概要说明
面对一些重要数据,很多场景下都需要将数据仓库进行复制,这可以是整个数据库的更广泛级别,也可以是较小的级别。本案例将演示Export/Import 的方式导入导出 hbase 数据。
该方法hbase同版本、不同版本之间都可以迁移数据,但最好是在同版本之间迁移数据。
该方法适用于数据量较小的hbase表。
详细说明
本案例介绍使用 Export/Import 的方式导入导出 hbase 数据,该方法只需要3步:
- 在源集群上执行export 将数据文件copy到 HDFS 路径
- 将数据文件copy 到目标集群并上传到HDFS
- 在目标集群创建一样结构的表
- 在目标集群上 Import 到hbase 表
与inceptor的Export/Import导出导入数据不同,hbase不会同步导出导入表的元数据信息,所以需要在目标集群手动创建一样结构的表。
注意:
- 以下所有操作必须是 hbase 用户来执行,如果是开了安全的集群,需要kinit hbase获取认证信息,如果是没开安全的集群,执行命令之前需要加上
sudo -u hbase - 以下操作需要准备好TDH客户端,参考:准备TDH客户端环境
1、在源集群上执行export 将数据文件copy到 HDFS 路径
hbase org.apache.hadoop.hbase.mapreduce.Driver export sqlbulkload_test_hbase /tmp/mll/sqlbulkload_test_hbase注意:
上述命令中的/tmp/mll/sqlbulkload_test_hbase必须是hdfs上 不存在 的路径
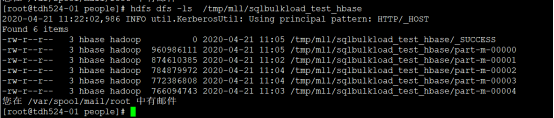
2、将数据文件copy 到目标集群并上传到HDFS
将数据目录和文件 scp 到目标集群,并上传到 HDFS 上,本案例中以同一个的集群的不同表来模拟同版本之间数据迁移。
hdfs dfs -cp /tmp/mll/sqlbulkload_test_hbase/part-m-00001 /tmp/mll/hbase_qianyi/
3、在目标集群上创建和源表结构一样的表
本案例建表语句如下
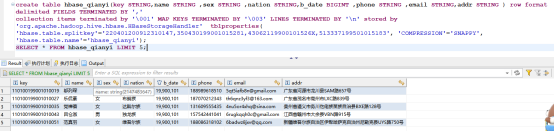
create table hbase_qianyi(key STRING,name STRING ,sex STRING ,nation STRING,b_date BIGINT ,phone STRING ,email STRING,addr STRING ) row format delimited FIELDS TERMINATED BY ','
collection items terminated by '\001' MAP KEYS TERMINATED BY '\003' LINES TERMINATED BY '\n' stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' tblproperties( 'hbase.table.splitkey'='220401200912310147,350430199001015281,43062119900101526X,513337199501015183', 'COMPRESSION'='SNAPPY', 'hbase.table.name'='hbase_qianyi');4、在目标集群上 Import 到hbase 表
-
同版本之间,执行 Import 导入数据
hbase org.apache.hadoop.hbase.mapreduce.Driver import hbase_qianyi /tmp/mll/hbase_qianyi/ -
不同版本之间,执行 Import 导入数据时,需要指定目标集群hbase的版本号,本次案例是将TDH524的数据迁移到TDH621版本中,TDH621中hbase的版本是1.3。
hbase -Dhbase.import.version=1.3 org.apache.hadoop.hbase.mapreduce.Driver import hbase_qianyi /tmp/mll/hbase/
5、同步后确认数据是否导入成功
6、FAQ
-
数据量很大的表在export导出的时候报错:
ERROR: java heap space
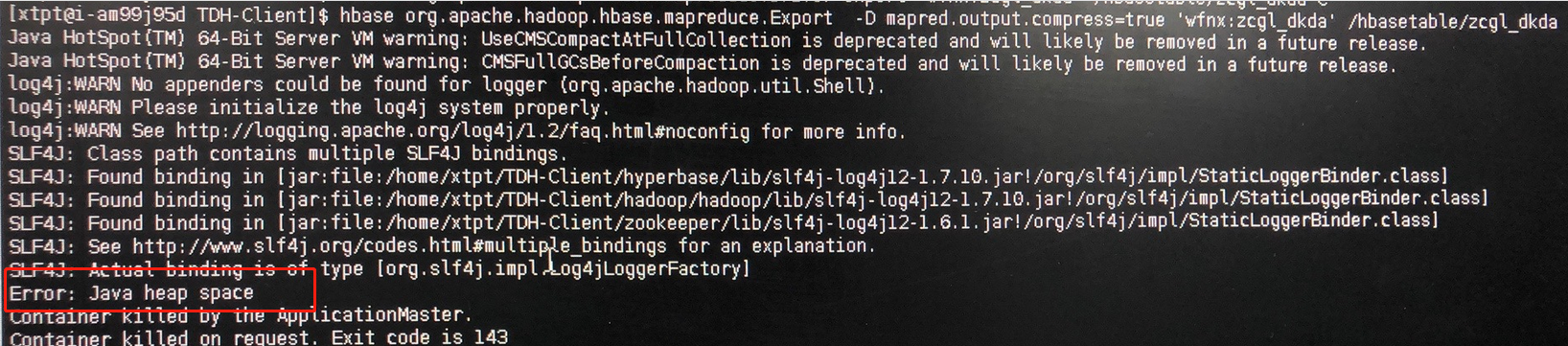
解决方案
导出命令中增加参数 -Dhbase.export.scanner.batch=2000 ,导出时可以限制scanner.batch的大小。 -
数据量很大的表(千万级别的数据量)在import导入的时候报错超时:
Error: org.apache.hadoop.hbase.client.RetriesExhaustedWithDetailsException: Failed 2882 actions: Operation Timeout: 2882 times, servers with issues: mll03,60020,1587435476220
Caused by: org.apache.hadoop.hbase.DoNotRetryIOException: Operation Timeout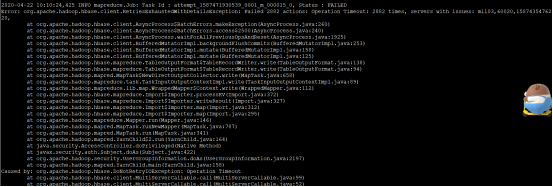
解决方案:
以下方法可以全部都尝试,也可以尝试其中一种。-
yarn资源调整
如果资源充裕,可以调大 yarn 服务的yarn.nodemanager.resource.memory-mb的配置,如果数据量真的很大,这个方法一般都不起作用。
调整配置之后,需要配置服务,重启yarn服务。

-
关闭WAL日志
在开了WAL之后,整体hbase负载很低,IO因素会比较高,且单行字节数越高,WAL影响越大。
当regionserver宕机时,关闭WAL会存在丢数据的风险,所以迁移完数据之后,需要打开WAL(在inceptor中删除添加的自定义参数,配置服务并重启inceptor服务)。
通过在inceptor中添加自定义参数hive.hbase.wal.enabled=false来关闭WAL的写入,添加自定义参数之后,需要配置服务,并重启inceptor服务。

-
调大flush的阈值
当Memstore中数据大小达到一定阈值(128M)之后,系统会异步将Memstore中数据flush到HDFS形成HFile小文件。
在manager管理页面中把hyperbase服务的hbase.hregion.memstore.flush.size该参数调整为 268435456 , 即flush调到256MB。
该参数的值在数据迁移完成之后需要还原到默认值。
在hyperbase中修改默认值,然后配置服务重启hyperbase服务。

-
调整compact文件合并
hyperbase中hbase.hstore.blockingStoreFiles该值默认是30,调大该值。
该参数的值在数据迁移完成之后需要还原到默认值。
在hyperbase中修改默认值,然后配置服务重启hyperbase服务。

-