概要描述
在一个TxSQL集群中,只有一个节点处于不健康状态,而其他节点都是健康的,而且流水也都是正常的(允许跟Master有差异但一直在追赶、没有停滞),可能的异常表现有:
1.在发生故障的pod里,phxbinlogsvr不能稳定运行
2.在发生故障的pod里,/usr/bin/txsql/tools/该目录下不停的生成 core 开头的二进制文件,导致 /var/lib/docker 磁盘满了
详细说明
适用范围
- 系统中的多数节点仍然处于健康状态(且他们的流水也处于正常的状态)
- 数据量比较小。一般需要小于5GB,否则容易由于pod操作超时而失败
修复步骤
环境描述:txsql部署在mll01、mll02、mll03三台机器上,且IP分别为172.22.33.1、172.22.33.2、172.22.33.3,出现故障的节点为mll03,我们要修复这个节点。以下描述中,我们同时用主机名来命名对应的主机上TxSQL pod的名称
1. 检查mll01、mll02上的TxSQL处于启动状态且健康
若无法正常提供服务(Transwarp Manager界面显示它们不健康),则停止操作
2. 检查master信息和成员信息
进入TxSQL pod mll01(或者mll02)的 /usr/bin/txsql/tools 目录,执行 ./txsql.sh list,以进入 mll01 的pod为例
[root@mll01 lib]# kubectl get pod -owide | grep txsql-server-txsql
txsql-server-txsql1-9f966c857-lfx2h 1/1 Running 0 1d 172.22.33.3 mll03
txsql-server-txsql1-9f966c857-tqvjl 1/1 Running 1 2d 172.22.33.1 mll01
txsql-server-txsql1-9f966c857-xjm8w 1/1 Running 1 2d 172.22.33.2 mll02
[root@mll01 lib]# kubectl exec -it txsql-server-txsql1-9f966c857-tqvjl bash
[root@mll01 /]# cd /usr/bin/txsql/tools
[root@mll01 tools]# ./txsql.sh list
get master 172.22.33.1 expire time 1579161434 Thu Jan 16 15:57:14 2020
