概要描述
本文旨在说明slipstream事件驱动和微批模式的异同
slipstream官网介绍链接:slipstream官网介绍
详细说明
Slipstream推荐事件驱动模型, 事件驱动模型是TDH4.8之后新增的流处理模型,5.1及之后默认开启事件驱动模型。ngmr.engine.mode参数决定了Slipstream选择何种引擎,ngmr.engine.mode=mapred为微批模型, ngmr.engine.mode=morphling为事件驱动模型。
也可以通过创建job的时候指定驱动模型:
CREATE STREAMJOB as ("")
JOBPROPERTIES("streamsql.use.eventmode"="true"[,"key"="value"...]); 事件驱动模型更接近原生的流处理,一有数据进来就处理. 就好比流水线上的零件, 来一个处理一个

微批模型顾名思义还是基于"批"的思想. 将Input Stream按时间段分割成一个个小块处理. 就像是给流水线增加一个缓冲, 每隔一段时间去取一批零件加工

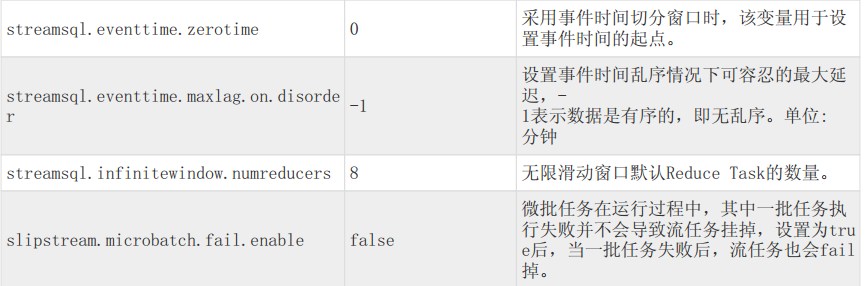
相比较微批模型, 事件驱动模型具有以下特点:
- 延迟更低: 微批是秒级的延迟,而事件驱动模型的延迟是毫秒级的.
- 功能更全:
a. 支持会话窗口(Session Window),
b. 复杂事件的处理(CEP)
c. 更加完善的高可用性(HA)(9.3节)
d. StreamJob的Auto-failover
Stream
事件驱动模型中,当数据源处有数据进来就立即处理,来一条处理一条.
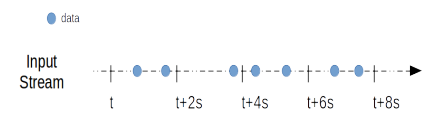
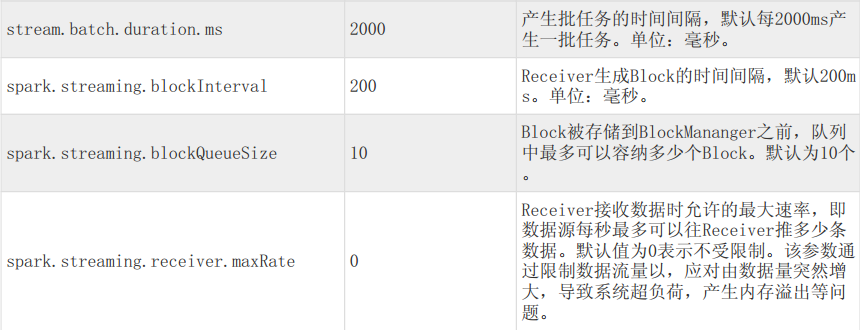
微批模型下Input Stream被分割成一系列 小数据块(Batch) 来处理,Batch在获取数据时生成: 在一段单位时间内获取的数据都放进一个batch中,这段单位时间称为 Batch Interval,它的长度(Batch Duration)可以设置,如下图所示。
Derived Stream
事件驱动模型下, 每得到一条数据,就对其进行变形,得到Derived Stream:
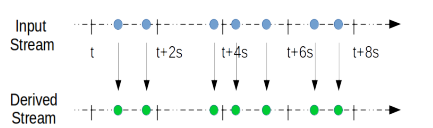
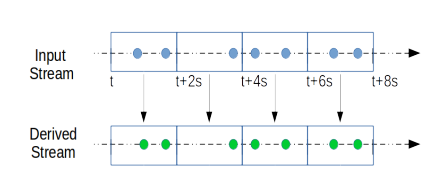
而微批模型下,因为Input Stream是一系列batch,那么Stream的变形实际上是对batch计算得到新batch的
过程:
Window Stream
事件驱动模型下支持秒级的window stream
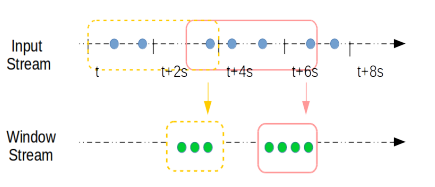
上图中窗口长度(Length)为4s,滑动间隔(Slide)为3s. 如此图中的第一个窗口为[t,t+4s),第二个窗口为[t+3s,t+7s),以此类推. 窗口的长度和滑动的间隔只要是1s的整数倍即可. 需要注意的是, 当t=0s,即Stream创建的初始时刻, 第一个窗口为[0,3s),比窗口长度会少1秒,这是因为Slide是执行窗口操作的间隔, Slide时间到了就会执行窗口计算.
