内容纲要
概要描述
本案例用于解决高版本集群内 Shiva Master 运行异常,个别 master 启动失败的问题;
在shell下利用可执行文件 shiva_tool 修复 master group;
注意:修复的前置条件是至少有一台 Shiva Master 的状态是正常的!用以进入 pod 且可以执行shiva_tool脚本;
详细说明
Shiva安装时默认推荐的 Shiva Master 节点数应该至少是3,当 Master group 只剩少数节点存活时,为了保证 Master 提供的数据的一致性,此时 Master 就无法对外提供服务;
修复逻辑主要分为以下几步:
- 选择一个功能正常的 Shiva Master 节点,并将该节点变成集群唯一的 Shiva Master ;
- 停止其他 shiva Master 角色
- 删除其他 shiva Master 数据路径下的元数据库;
- 启动其他 shiva Master 角色
- 将其他的 shiva master 添加到 Shiva 集群
1 选择一个功能正常的 Shiva Master 节点,并将该节点变成集群唯一的 Shiva Master
获取状态正常的 Shiva Master 的pod name,以本例,只有一个master正常

停止32节点,这个不健康的shiva master
高版本的指定shiva master 需要额外的指定
–master_token_server_id=${master_server_id}
–master_token_timestamp=${master_token_timestamp};
所以,进入健康的shiva master pod内,先获取上面的master_server_id 以及 master_token_timestamp
/usr/shiva-master/bin/shiva_tool --cmd=print_master_token --master_token_path=/etc/argodbstorage1/conf/shiva/.token
开始set_master_group
/usr/shiva-master/bin/shiva_tool --cmd=set_master_group --address=${master_address} --master_token_server_id=${master_server_id}
--master_token_timestamp=${master_token_timestamp}根据场景,实际操作的命令是
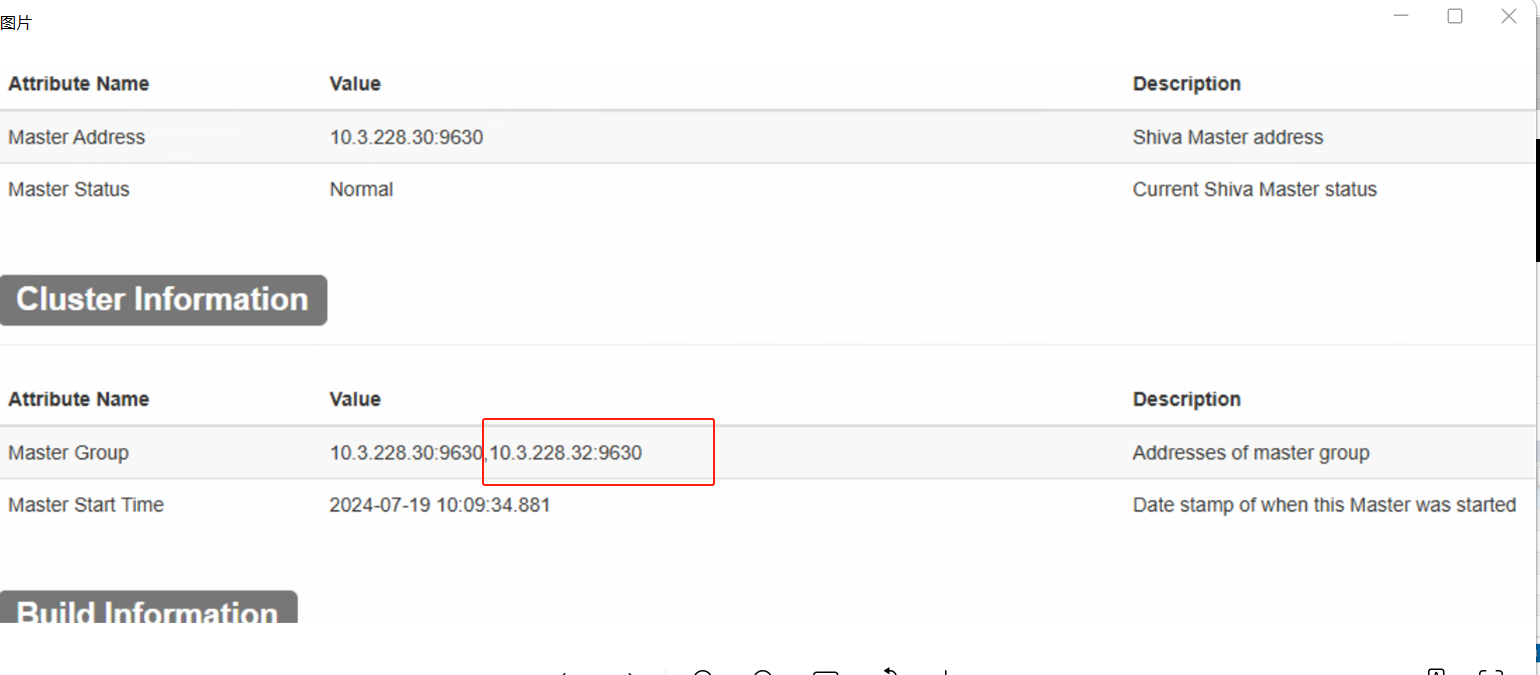
/usr/shiva-master/bin/shiva tool -cmd=set_master_group --addres=10.3.228.30:9630 --master_token_server_id=33964652373406 --master_token timestamp=163695872851159单个shiva master没有set_master_group的时候shiva webui是启动不了的,一边set_master_group成功后,shiva web可以启动成功。
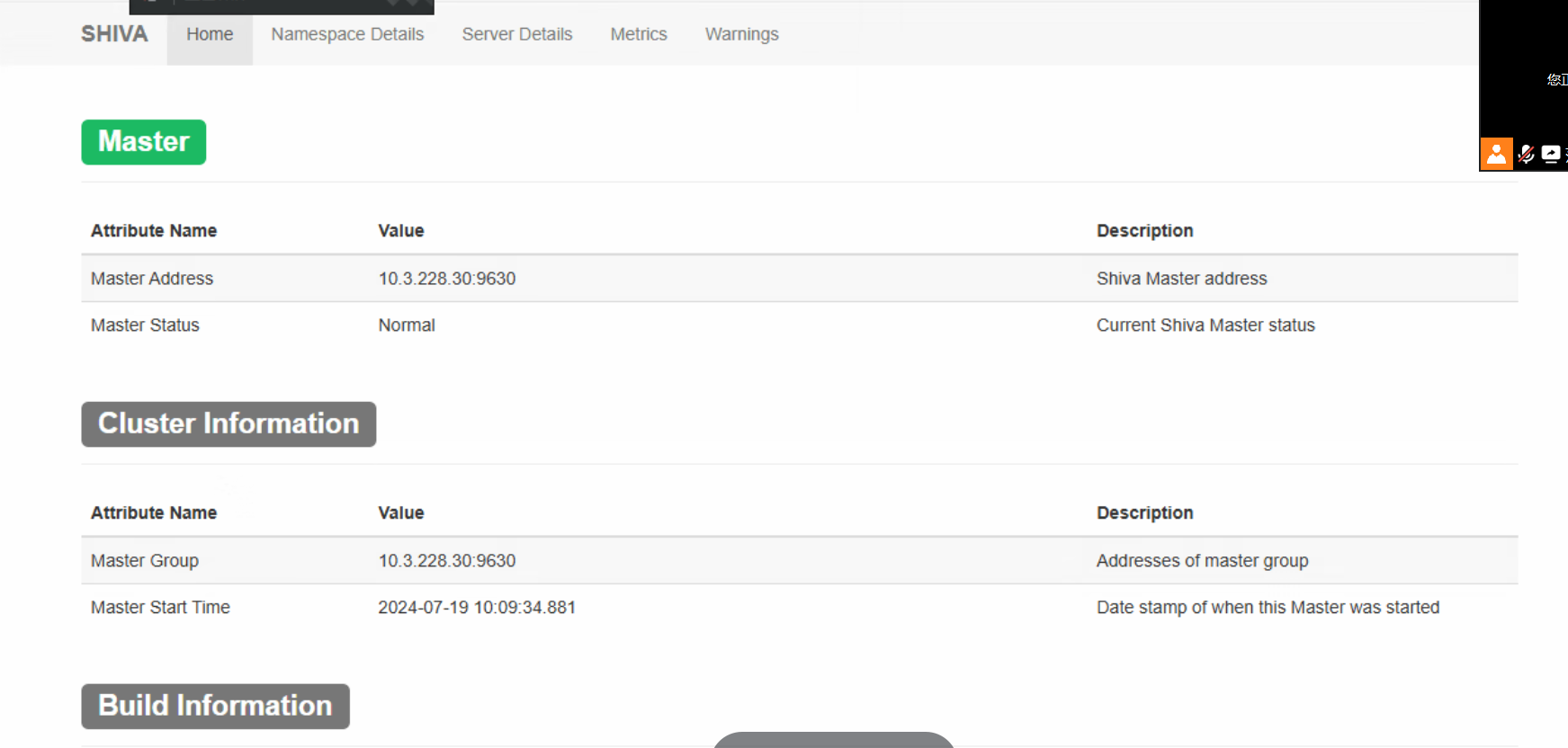
2 在确认不健康的shiva master停止后,删除其元数据库
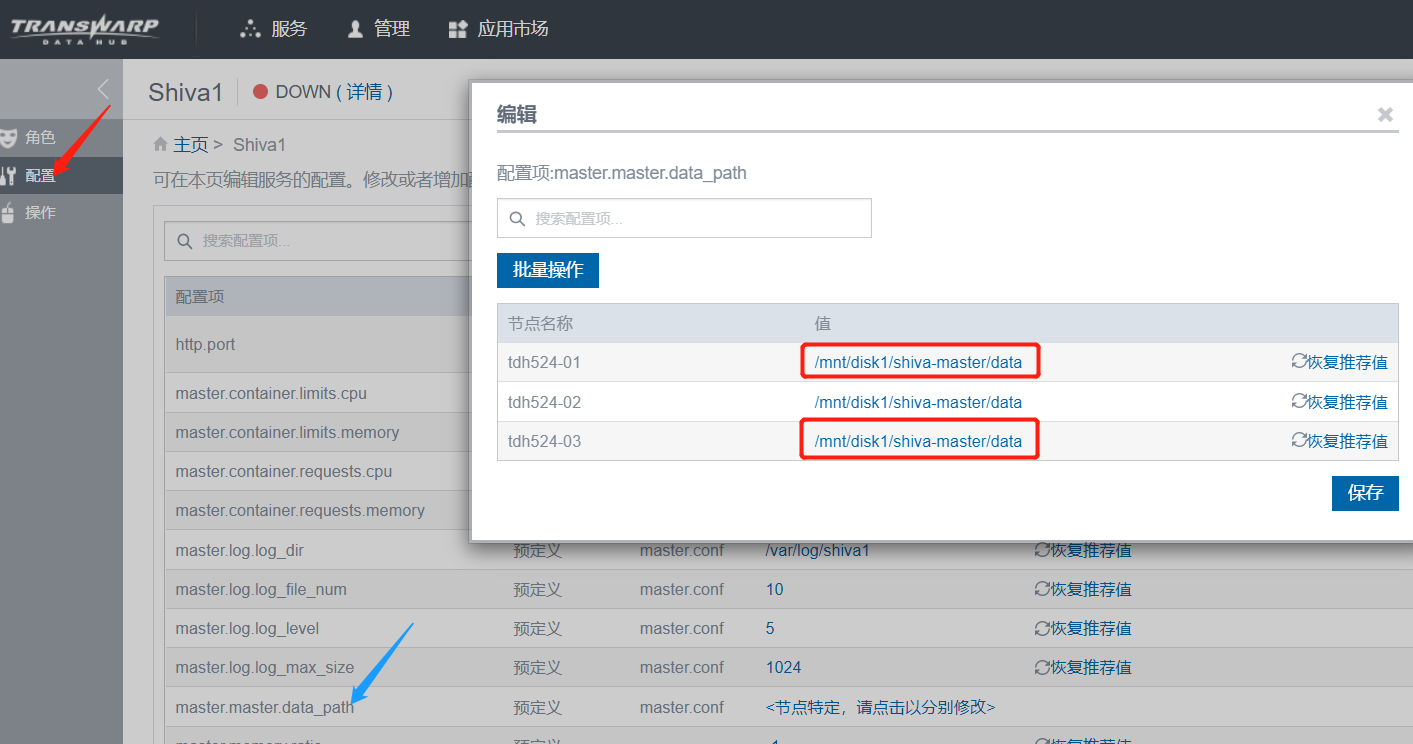
登录到其他的shiva master节点上,删除对应的数据目录

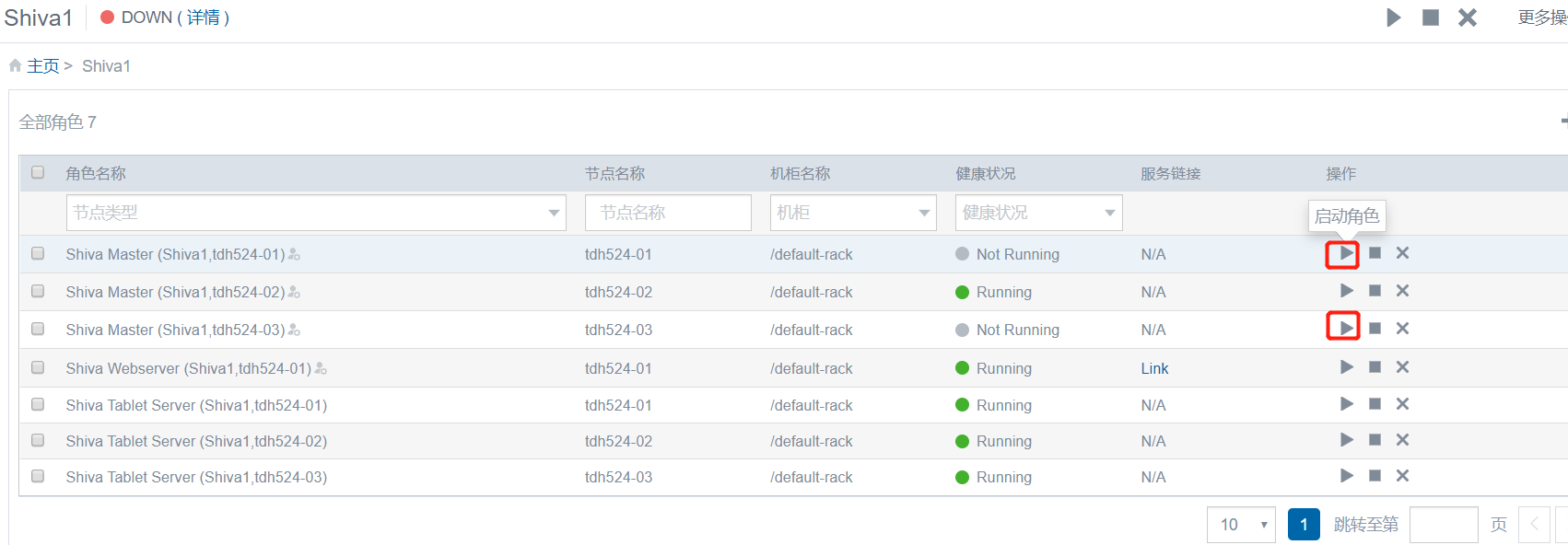
3 manager页面启动不正常的shiva master
4 进入第一步选择的Shiva Master pod,将其他的 shiva master 添加到 Shiva 集群
/usr/shiva-master/bin/shiva_tool --master_group=${master_address} --cmd=add_master_member --address=${不健康的master_address} --master_token_server_id=${master_server_id}
--master_token_timestamp=${master_token_timestamp}根据场景,实际操作的命令是
/usr/shiva-master/bin/shiva_ool --master_group=10.3.228 30:9630 --cmd=add_master_member --addres=10.3.28.32:9630 --master_token_server_id=33964652373406 --master_token_timestamp=1636958872851159执行完成后,可以通过webui观察一下