ip 172.22.33.1 port 17000
ip 172.22.33.2 port 17000
ip 172.22.33.3 port 17000
[root@mll01 tools]#
3. 使用 ./txsql.sh rm 命令移除故障节点
这一步也是在 mll01 的txsql pod中的 /usr/bin/txsql/tools 目录下执行,再执行 ./txsql.sh list 以确认故障节点移除成功
[root@mll01 tools]# ./txsql.sh rm 172.22.33.3
get master 172.22.33.1 expire time 1579161644 Thu Jan 16 16:00:44 2020
RemoveMember 172.22.33.3 done
N
[root@mll01 tools]# ./txsql.sh list
get master 172.22.33.1 expire time 1579161649 Thu Jan 16 16:00:49 2020
ip 172.22.33.1 port 17000
ip 172.22.33.2 port 17000
[root@mll01 tools]# 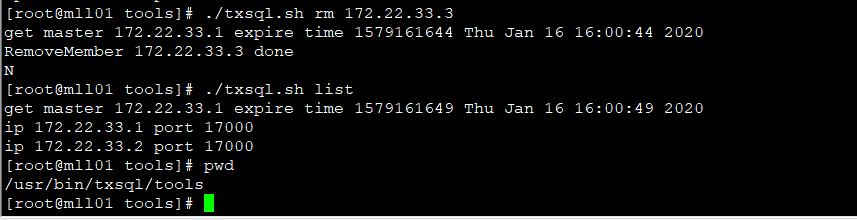
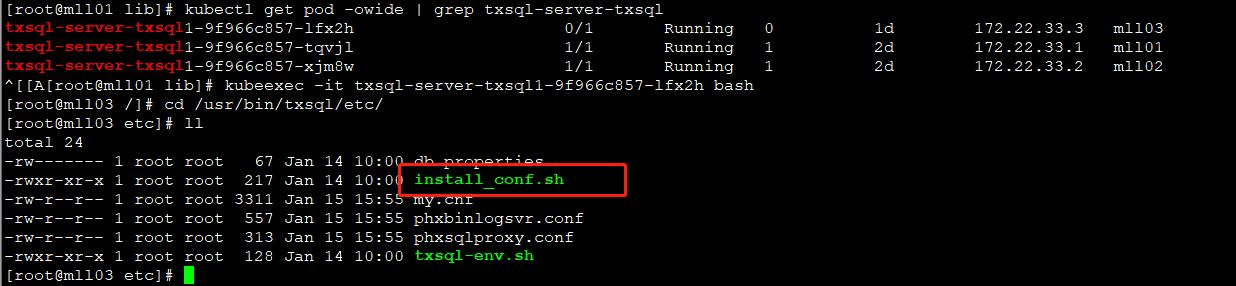
4. 强制故障节点重新初始化
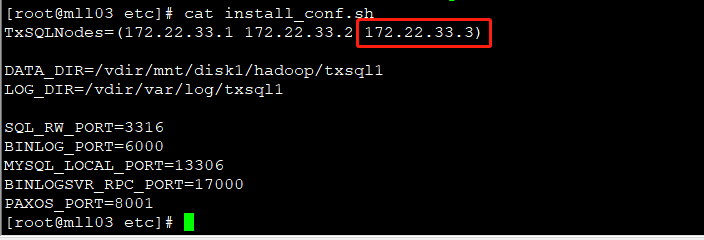
- 进入故障节点 mll03 的pod的 /usr/bin/txsql/etc/ 目录,编辑 install_conf.sh;
- 确保 mll03 的IP(即172.22.33.3)在TxSQLNodes数组中不是第一个。如果是,可以把它与第二个交换位置;
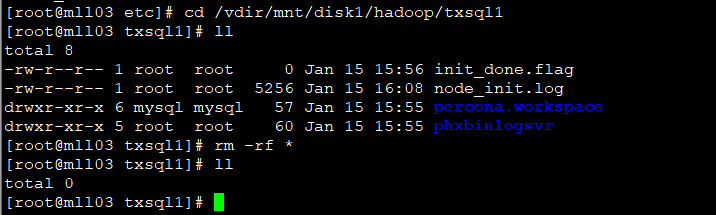
- install_conf.sh 的 DATA_DIR 变量记录了TxSQL数据目录的路径,需要手动删除该目录下的全部内容,但必须保留这个目录,删除完之后退出该pod;
- 使用Transwarp Manager重新启动该pod,这会强制这个pod重新初始化
如果manager页面状态不是 not running,先手动停止,再点击启动

5. 进入 mll03 新启动的pod(注意,必须在pod内部操作,以保证dump数据的兼容性,否则后期数据很可能无法导入),等待数据目录下出现 init_done.flag 文件(该文件的出现标志着初始化完成)
