statement start: Shiva is not initialized操作步骤
- 规划并安装Shiva
- 更新依赖关系并增加参数配置
规划Shiva的角色
本节介绍通过Transwarp Manager部署Shiva集群,关于Shiva的角色规划可以参考官网的手册:
链接如下:
https://www.warpcloud.cn/#/documents-support/docs/products?category=ARGODB
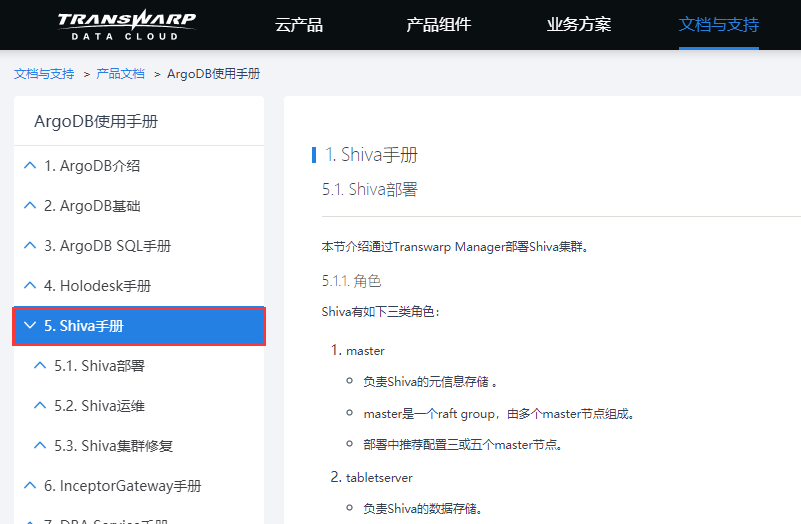
其中需要注意的是:
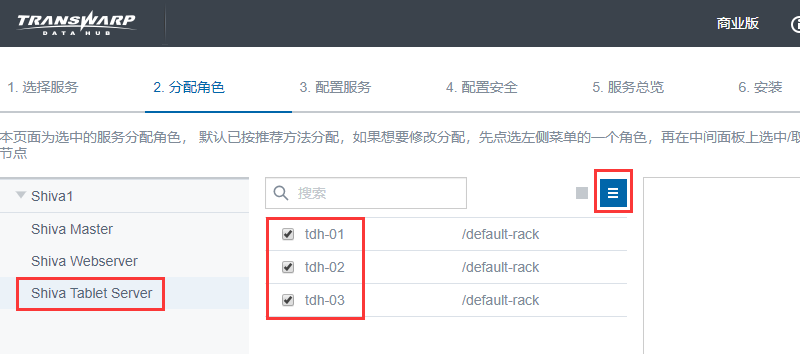
必须保证“每个inceptor的executor所在的机器上必须要安装tabletserver”, 否则不能使用。在安装inceptor和shiva的服务时,必须要满足这个条件。
因为inceptor的executor在tdh-01、tdh-02、tdh-03上均有安装,所以这里的tabletserver必须三个节点都安装:
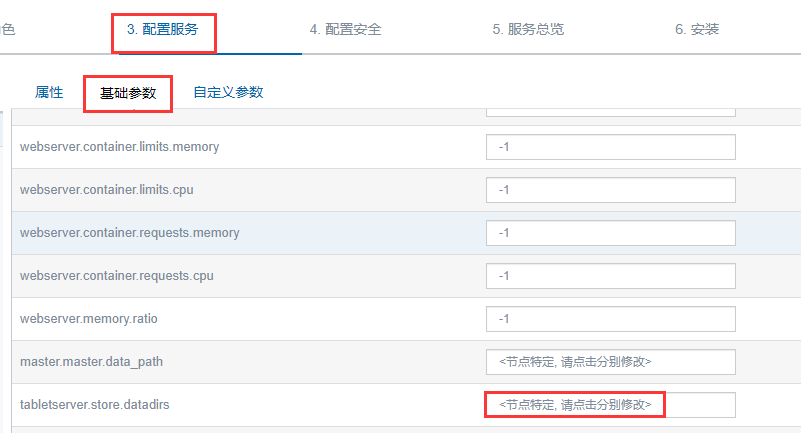
在配置服务的基础参数页面需要添加**tabletserver.store.datadirs**参数的默认值,指定数据路径(建议是指定多个ssd盘对应的路径):
更新依赖关系并增加参数配置
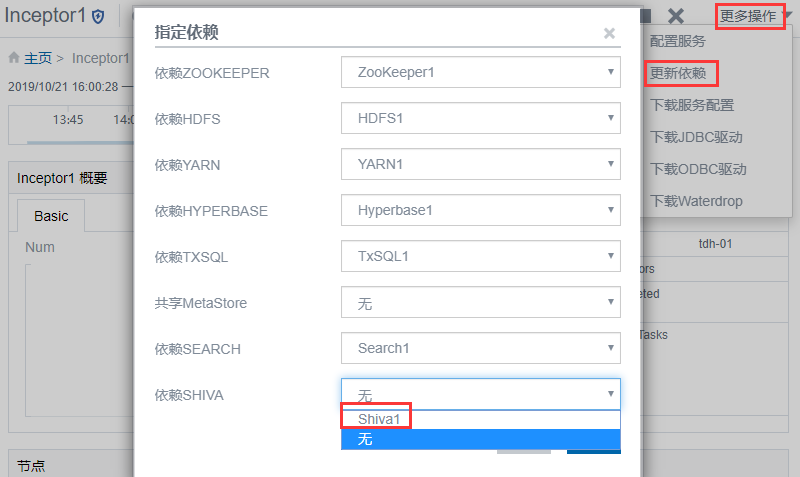
manager页面上点击inceptor服务,进入inceptor的更多操作,更新依赖,选择shiva的依赖:
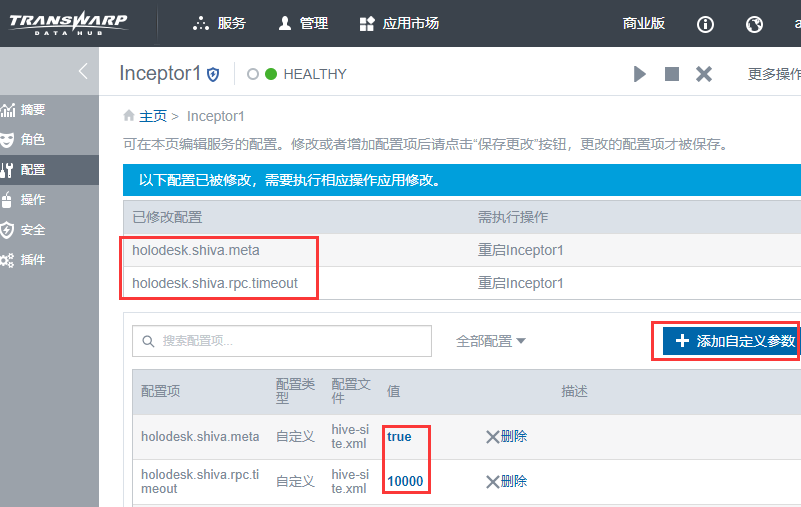
manager页面上点击inceptor服务,进入inceptor的配置页面,添加自定义参数,增加两个参数:
属性:holodesk.shiva.meta (这个参数用以控制holodesk on shiva的开关)
值:true,
配置文件:hive-site.xml
属性:holodesk.shiva.rpc.timeout
值:10000
配置文件:hive-site.xml
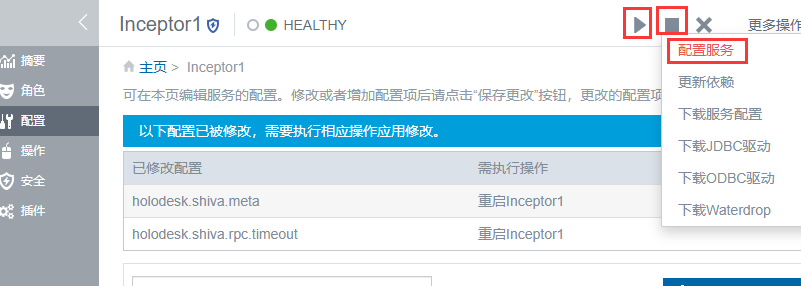
然后配置服务,重启inceptor;
创建holodesk表,以及注意事项
新增加了如下几个参数:
holodesk.shiva.replicate.num, 默认为3,用以控制holodesk的文件在shiva中的副本数,默认3副本
holodesk.shiva.tablet.num, 默认为20,根据表的大小(GB)来控制,推荐设置方法: 一个tablet对应50GB数据,假设一张表有1T,需要将其设置为20
holodesk.shiva.capacity.unit, 默认为100, 根据表的大小(GB)来控制,推荐设置方法: 设置capacity与表总大小(GB)数值一样
后面三个参数是跟表属性相关的,推荐建表时在tblproperties里面设定,如果不设置,将采用默认值,建表方式如下:
-
CREATE TABLE holo_test( id string DEFAULT ' ' , newscode varchar(200) DEFAULT '' , fileextname varchar(200) DEFAULT '' , publishtime date DEFAULT '' , entrytime string DEFAULT '' ) CLUSTERED BY(newscode) INTO 3 buckets STORED AS HOLODESK TBLPROPERTIES ( "holodesk.shiva.tablet.num"="5", "holodesk.shiva.capacity.unit"="5", "holodesk.shiva.replicate.num"="3", 'holodesk.index' = 'newscode,publishtime' );