内容纲要
概要描述
场景:个别txsql节点状态异常,但是多数txsql节点状态正常;
常见报错信息:pod日志显示: Connection refused; ERROR 2013 (HY000): Lost connection to MySQL server at ‘reading initial communication packet’, system error: 2; 或者是pod的STATUS是running的,但是READY是0/1;
详细说明
此类问题常用修复步骤:
- 确定txsql master节点
- 确定并备份故障节点的txsql数据目录
- 删除txsql故障节点上txsql的数据
- 从txsql master节点同步数据至问题节点
- 启动txsql并检查服务
案例说明
master节点:tdh-61,ip 172.22.22.61
故障节点:tdh-62,ip 172.22.22.62
DATA_DIR(数据路径):宿主机是/mnt/disk1/hadoop/txsql1/ pod内是/vdir/mnt/disk1/hadoop/txsql1/
一、确定txsql master节点
- 列出所有txsql-server的pod
[root@tdh-61~]$ kubectl get pods -owide|grep txsql - 选择任一running状态的txsql-server-txsql的pod,进入bash命令行,例如:
[root@tdh-61~]$ kubectl exec -ti txsql-server-txsql1-597f7ff996-sz55f bash - 执行 /usr/bin/txsql/tools/txsql.sh list 命令列出所有txsql,该命令会同时输出master节点IP信息,例如master 172.22.22.61:
[root@tdh-62 tools]# /usr/bin/txsql/tools/txsql.sh list get master 172.22.22.61 expire time 1564037694 Thu Jul 25 14:54:54 2019 ip 172.22.22.61 port 17000 ip 172.22.22.62 port 17000 ip 172.22.22.63 port 17000
二、确定并备份故障节点的txsql数据目录
- 登录 Manager 页面 (http://manager_ip:8180)
- 点击 TxSQL 组件,并点击 配置 按钮进入TxSQL组件的配置参数页面
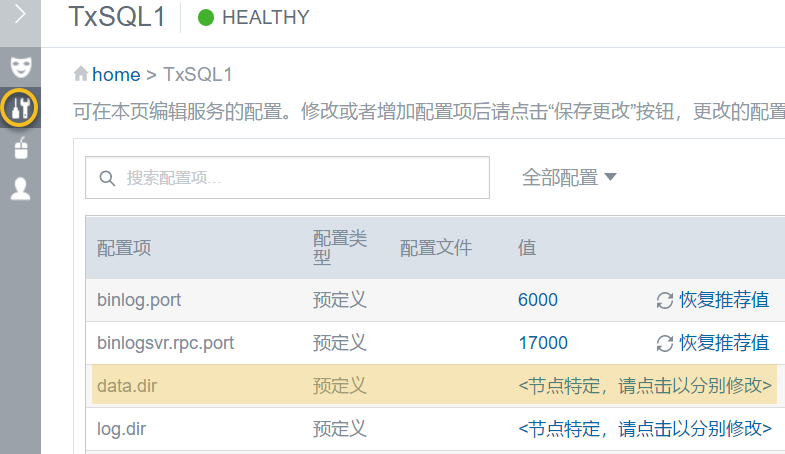
- 点击查看 data.dir 参数的各节点路径值,确定故障节点的txsql数据路径
- 备份故障节点上的 auto.cnf (一般路径为$DATA_DIR$/percona.workspace/data/auto.cnf)至宿主机上的安全目录下,例如:
# cd /mnt/disk1/hadoop/txsql1/percona.workspace/data # cp -p auto.cnf /etc/txsql1/
三、删除txsql故障节点上txsql的数据
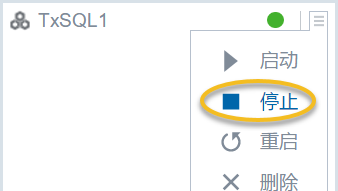
删除数据之前需要停止txsql服务,可以通过manager页面停止txsql组件;
- 在 Manager 页面,停止 TxSQL 组件服务;
- 在TxSQL故障节点上,根据第二步确定的txsql数据目录,删除txsql的数据,例如:
# rm -rf /mnt/disk1/hadoop/txsql1/percona.workspace # rm -rf /mnt/disk1/hadoop/txsql1/phxbinlogsvr
四、从txsql master节点同步数据至问题节点
根据第一步找到的txsql master节点和第二步找到的数据路径,在txsql master节点上,用scp命令同步数据至故障节点$DATA_DIR$/percona.workspace,例如:
# cd /mnt/disk1/hadoop/txsql1/
# scp -r percona.workspace root@tdh-62:/mnt/disk1/hadoop/txsql1
# scp -r phxbinlogsvr root@tdh-62:/mnt/disk1/hadoop/txsql1
//tdh-62为txsql故障节点备注:如果scp的两个节点的数据路径DATA_DIR不一致,在scp之后需要修改$DATA_DIR$/percona.workspace/binlog/mysql-bin.index文件内容为故障节点的数据路径
五、恢复auto.cnf
使用第二步备份的故障节点的auto.cnf覆盖从master节点复制过来的$DATA_DIR$/percona.workspace/data/auto.cnf文件,例如:
# cp -p /etc/txsql1/auto.cnf /mnt/disk1/hadoop/txsql1/percona.workspace/data六、修改权限
从master节点scp的数据及目录需要修改权限和owner,参照如下:
# chown -R 1000:1000 /mnt/disk1/hadoop/txsql1/percona.workspace
# chown -R 1000:1000 /mnt/disk1/hadoop/txsql1/phxbinlogsvr七、启动txsql并检查服务
- 在Manager页面启动txsql服务;
- 检查故障节点(如tdh-62)服务是否正常,例如:
- 进入故障节点pod:
# kubectl get pods -owide |grep txsql # kubectl exec -ti txsql-server-txsql1-597f7ff996-sz55f bash - 检查 phxbinlogsvr是否已经正常工作,至少看到一个非空的EVENTDATA-XXXX 文件,例如:
# ls -lh /vdir/mnt/disk1/hadoop/txsql1/phxbinlogsvr/event_data total 52M -rw-r--r-- 1 root root 3.6M Jul 25 15:51 EVENTDATA-224348 -rw-r--r-- 1 root root 48M Jul 15 21:27 EVENTDATA-95622 drwxr-xr-x. 2 root root 4.0K Jul 24 18:45 event_lb - 能够看到正确的成员信息,能够成功登陆本地mysql服务,并且保证流水正常,(Slave_IO_Running和Slave_SQL_Running都是Yes)例如:
# cd /usr/bin/txsql/tools # ./txsql.sh list get master 172.22.22.61 expire time 1564041903 Thu Jul 25 16:05:03 2019 ip 172.22.22.61 port 17000 ip 172.22.22.62 port 17000 ip 172.22.22.63 port 17000 # ./txsql.sh localshell Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> show slave status \G; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 127.0.0.1 Master_User: replica Master_Port: 6000 Connect_Retry: 60 Master_Log_File: mysql-bin.000007 Read_Master_Log_Pos: 427199 Relay_Log_File: relay-log.000002 Relay_Log_Pos: 427282 Relay_Master_Log_File: mysql-bin.000007 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: 此处可以看到list成员信息正确,能够登录localshell服务,流水状态正常(Slave_IO_Running和Slave_SQL_Running都是Yes); - 至此TXSQL单节点故障离线修复完成且成功。
- 进入故障节点pod: