内容纲要
概要描述
本文描述在某些现场 slipstream1 不共享 inceptor 的 metastore 的时候,manager 出现健康检查错误,导致页面上角色状态显示不正常的解决方案
详细描述
问题描述
当集群部署了多个 Inceptor/Slipstream 服务,且都有独立的 metastore 时,会出现状态显示异常的问题;
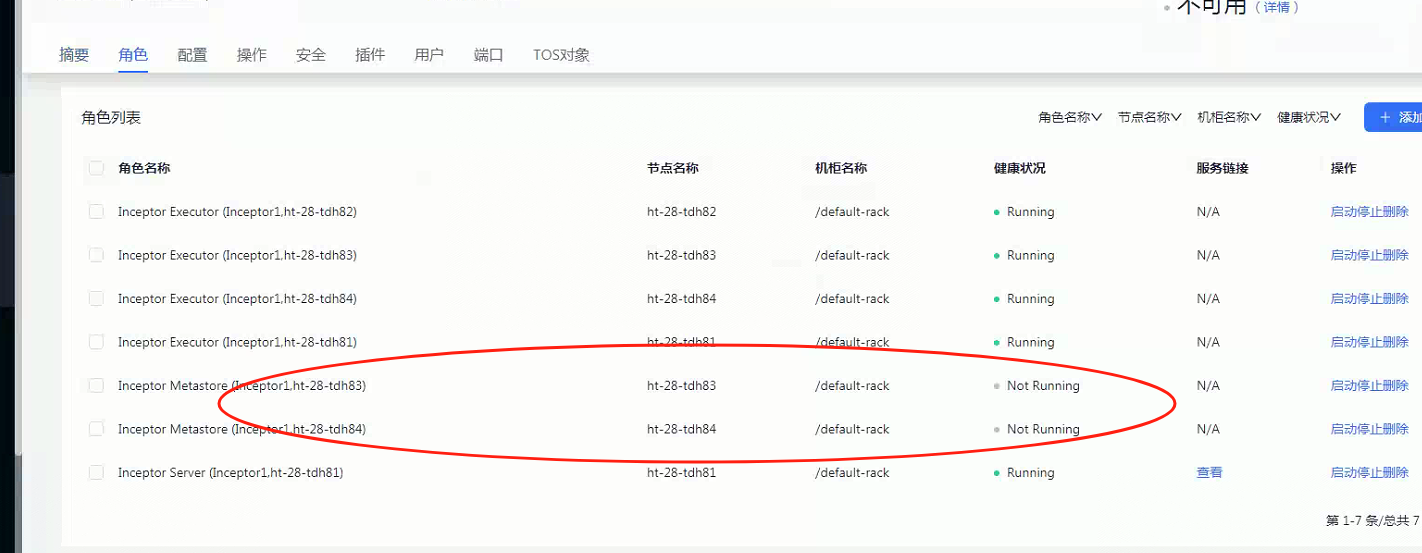
inceptor1的metatore在slipstream服务的独立metastore部署后,单独启动后显示异常

查看 manager 的 health-check 日志,日志里面报错如下
Fail to get default database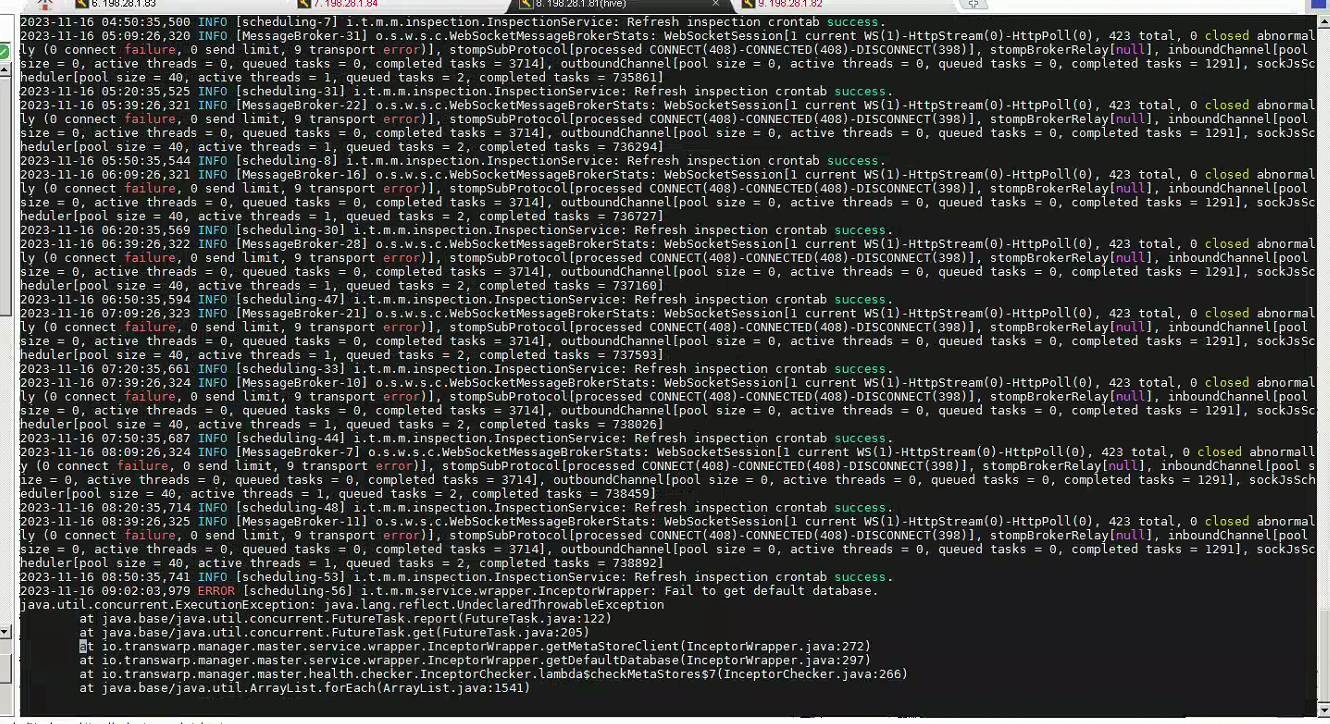
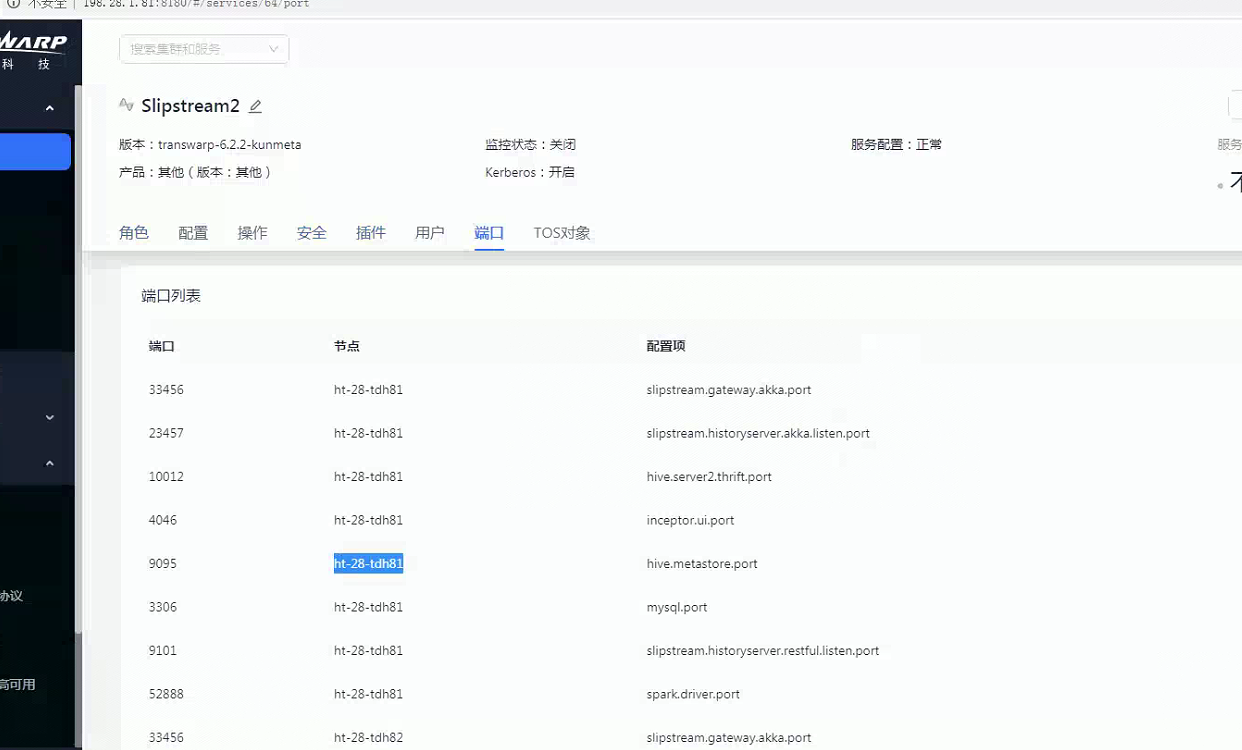
且日志检查的链接信息,非inceptor1的链接信息

对比了一下这个链接信息是slipstream的metastore的链接信息
root cause
当同一个节点存在多个服务的不同 metastore 角色时,Manager健康检查规则的原因
解决方案
方案一. 删除 VITAL_SIGN_CHECK 检查
当有这种 多个 Inceptor/Slipstream 服务,且都有独立的 metastore 的情况时,需要关闭 VITAL_SIGN_CHECK 检查;
具体操作方法如下:登录manager服务器
cd /var/lib/transwarp-manager/master/content/meta/services/INCEPTOR/[版本]/
# 备份 metainfo
cp metainfo.yaml metainfo.yaml.init
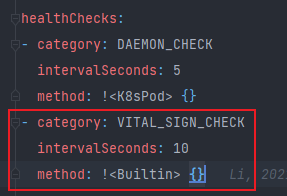
# 编辑 metainfo ,删除 VITAL_SIGN_CHECK
vi metainfo.yaml去掉红框部分,保存
重启manager服务
systemctl restart transwarp-manager方案二. 修改VITAL_SIGN_CHECK为Probe方式
默认的 基于Builtin的健康检查,内嵌式服务健康检查 是写在代码里面的,无法修改,可调整为 基于Probe的健康检查
最基础的下面这种,检测pod 的ready状态。
healthChecks:
- category: DAEMON_CHECK
intervalSeconds: 5
method: ! {}
- category: VITAL_SIGN_CHECK
intervalSeconds: 15
method: !
roles:
- roleType: INCEPTOR
from: ! {} 重启manager服务
systemctl restart transwarp-manager