内容纲要
概要描述
本文旨在讲解流表join的glkjoin使用方法
详细说明
Glkjoin是最为推荐的流表join方法,适合于大表join。只支持hyperdrive和es表。
hyperdrive表:
测试用例:
1.未开安全
开启事件模式
SET streamsql.use.eventmode=true;
事件模式下自动flush数据
SET morphling.result.auto.flush=true;
建流
DROP STREAM IF EXISTS test_stream;
CREATE STREAM test_stream(id INT, letter STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
TBLPROPERTIES("topic"="jane","kafka.zookeeper"="172.22.39.7:2181,","kafka.broker.list"="172.22.39.7:9092");
DROP TABLE IF EXISTS test_hyperbase;
建表
CREATE TABLE test_hyperbase(id INT, letter STRING)
STORED AS HYPERDRIVE;
DROP STREAMJOB test_streamJob;
创建streamjob,该streamjob将流和表的letter字段进行拼接后插入表test_hyperbase
CREATE STREAMJOB test_streamJob AS ("
INSERT INTO test_hyperbase
SELECT /* +glkjoin(b) */ a.id,concat(a.letter, b.letter)
FROM test_stream a
LEFT JOIN test_hyperbase b
ON a.id = b.id
");
开启streamjob
START STREAMJOB test_streamJob;
LIST STREAMJOBS;
SELECT * FROM test_hyperbase;
STOP STREAMJOB test_streamjob;
生产者数据: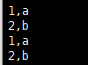
结果表:

2.开启安全
开启安全和未开安全的主要区别就是建流方式不同
建流
建流
DROP STREAM test_stream1;
CREATE STREAM test_stream1(id INT, letter STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
TBLPROPERTIES("topic"="demoo",
"kafka.zookeeper"="172.22.22.1:2181",
"kafka.broker.list"="172.22.22.1:9092",
"transwarp.consumer.security.protocol"="SASL_PLAINTEXT",
"transwarp.consumer.sasl.kerberos.service.name"="kafka",
"transwarp.consumer.sasl.jaas.config"="com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true storeKey=true keyTab=\"/etc/slipstream1/conf/xmyh.keytab\" principal=\"xmyh@TDH\""
);
建表
DROP TABLE IF EXISTS test_hyperbase;
CREATE TABLE test_hyperbase(id INT, letter STRING)
STORED AS HYPERDRIVE;
创建衍生流,此处衍生流的作用是将表和流的字段进行拼接
CREATE STREAM s3 AS
SELECT /* +glkjoin(b) */ a.id,concat(a.letter, b.letter)
FROM test_stream1 a
LEFT join test_hyperbase b
ON a.id = b.id;
设置glkjoin的batchsize
set stargate.global.lookup.join.batchsize=1;
启动job,将衍生流数据插入表test_hyperbase
INSERT INTO test_hyperbase SELECT * FROM s3;
SELECT * FROM test_hyperbase;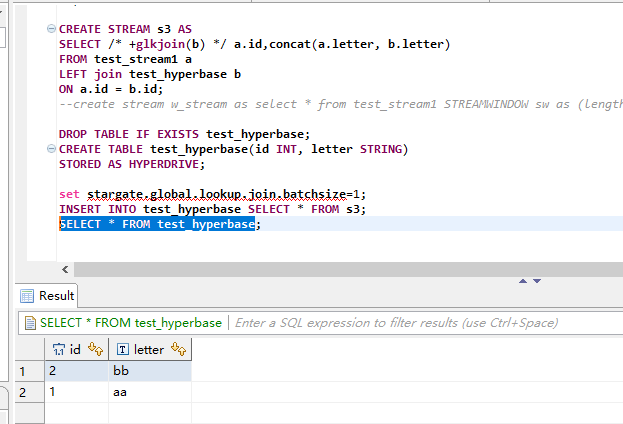
ES表:
测试用例:
1.未开安全
建流
DROP STREAM test_stream;
CREATE STREAM test_stream(id string, letter STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
TBLPROPERTIES("topic"="jane","kafka.zookeeper"="172.22.39.7:2181,","kafka.broker.list"="172.22.39.7:9092");
创建过渡表t1
DROP TABLE t1;
CREATE TABLE t1 (id STRING, letter STRING) stored as ES with shard number 8 replication 1;
创建streamjob,把流数据插入表t1
CREATE STREAMJOB sb AS ("INSERT INTO t1 SELECT * FROM test_stream");
START STREAMJOB sb;
SELECT * FROM t1;
建表tab
CREATE TABLE tab (id STRING, letter STRING) stored as ES with shard number 8 replication 1;
建流test_stream2
CREATE STREAM test_stream2(id string, letter STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
TBLPROPERTIES("topic"="jane","kafka.zookeeper"="172.22.39.7:2181,","kafka.broker.list"="172.22.39.7:9092");
创建streamjob,将test_stream2数据插入表tab
CREATE STREAMJOB 2job AS ("insert into tab select * from test_stream2");
START STREAMJOB 2job;
SELECT * FROM tab;
DROP STREAMJOB 2job;
DROP STREAM s3;
创建衍生流s3,做Glkjoin
CREATE STREAM s3 AS
SELECT /* +glkjoin(b) */ a.id,concat(a.letter, b.letter)
FROM test_stream a
join tab b
ON a.id = b.id;
建表t8
DROP TABLE t8;