使用下面的命令从一个健康的节点(比如mll01)备份数据。在mll01的txsql pod中执行,可以在持久化路径(/var/log/txsql1/)下执行,免去pod和宿主机之间传文件的步骤
端口(默认是3316)和密码请根据具体情况修改,root密码可在 /usr/bin/txsql/etc/db.properties 中查看
/usr/bin/txsql/percona.src/bin/mysqldump -h172.22.33.1 -P3316 -uroot -p412818497 --single-transaction --all-databases --triggers --routines --events >mydata.sqlmydata.sql该文件可以在mll01的宿主机路径/var/log/txsql1/下看到,将该文件传到故障节点 mll03节点的 /var/log/txsql1/ 目录下
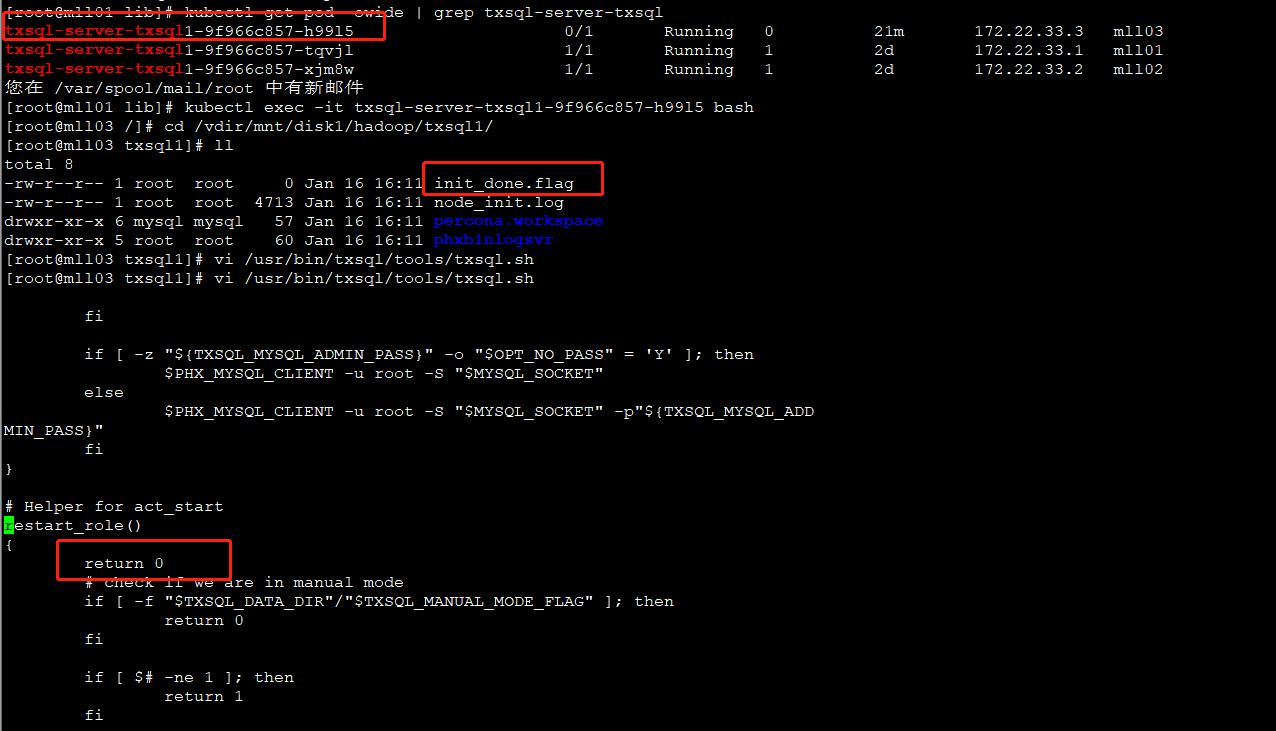
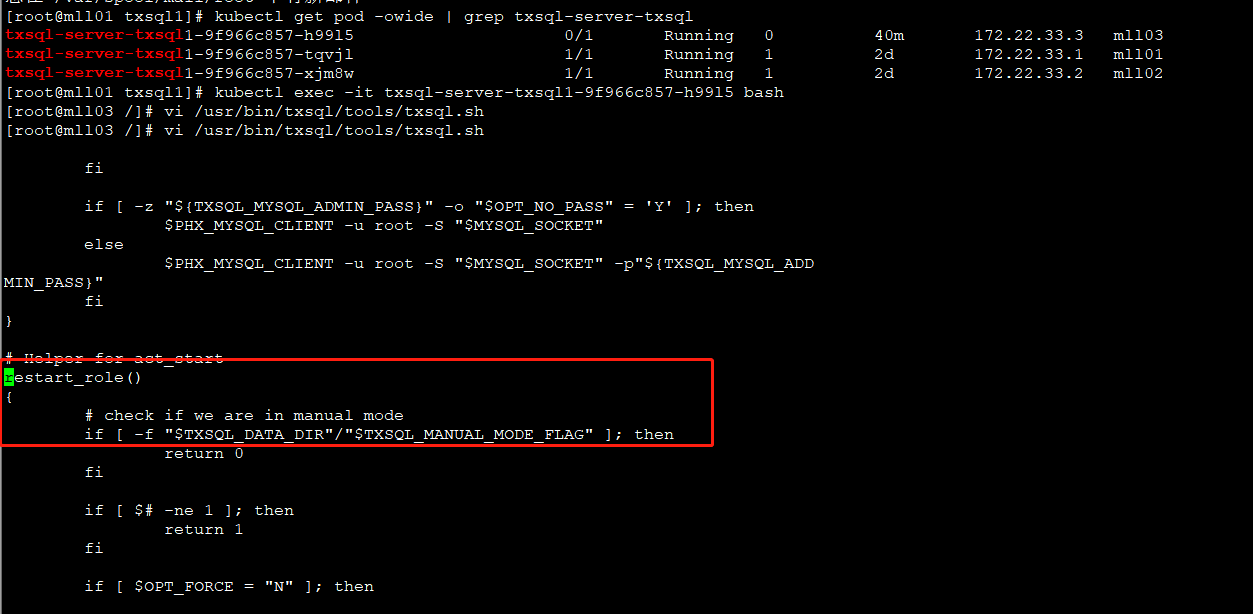
6. 待mll03新启动的pod的数据目录下出现init_done.flag后,编辑文件 /usr/bin/txsql/tools/txsql.sh,在函数restart_role的第一行添加 return 0,目的是禁止新pod自动重启服务。以下是编辑后的结果示例:
7. 在mll03 pod的目录 /usr/bin/txsql/tools 下执行 ./txsql.sh kill phxbinlogsvr 命令来杀死这个phxbinlogsvr进程。可以使用 ps -ef 查看是否成功
[root@mll03 txsql1]# ps -ef | grep phxbinlogsvr
root 368 1 2 16:11 ? 00:00:31 /usr/bin/txsql/sbin/phxbinlogsvr_phxrpc
root 18864 16976 0 16:36 pts/1 00:00:00 grep --color=auto phxbinlogsvr
[root@mll03 txsql1]# cd /usr/bin/txsql/tools
[root@mll03 tools]# ./txsql.sh kill phxbinlogsvr
