概要描述
CSV表的数据来源是CSV文件。CSV文件是纯文本文件,文件中包含数据以及分隔符。和TEXT表相似,CSV表最常见的使用场景是用于建外表,将CSV文件中的数据导入ArgoDB。在过去,CSV格式不支持在Map阶段对大文件进行切割,倘若CSV单文件超过1G,只能使用txt格式加以处理。在新版本中,引入了一些新功能可以提升csv建外表的性能。
本文主要介绍一些加速读取csv文件的方法可供参考。
详细说明
我们简单还原下问题现象,通过yes '"1","zhangsan","18"' | head -n 25000000 > output.csv 构造一个477m的csvfile文件,通过hdfs命令put到/tmp/0619目录下,供下面的csvfile外表读取。
CREATE external TABLE csvtest01(
id INT ,name STRING,age INT)
STORED AS CSVFILE
LOCATION '/tmp/0619'
TBLPROPERTIES(
'field.delim'=',',
'quote.delim'='"',
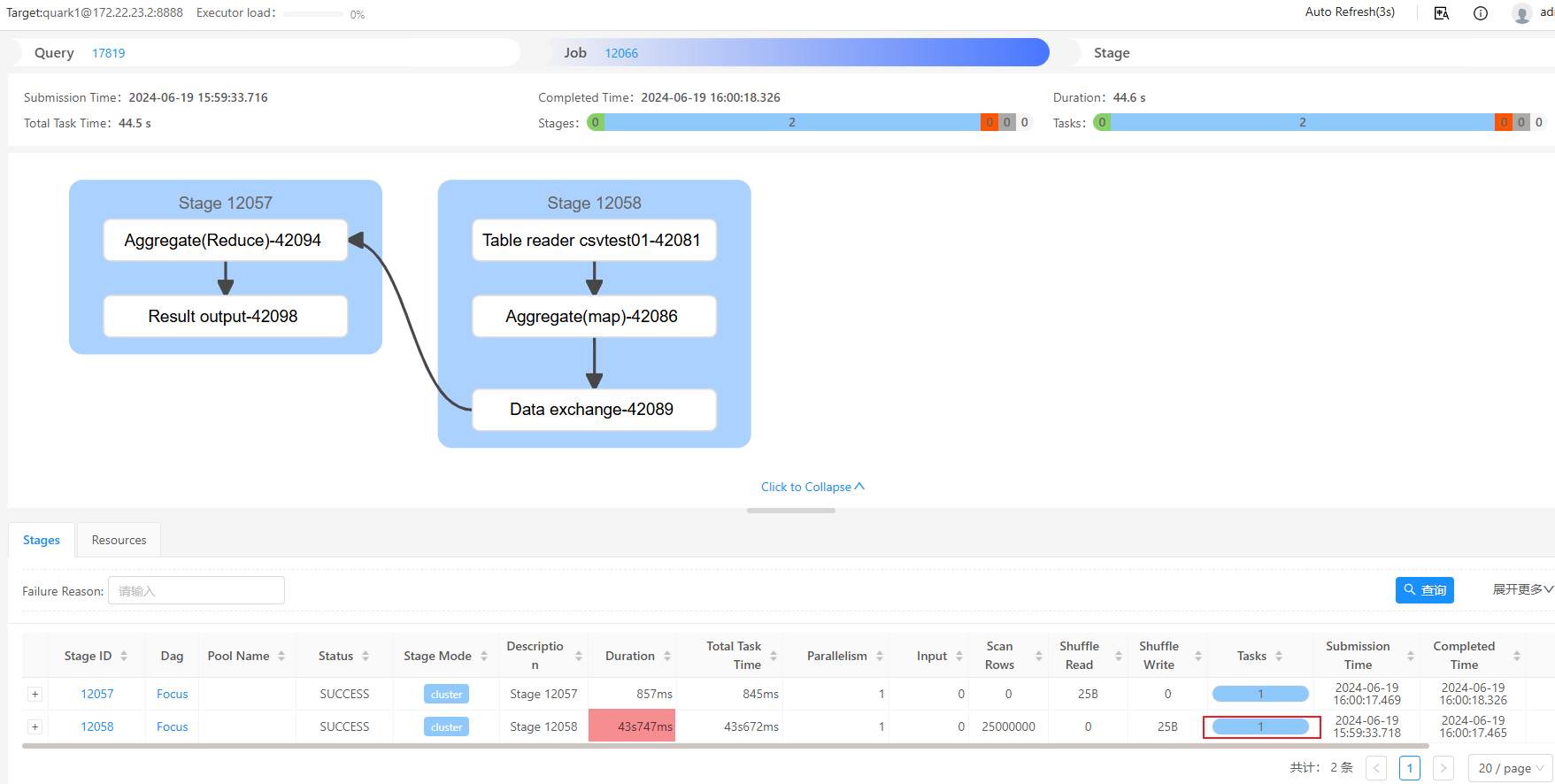
'line.delim'='\n') ;执行 select count(*) from csvtest01 查询,观察DBAService的map阶段可以看到只起了1个task,执行时长43s
方案一. 使用TextInputFormat的输入格式
优先推荐该方案!注意这里并不是简单的stored as textfile哦~
DROP TABLE IF EXISTS csv_test;
create external table csv_test(
id INT ,
name STRING,
age INT
)ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.csv.serde.CSVSerde'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location "/tmp/0619";执行 select count(*) from csv_test 查询,观察DBAService的map阶段可以看到只起了4个task,执行时长14s
TextInputFormat和TextOutputFormat指文件被创建为一个text表,该参数与普通的text表是相同的。而CSVSerDe则指定了一种序列化(Serializer)和反序列化的方式(Deserializer)。此时,表格仍然能够以csv的样式被正确读出,倘若创建普通的text表则无法读出。在如此创建表格时,仍然可以通过在tblproperties中指定field.delim、quote.delim和line.delim这三个参数。
SERDE是"Serializer/Deserializer"的缩写,用于指定如何序列化和反序列化Hive表中的数据。在这个例子中,使用了org.apache.hadoop.hive.ql.io.csv.serde.CSVSerde,这是Quark提供的一个用于处理CSV文件的SerDe。
INPUTFORMAT和OUTPUTFORMAT指定了Quark在读取和写入表数据时应使用的Hadoop输入和输出格式。
INPUTFORMAT ‘org.apache.hadoop.mapred.TextInputFormat’: 指定Hive在读取数据时应该使用Hadoop的TextInputFormat。这是Hadoop默认的文件读取格式,用于读取文本文件。
OUTPUTFORMAT ‘org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat’: 当Quark需要写入数据时(尽管在这个外部表的定义中,它实际上不会直接写入数据,因为这是一个外部表),它会使用HiveIgnoreKeyTextOutputFormat。这个OutputFormat是Quark特有的,用于写入文本文件,但忽略键(key)部分(在MapReduce中,通常会有键和值两部分)。
方案二. csv切分功能
该功能需要argodb5.x以上版本才能够支持,使用起来有一定限制,读取后需校验数据一致性!
一种方式是直接设置参数 (推荐),
