内容纲要
概要描述
本文旨在介绍流表join之一般join的用法
详细说明
一般join(只在mapred下支持)
超过hive.mapjoin.smalltable.filesize参数指定的mapjoin,会自动转换成common join
一般join支持的表:
orc分区表
text表
orc表
text分区表
holodesk表
不支持的表:
orc事务分区表
orc事务表
测试语句:
开启动态分区功能
SET hive.exec.dynamic.partition=true;
建流s1
CREATE STREAM s1(id int, name STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
TBLPROPERTIES("topic"="demoo",
"kafka.zookeeper"="172.22.22.1:2181",
"kafka.broker.list"="172.22.22.1:9092",
"transwarp.consumer.security.protocol"="SASL_PLAINTEXT",
"transwarp.consumer.sasl.kerberos.service.name"="kafka",
"transwarp.consumer.sasl.jaas.config"="com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true storeKey=true keyTab=\"/etc/slipstream1/conf/xmyh.keytab\" principal=\"xmyh@TDH\""
);
text表:
--CREATE TABLE tb1(id INT, name STRING);
--CREATE TABLE tb3(id INT, name STRING);
text分区表:
--CREATE TABLE tb1(id INT, name STRING) PARTITIONED BY (sex string);
--CREATE TABLE tb3(id INT, name STRING) PARTITIONED BY (sex string);
INSERT INTO tb3 SELECT 1,'a' FROM system.dual;
INSERT INTO tb3 SELECT 1,'b' FROM system.dual;
orc分区表:
--CREATE TABLE tb4(id int, name STRING) partitioned by(sex string) STORED AS orc;
--CREATE TABLE tb3(id int, name STRING) partitioned by(sex string) STORED AS orc;
INSERT INTO tb3 PARTITION (sex='b') SELECT 1,'a' FROM system.dual;
INSERT INTO tb3 PARTITION (sex='b') SELECT 1,'b' FROM system.dual;
SELECT * FROM tb3;
SHOW CREATE TABLE tb1;
SHOW PARTITIONS tb3;
orc表:
--CREATE TABLE tb3(id int, name STRING) STORED AS orc;
--CREATE TABLE tb4(id int, name STRING) STORED AS orc;
orc事务分区表:
--CREATE TABLE tb3(id INT, name STRING)PARTITIONED BY (sex string) CLUSTERED BY (id) INTO 2 BUCKETS STORED AS ORC TBLPROPERTIES('transactional'='true');
--CREATE TABLE tb1(id INT, name STRING)PARTITIONED BY (sex string) CLUSTERED BY (id) INTO 2 BUCKETS STORED AS ORC TBLPROPERTIES('transactional'='true');
orc事务表:
--CREATE TABLE tb3(id INT, name STRING) CLUSTERED BY (id) INTO 2 BUCKETS STORED AS ORC TBLPROPERTIES('transactional'='true');
--CREATE TABLE tb4(id INT, name STRING) CLUSTERED BY (id) INTO 2 BUCKETS STORED AS ORC TBLPROPERTIES('transactional'='true');
--Holodesk表(事件驱动模式下不支持)(holodesk不支持分区操作)
holodesk表:
--CREATE TABLE tb4(id INT, name STRING) STORED AS holodesk;
--CREATE TABLE tb3(id INT, name STRING) STORED AS holodesk;
建衍生流s3,实现流表join
CREATE STREAM s3 AS
SELECT a.id,b.name
FROM s1 a
LEFT join tb3 b
ON a.id = b.id;
把衍生流s3数据入表
INSERT INTO tb1 partition(sex='b') select * from s3;
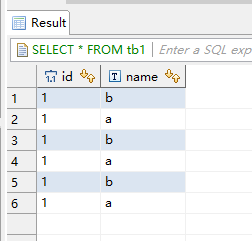
SELECT * FROM tb1;
结果显示流表可以成功join:
注:集群开安全情况下kafka对接slipstream参考文档:
kafka对接slipstream