概要描述
当集群内某个节点因硬件故障或其他原因导致该节点系统异常、无法正常访问等,并且该节点影响到了整个集群的正常运行,此时需要把该节点从集群中剔除,以恢复整个集群的正常运行。
该操作的前置条件包括以下几点:
- 删除的节点不能是manager节点;
- 删除的节点上不能有各服务的关键角色NameNode/Inceptor Server等(关于关键角色可以咨询星环科技技术支持工程师);
- 需要关闭 manager HA
详细说明
manager 页面展示的数据一般是来自数据库的(4.x 的数据来源是json文件),所以可以通过删除manager 数据库中该节点的数据,来删除这个节点;大致的步骤分为以下:
- 备份数据
- 确定删除的节点id以及相关表
- 重启 manager 生效
- 回滚并重启 manager 生效
TDH 4.x操作方法
- 1、备份数据
TDH 4.x 的manager 数据是由json 文件管理的,所以只需要备份json 文件即可;涉及到的文件以及路径主要有以下三个:
- /var/lib/transwarp-manager/master/data/data/Node.json
- /var/lib/transwarp-manager/master/data/data/Role.json
- /var/lib/transwarp-manager/master/data/data/ServiceConfigNodeEntry.json
备份命令参考如下:
$ cp /var/lib/transwarp-manager/master/data/data/Node.json /tmp/Node.json
$ cp /var/lib/transwarp-manager/master/data/data/Role.json /tmp/Role.json
$ cp /var/lib/transwarp-manager/master/data/data/ServiceConfigNodeEntry.json /tmp/ServiceConfigNodeEntry.json- 2、找到要删除节点的nodeid,然后删除该节点的相关信息
在/var/lib/transwarp-manager/master/data/data/Node.json中找到要删除的节点的nodeid,我们想删除原节点 hostname 为 tailong3 的节点,记录它的 id (此节点 id 为 6)
[root@tdh-41~]$ cat /var/lib/transwarp-manager/master/data/data/Node.json
[{"id":1,"activeStatus":"ACTIVE","ipAddress":"172.22.22.41","isManaged":true,"rackId":1,"clusterId":1,"osType":"RHEL","sshConfigId":1,"hostName":"tdh-41"},{"id":2,"activeStatus":"ACTIVE","ipAddress":"172.22.22.42","isManaged":true,"rackId":1,"clusterId":1,"osType":"RHEL","sshConfigId":1,"hostName":"tdh-42"},{"id":3,"activeStatus":"ACTIVE","ipAddress":"172.22.22.43","isManaged":true,"rackId":1,"clusterId":1,"osType":"RHEL","sshConfigId":1,"hostName":"tdh-43"},{"id":4,"activeStatus":"DELETED","ipAddress":"172.22.21.7","isManaged":true,"rackId":2,"clusterId":1,"osType":"RHEL","sshConfigId":2,"hostName":"tailong1"},{"id":5,"activeStatus":"ACTIVE","ipAddress":"172.22.21.8","isManaged":true,"rackId":2,"clusterId":1,"osType":"RHEL","sshConfigId":2,"hostName":"tailong2"},{"id":6,"activeStatus":"ACTIVE","ipAddress":"172.22.21.9","isManaged":true,"rackId":2,"clusterId":1,"osType":"RHEL","sshConfigId":2,"hostName":"tailong3"}]
然后修改这个json文件,把对应的条目删除,修改后的json文件:

在/var/lib/transwarp-manager/master/data/data/Role.json中找所有"nodeId":6的项并删除。
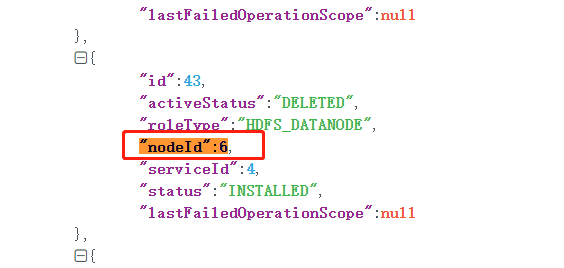
注意: 条目比较多, 别删除错了。
在/var/lib/transwarp-manager/master/data/data/ServiceConfigNodeEntry.json中找所有"nodeId"为6的项,并删除。
比较好的办法是把json copy出来,格式化后再删除,然后把修改后的json写入原始文件
- 3、重启manager生效
/etc/init.d/transwarp-manager restart
TDH 5.0及以上版本的操作方法
- 1、备份数据
备份备份role,node,service_config_node_entry三张表的数据,备份命令如下:
密码请参见
manager6以及TDH 5.x版本:
