内容纲要
概要描述
TDH 9.3 之后的版本,hadoop 版本升级为 hadoop3 了,本文介绍一下 Spark 在 hadoop3 环境上的使用方法;
详细说明
- 下载spark
- 配置 YARN 以及 Spark 环境
- 删除 Guardian 认证
- Spark-shell 以及 spark-submit 验证
1、下载 spark
spark 官网下载:https://spark.apache.org/downloads.html , 历史所有版本:https://archive.apache.org/dist/spark/
2、配置yarn
2.1 拷贝spark运行时依赖的jars到hdfs
hadoop fs -put /jars /tmp/spark3/2.2 spark-env.sh 配置
# 以下配置请根据本地实际环境配置 (必要)
HADOOP_USER_NAME=hive
HADOOP_CONF_DIR=/etc/hdfs1/conf2.3 spark-defaults.conf基础配置
# 以下配置请根据本地实际环境配置(必要)
# spark on yarn 依赖的jars,2.1 节上传的jar包路径
spark.yarn.jars hdfs://172.22.37.171:8020/tmp/spark3/jars/*
# 指定spark运行在yarn环境的java版本(默认yarn的jdk版本为jdk 1.7)
# 具体jdk路径可以查看yarn image中的jdk路径
spark.executorEnv.JAVA_HOME /usr/java/jdk1.8.0_25
spark.yarn.appMasterEnv.JAVA_HOME /usr/java/jdk1.8.0_25
2.4 拷贝配置文件到spark conf目录
# 拷贝inceptor hive-site.xml配置,用于读取argodb的配置信息
cp /etc/inceptor1/conf/hive-site.xml /conf