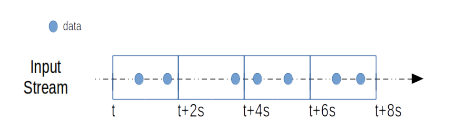
微批模型下,窗口长度(Length)和滑动间隔(Slide)的长度都必须是batch duration的整数倍。
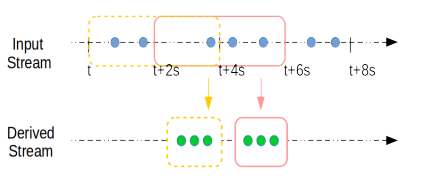
上图的窗口变形中,length是batch duration的2倍(SET streamsql.hdfs.batchflush.interval.ms=2;),slide是batch duration的1倍。如此图中的第一个窗口为[t,t+4s),第二个窗口为[t+2s,t+6s),以此类推. 与事件驱动模型相同的是,当t=0时,第一个窗口的长度等于Slide(2s).
从TDH 5.1开始, 在事件驱动模式下支持用户自定义输入源. 添加自定义输入源步骤如下:
- 继承 io.transwarp.slipstream.api.source.CustomDataSource 抽象类
def init(id: Int, params: Properties): Unit /** * non-blocking * return null if get nothing */ def poll(): Array[Byte] def close(): Unit
示例代码参考slipstream手册6.2.6.1.4章节
Stream DML 注意事项
事件驱动模式下, 只在 window stream 下支持聚合操作
微批模式: 支持流与流的join,支持流与表的join.
事件驱动模式下:
支持mapjoin和global lookup join.
流与流的Join要求join的两个流必须是window stream,且window的slide(滑动间隔)必须一致
从TDH5.1开始,在事件驱动模式下支持自定义输出,demo参考手册6.3.8.3章节
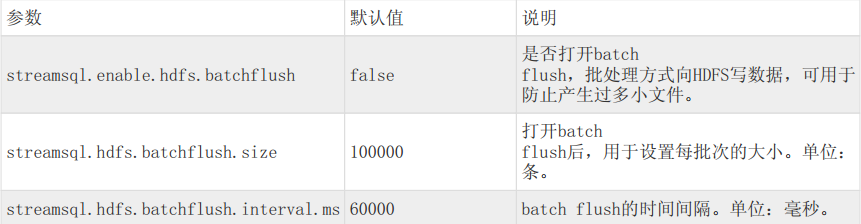
批量Flush到HDFS
支持批量将数据flush到HDFS上的TEXT表和ORC表,批量flush可以避免产生过多小文件。注意,目标表不能为事务表、分区表(5.1.2以前版本)或者分桶表。进行批量flush需要设置下面几个 job级别 的参数:
微批模式
SET streamsql.enable.hdfs.batchflush = true
–打开批量flush开关
SET streamsql.hdfs.batchflush.size =
–设置一次flush的消息个数,消息量达到该参数时flush一次
SET streamsql.hdfs.batchflush.interval.ms =
–设置每过多长时间(单位为毫秒)flush一次
只需满足 batchflush.size 和 batchflush.interval.ms 其中的一个条件即会触发一次flush。
事件驱动模式
SET morphling.result.auto.flush=true
–来一条数据刷一条到输出表, 可在测试时使用,不推荐在生产中使用.
