内容纲要
概要描述
本案例详细介绍hbase的SQL Bulkload操作流程,以及注意事项;
详细说明
Bulkload是一种快速向Hbase导入大量数据的方法;
SQL BulkLoad的适用场景为:
- 初次原始数据导入
- 增量数据导入
1、操作前准备工作
- 准备数据集,并上传至HDFS
2、根据hdfs数据建立Inceptor外表
请确保源表中的数据是按照splikey均匀分布的,否则bulkload导入数据后各region可能会出现数据倾斜的状况,后续使用会引发负载不均衡的问题;
create external table store_people
(name string, sex string
, nation STRING
, idcard STRING
, b_date STRING
, phone STRING
, email STRING
, addr STRING)
ROW FORMAT delimited fields TERMINATED BY ',' location '/tmp/hbase/';3、采样生成SplitKey
在导入数据之前,用户需要对数据进行采样,根据采样结果可以生成splitkey,作为预分region的依据;
采样表即用来保存采样的结果,采样表列中必须包含 所有 用来生成rowkey的源表字段;
例如,源表中的 idcard 字段会用来生成目标表的rowkey:
create table sample_table
(idcard STRING)
ROW FORMAT delimited FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '\001'
MAP KEYS TERMINATED BY '\003'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;3.1、存放采样结果
根据原始数据收集采样结果:
INSERT INTO TABLE sample_table SELECT sample(20618,idcard) FROM store_people;— 说明:
— Inceptor提供了sample函数用来生成splitkey;
— sample函数接受至少2个参数,第1个参数是采样率,采样率=数据条数/97/预分region数,其中的 97 是固定值,是因为sample 函数扫描 hdfs 数据时每隔 97 行取一行。
— 样例数据有10000000条,预分5个region,因此采样率=10000000/97/5,即采样率为20618;
— 后面的参数为采样表中的列名;
— 用户需要根据自身业务场景和实际数据量,确定导入后目标表的rowkey,region数量;
3.2、通过采样获取splitkey
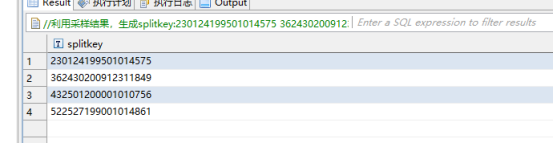
将查询结果记录下来,下一步需要使用这些splitkey创建目标表:
select splitkey from (
select max(c) as splitkey from (
select idcard c, ntile(5) over (order by idcard) nt from sample_table ) group by nt
) order by splitkey LIMIT 4;- 说明:
- ntile函数的参数即为预分region的数量;
- limit的数量是预分region数量减一;
最终获取到的splitkey如下图所示:
4、使用Inceptor建立hbase表的映射表
根据上一步骤得到的splitkey创建hbase表:
DROP TABLE sqlbulkload_test;
CREATE TABLE sqlbulkload_test
(key STRING
, name STRING
, sex STRING
, nation STRING
, b_date BIGINT
, phone STRING
, email STRING
, addr STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '\001'
MAP KEYS TERMINATED BY '\003'
LINES TERMINATED BY '\N'
STORED by org.apache.hadoop.hive.hbase.HBaseStorageHandler
TBLPROPERTIES(
'hbase.table.splitkey'='230124199501014575,362430200912311849,432501200001010756,522527199001014861',
'COMPRESSION'='SNAPPY',
'hbase.table.name'='sqlbulkload_test');5、使用SQL Bulkload导入数据
使用bulkload的方式从源表中将数据导入目标表
insert into table sqlbulkload_test
select /*+USE_BULKLOAD*/
idcard key,name STRING,sex STRING,nation STRING,
b_date BIGINT,phone STRING,email STRING,addr STRING
from store_people order by key;6、在hbase shell中查看数据已经成功插入