# 拷贝yarn yarn-site.xml & core-site.xml配置,用于读取yarn的配置信息
cp /etc/yarn1/conf/yarn-site.xml /conf
cp /etc/yarn1/conf/core-site.xml /conf
# 拷贝HDFS hdfs-site.xml配置,用于读取HDFS的配置信息
cp /etc/hdfs1/conf/hdfs-site.xml /conf3、删除 guardian 认证
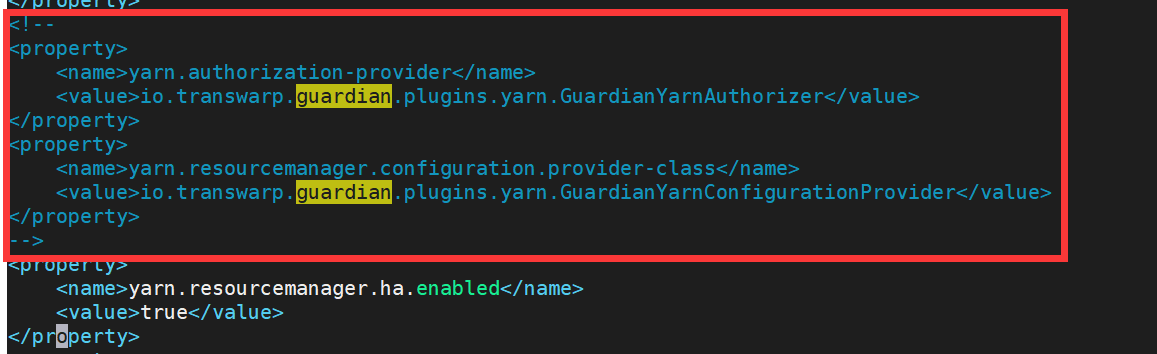
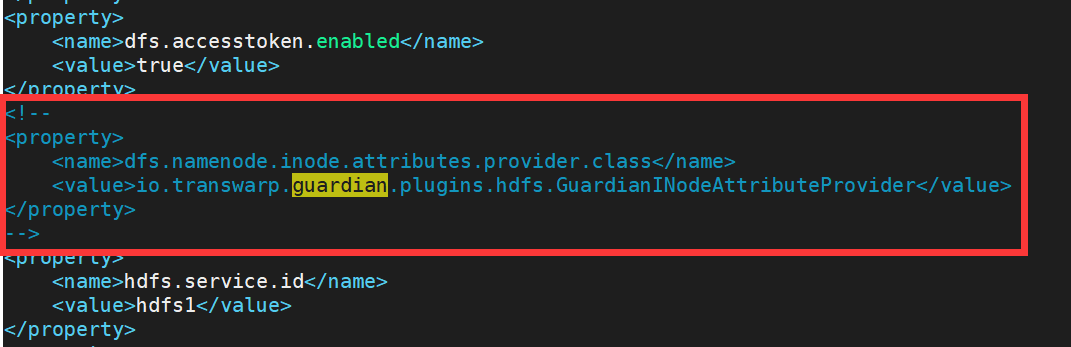
删除配置文件中 guardian 的认证,主要是 yarn-site.xml 以及 hdfs-site.xml,像这样:
yarn-site.xml:
hdfs-site.xml:
4、测试验证
./bin/spark-shell --master yarn --conf spark.ui.port=4444 --driver-memory 1g --executor-memory 2g --num-executors 2 --executor-cores 1 --principal admin@GTSARGODB5 --keytab admin_171.keytab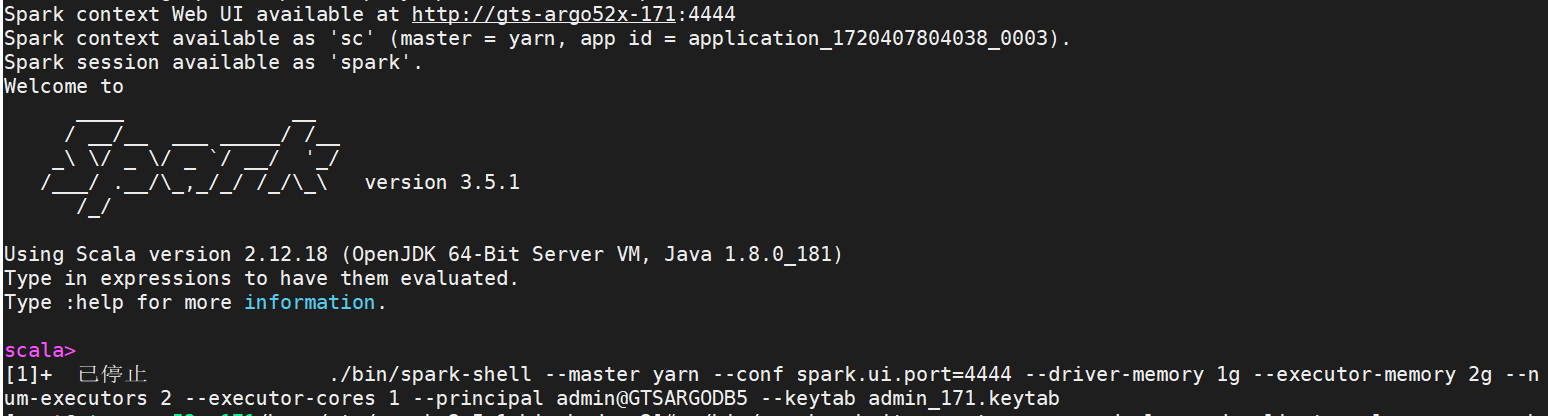
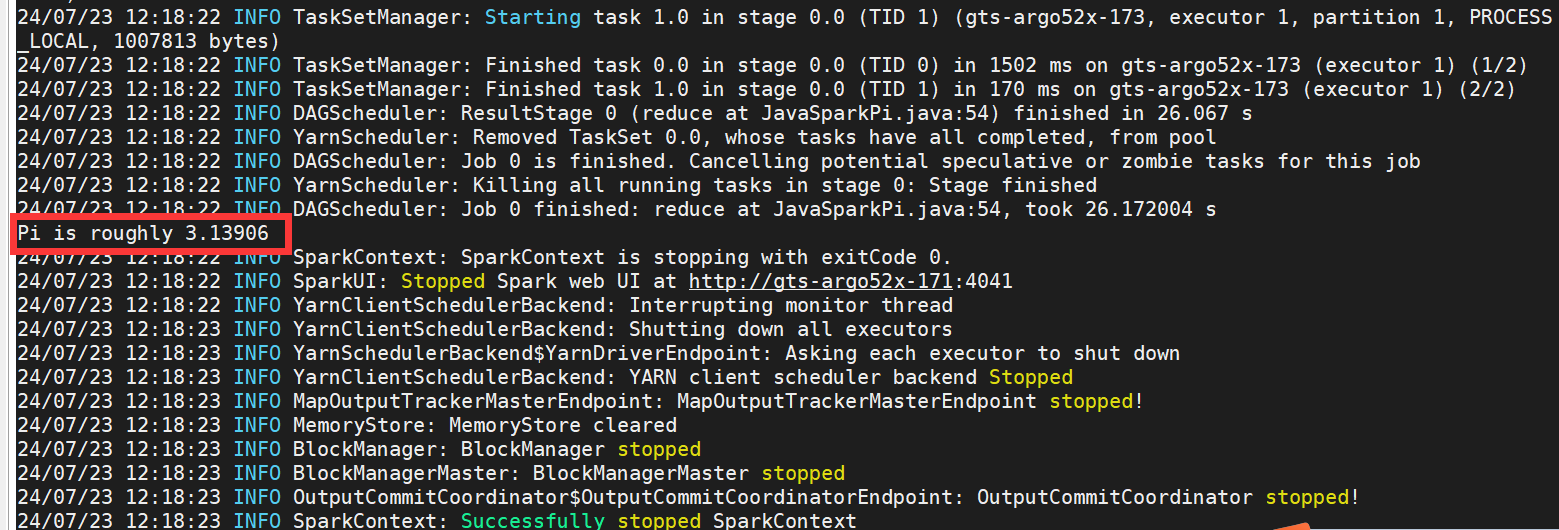
./bin/spark-submit --master yarn --deploy-mode client --class org.apache.spark.examples.JavaSparkPi --executor-memory 2g --driver-memory 2g --principal admin@GTSARGODB5 --keytab admin_171.keytab examples/jars/spark-examples_2.12-3.5.1.jar