Namespace(base_dir='/usr/bin/txsql/', new_process='', process_name='phxbinlogsvr')
kill -9 368
[root@mll03 tools]# ps -ef | grep phxbinlogsvr
root 19216 16976 0 16:36 pts/1 00:00:00 grep --color=auto phxbinlogsvr
[root@mll03 tools]# 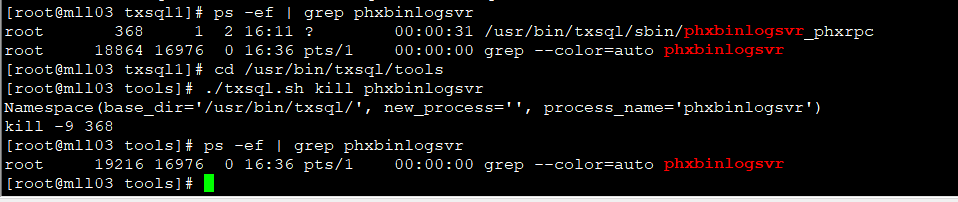
8. 把mll03添加回TxSQL的Paxos Group中,并确认该操作成功完成。需要等待20秒验证,确认它没有自动重启
该步骤在 mll01 正常节点的pod中执行
[root@mll01 lib]# kubectl exec -it txsql-server-txsql1-9f966c857-tqvjl bash
[root@mll01 /]# cd /usr/bin/txsql/tools
[root@mll01 tools]# ./txsql.sh add 172.22.33.3
get master 172.22.33.1 expire time 1579163994 Thu Jan 16 16:39:54 2020
AddMember 172.22.33.3 done
Y
[root@mll01 tools]# ./txsql.sh list
get master 172.22.33.1 expire time 1579163999 Thu Jan 16 16:39:59 2020
ip 172.22.33.1 port 17000
ip 172.22.33.2 port 17000
ip 172.22.33.3 port 17000
[root@mll01 tools]#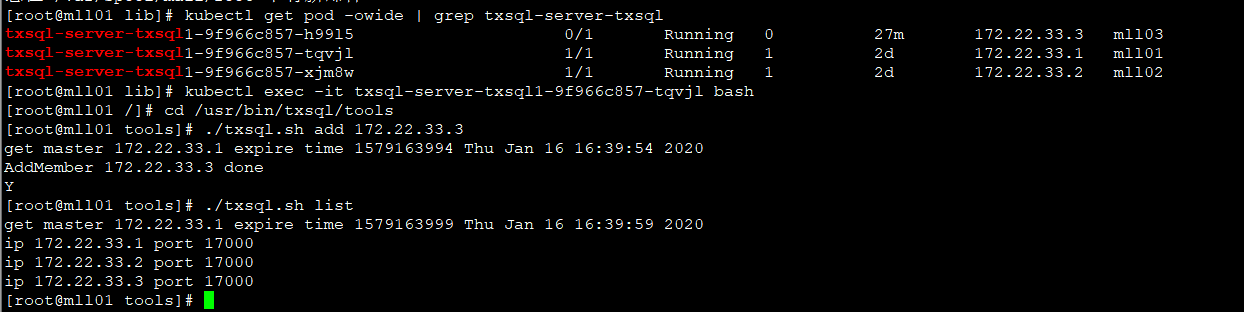
9. 向mll03中导入数据
- 先确认备份的数据是否已经在mll03的txsql pod的/var/log/txsql1/路径下;

- 确认phxbinlogsvr没有自己重启。执行以下命令,结果中不应该看到phxbinlogsvr进程:
ps -ef | grep phxbinlogsvr | grep -v grep
- 登录MySQL,并使用以下命令导入数据
#先找到socket文件
find / -name percona.sock
#在/var/log/txsql1目录下使用socket登录mysql