CREATE TABLE t8 (id STRING, letter STRING) stored as ES with shard number 8 replication 1;
建窗口流s2_join
DROP STREAM s2_join;
CREATE STREAM s2_join as SELECT * FROM s3 STREAMWINDOW w1 AS
(INTERVAL '1' SECOND);
建streamjob。把窗口流数据插入表t8
CREATE STREAMJOB test_streamJob AS ("insert into t8 select * from s2_join");
START STREAMJOB test_streamJob;
LIST STREAMJOBS;
DROP STREAMJOB test_streamJob;
SELECT * FROM t8;
STOP STREAMJOB test_streamJob;
生产者数据:
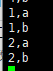
结果表:
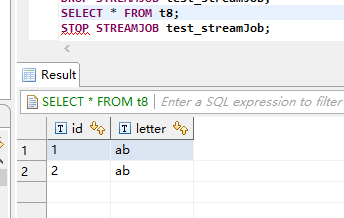
2.开启安全
建流
DROP STREAM test_stream;
CREATE STREAM test_stream(id string, letter STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
TBLPROPERTIES("topic"="demoo",
"kafka.zookeeper"="172.22.22.1:2181",
"kafka.broker.list"="172.22.22.1:9092",
"transwarp.consumer.security.protocol"="SASL_PLAINTEXT",
"transwarp.consumer.sasl.kerberos.service.name"="kafka",
"transwarp.consumer.sasl.jaas.config"="com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true storeKey=true keyTab=\"/etc/slipstream1/conf/xmyh.keytab\" principal=\"xmyh@TDH\""
);
建表
DROP TABLE t1;
CREATE TABLE t1 (id STRING, letter STRING) stored as ES with shard number 8 replication 1;
开启streamjob
CREATE STREAMJOB sb AS ("INSERT INTO t1 SELECT * FROM test_stream");
START STREAMJOB sb;
SELECT * FROM t1;
DROP streamjob sb;
建表tab
DROP TABLE IF EXISTS tab;
CREATE TABLE tab (id STRING, letter STRING) stored as ES with shard number 8 replication 1;
建流test_stream2
CREATE STREAM test_stream2(id string, letter STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
TBLPROPERTIES("topic"="demoo",
"kafka.zookeeper"="172.22.22.1:2181",
"kafka.broker.list"="172.22.22.1:9092",
"transwarp.consumer.security.protocol"="SASL_PLAINTEXT",
"transwarp.consumer.sasl.kerberos.service.name"="kafka",
"transwarp.consumer.sasl.jaas.config"="com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true storeKey=true keyTab=\"/etc/slipstream1/conf/xmyh.keytab\" principal=\"xmyh@TDH\""
);
开启streamjob
CREATE STREAMJOB 2job AS ("insert into tab select * from test_stream2");
START STREAMJOB 2job;
SELECT * FROM tab;
DROP STREAMJOB 2job;
创建glkjoin衍生流s3
DROP STREAM s3;
CREATE STREAM s3 AS
SELECT /* +glkjoin(b) */ a.id,concat(a.letter, b.letter)
FROM test_stream a
join tab b
ON a.id = b.id;
建表t8
DROP TABLE t8;
CREATE TABLE t8 (id STRING, letter STRING) stored as ES with shard number 8 replication 1;
开启streamjob
CREATE STREAMJOB test_streamJob AS ("insert into t8 select * from s3");
START STREAMJOB test_streamJob;
LIST STREAMJOBS;
DROP STREAMJOB test_streamJob;
SELECT * FROM t8;
STOP STREAMJOB test_streamJob;
中间表数据:
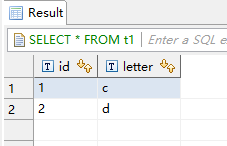
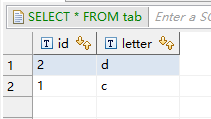
生产者数据:
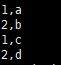
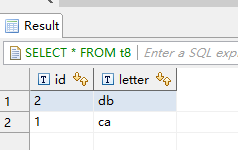
结果表数据:
注:
如遇到日志报错:
2019-12-19 15:24:34,836 WARN execution.GlobalLookupJoinOperator: (Logging.scala:logWarning(71)) [HiveServer2-Handler-Pool: Thread-164(SessionHandle=3a45dafc-26b8-400e-a966-fd27c623a2ee)] - This RSOp with the table [tab]contains the column which can not enable global lookup join: class org.apache.hadoop.hive.ql.udf.generic.GenericUDFToDecimal(Column[id]()注意es表第一列必须是string,所以stream的第一列也是string,否则会有这种字段类型报错产生
注:kafka生产消费数据使用命令可以参考:
kafka生产消费数据