/etc/transwarp-manager/master/db.properties中的io.transwarp.manager.db.password字段
manager 7版本(版本查看:rpm -qa |grep manager ):
通过java -cp /etc/transwarp-manager/master:/usr/lib/transwarp-manager/master/lib/*:/usr/lib/transwarp-manager/common/lib/* io.transwarp.manager.master.util.DbUtils 命令获取
表名分别为:node、role、service_config_node_entry
$ mysqldump --host=localhost --port=3306 --user=transwarp --password=<密码> transwarp_manager -S /var/run/mariadb/transwarp-manager-db.sock <表名> > <备份文件地址>如:
mysqldump --host=localhost --port=3306 --user=transwarp --password=6D40xWxR8h transwarp_manager -S /var/run/mariadb/transwarp-manager-db.sock node > /root/node.sql- 2、登录 manager 数据库,确定删除节点id 以及相关数据
# manager6以及TDH 5.x版本登录方式:
$ mysql -h localhost -u transwarp -p$(cat /etc/transwarp-manager/master/db.properties | grep io.transwarp.manager.db.password | awk -F = '{print $2}') -S /var/run/mariadb/transwarp-manager-db.sock -D transwarp_manager
# manager 7版本登录方式:
mysql -h localhost -u transwarp -p$(java -cp /etc/transwarp-manager/master:/usr/lib/transwarp-manager/master/lib/*:/usr/lib/transwarp-manager/common/lib/* io.transwarp.manager.master.util.DbUtils) -S /var/run/mariadb/transwarp-manager-db.sock -D transwarp_manager
- 在 node 表中找到节点 id,这个172.22.21.22 节点的id是2,并删除
查看该节点的role信息
select * from node;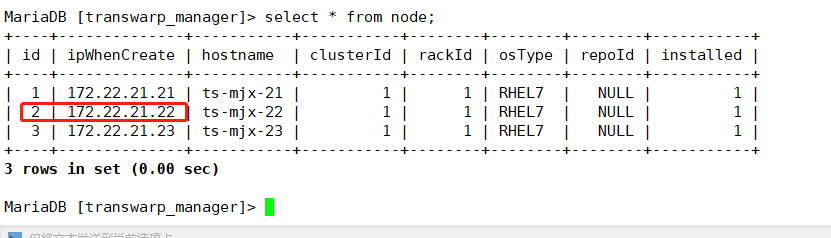
-
删除节点id 对应的其他数据,可以先确认一下是否有关键角色
删除该节点的role信息select * from role where nodeId=2; delete from role where nodeId=2;删除该节点的service_config信息
select * from service_config_node_entry where nodeId = 2; delete from service_config_node_entry where nodeId = 2;删除该节点的node信息
select * from node where id=2; delete from node where id=2; -
3、重启manager生效
/etc/init.d/transwarp-manager restart- 4、恢复备份
当误删除或节点恢复后,可以使用如下方法恢复:
TDH 4.x 集群恢复只需要将之前备份的文件cp 到原来的路径即可:$ cp /tmp/Node.json /var/lib/transwarp-manager/master/data/data/Node.json $ cp /tmp/Role.json /var/lib/transwarp-manager/master/data/data/Role.json $ cp /tmp/ServiceConfigNodeEntry.json /var/lib/transwarp-manager/master/data/data/ServiceConfigNodeEntry.json
TDH 5.x 集群恢复主要登录数据库,将mysqldump出来的文件 source 一下即可:
$ mysql -h localhost -u transwarp -p$(cat /etc/transwarp-manager/master/db.properties | grep io.transwarp.manager.db.password | awk -F = '{print $2}') -S /var/run/mariadb/transwarp-manager-db.sock -D transwarp_managersource <备份的文件>如:
MariaDB [transwarp_manager]> source /root/node.sql
Query OK, 1 rows affected (0.03 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
...重启manager生效
/etc/init.d/transwarp-manager restart其他信息
本KB只适用于非manager节点和集群失联,完全不可恢复,且在管理界面上无法删除的状况,如果节点可以恢复请不要执行。