mysql -S /vdir/mnt/disk1/hadoop/txsql1/percona.workspace/tmp/percona.sock
mysql> set global super_read_only=off;
mysql> set global read_only=off;
mysql> source mydata.sql;
# flush privileges 前必须要先 set sql_log_bin=0,否则会引起严重的错误
mysql> set sql_log_bin=0;
mysql> flush privileges;
# 第一次导入时会因为缺少用户而导致一些问题,因此需要进行第二次导入
mysql> source mydata.sql;
mysql> reset slave;如果操作出现任何问题或者错误,则必须到mll01的pod里上,从第3步重新开始整个修复过程
10. 恢复mll03上文件 /usr/bin/txsql/tools/txsql.sh 的原有内容,即删除restart_role函数里新添加的第一行 return 0 语句。最多等待20s后,phxbinlogsvr进程自动重启(一般会重启两次)。可以使用 ps -ef 验证

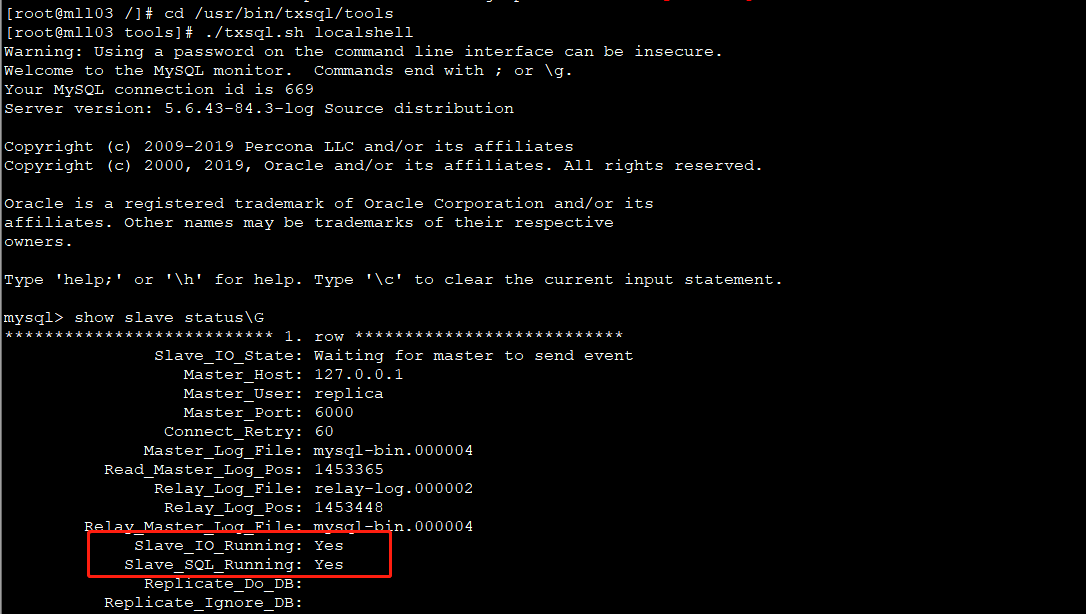
11. 执行以下命令检查流水是否正常:
[root@mll03 /]# cd /usr/bin/txsql/tools
[root@mll03 tools]# ./txsql.sh localshell
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 127.0.0.1
Master_User: replica
Master_Port: 6000
Connect_Retry: 60
Master_Log_File: mysql-bin.000004
Read_Master_Log_Pos: 1453365
Relay_Log_File: relay-log.000002
Relay_Log_Pos: 1453448
Relay_Master_Log_File: mysql-bin.000004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB: 结果中Slave_IO_Running、Slave_SQL_Running必须处于Yes状态
12. 操作完成。Transwarp Manager中此时应显示3个节点均为健康状态