批量Flush默认开启
• TDH5.1前
SET morphling.hdfs.flush.size =
–设置一次flush的消息个数,消息量达到该参数时flush一次, 默认100000
SET morphling.hdfs.flush.interval.ms =
–设置每过多长时间(单位为毫秒)flush一次,默认60000
• TDH5.1+
SET morphling.record.flush.size =
SET morphling.record.flush.interval.ms =
同微批模式, flush size 和 flush interval 满足其中之一就会触发一次Flush.
事件驱动模式下支持分区表函数(Partition Table Function,PTF)。 PTF将输入流视为一张分区表,根据定义的分区字段分成不同的partition,通过时间划分窗口,然后在这个窗口(有限数据集)上做分析。 与在Stream Window上做聚合计算不同的是,PTF功能更多,计算更灵活,详情参考手册6.9.1章节
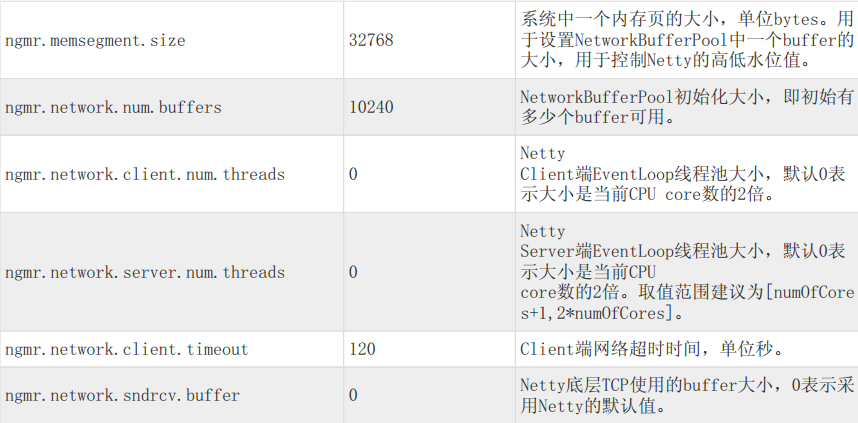
微批模式下参数
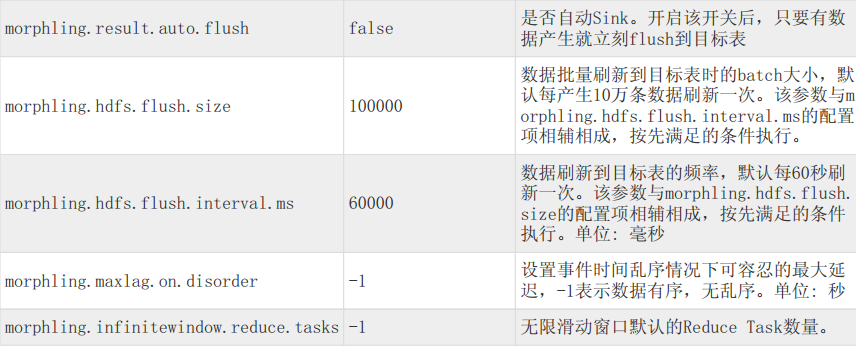
事件驱动模式下参数