set hive.conf.validation=false;
set inceptor.conf.validation=false;
set reserve.first.row=true; --是否保留首行,true为保留
set csv_one_file_per_map=false; --经测试,该参数起作用,可灵活配置
set csv_block_len_mb_per_map=128; --每128MB起一个map task (经测试,该参数起作用,默认取128m blocksize的大小)
--再直接查询csvfile表
select count(*) from csv_test;另外一种方式是写到csvfile的tblproperties里面去
DROP TABLE IF EXISTS csv_mapsplit;
create external table csv_mapsplit
(id INT ,name STRING,age INT)
stored as csvfile
location "/tmp/0619"
tblproperties(
"reserve.first.row"="true", --是否保留首行
"csv_one_file_per_map"="false", --是否每个文件单map task处理
"csv_block_len_mb_per_map"="128", --每128MB起一个map task (经测试,该参数不起作用,默认取128m blocksize的大小)
'mapreduce.csvinput.encoding'='gbk', --指定使用gbk编码读取数据。与text表参数不同
'field.delim'=',', --字段分隔符,属性的值指定字段分隔符,默认值为 “,”
'quote.delim'='"', --属性的值指定用什么字符作为单个字段的分隔符,默认值为“"”。
'line.delim'='\n' --属性的值指定行分隔符,默认值为“\n”。
);执行 select count(*) from csv_mapsplit 查询,观察DBAService的map阶段可以看到只起了4个task,执行时长14s
注意:
- 导入不带头部的csv存在问题,如果数据源没有csv头,请使用txt格式导入
- 若CSV外表是用的压缩后的CSV建的,则会自动退化成单文件单map,不会启用block split优化
- 用户必须自行保证csv数据中,record内部不能有lineSeparator,即使是quote中也不行;否则可能导致数据解析错误(并且无法报错)——最好仅在POC中/数据情况完全掌握的情况下使用本优化
方案三. shell切分csv文件分批读取
一般不会考虑这个方案,仅供参考
以一个10T的文件为例:
a) 将1T文件解压成10T
b) 通过split -b 209715200 -d ../aaaa.csv outf -a 5,10T/200m ~ 52428.8,猜测会切分成5w+个数据文件,文件名应该是outf00000~outf52429
c) 创建6个hdfs目录,
for i in {00..05}; do hadoop fs -mkdir -p /tmp/csvf$i; done
d) 将5w+文件分批放置到这6个目录下
hadoop fs -put ./outf0* /tmp/csvf00
hadoop fs -put ./outf1* /tmp/csvf01
hadoop fs -put ./outf2* /tmp/csvf02
hadoop fs -put ./outf3* /tmp/csvf03
hadoop fs -put ./outf4* /tmp/csvf04
hadoop fs -put ./outf5* /tmp/csvf05e) 创建6张表,读取csvfile文件
CREATE external TABLE csv00
(id INT ,name STRING,age INT)
STORED AS CSVFILE
LOCATION '/tmp/csvf00'
TBLPROPERTIES(
'field.delim'=',',
'quote.delim'='"',
'line.delim'='\n') ;…剩余5张修改下表名和hdfs路径即可,以此类推
f) 尝试select count(*)看能否正常查询这几张表