概要描述
该工具用于从mysql中实时获取增量的数据(Insert,Update,Delete),然后将增量数据以OGG JSON的格式写到hdfs中,供tdt读取并同步到orc事务表。
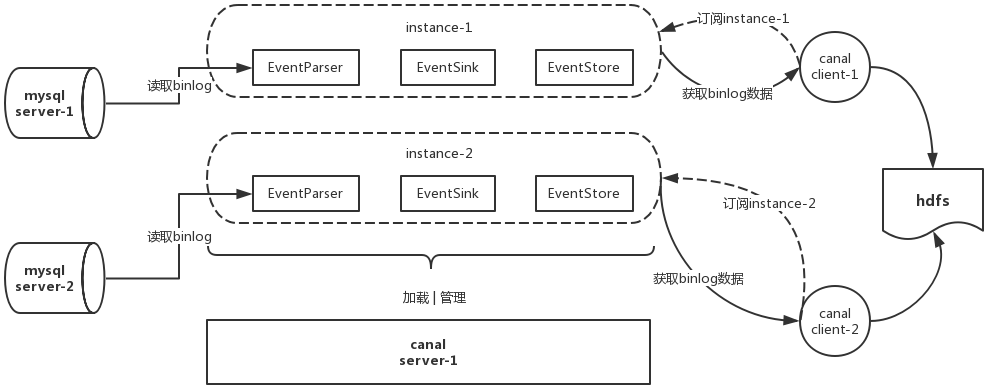
基于canal实现canal是alibaba开源的binlog抽取解析工具,canal提供server端实现,这里基于canal实现一种c/s模式的binlog订阅,然后放到hdfs中,供tdt读取。
- canal server : 用户的DML,DDL语句在mysql中都会产生binlog日志,canal server能够连接mysql并发送dump请求去获得binlog日志。
- instance : 这里称为一个同步实例,一个canal server可以加载n个同步实例,同步实例中配置了要同步的mysql源相关信息。client连接server后,应当订阅其中某一个instance,从这个instance获取数据。
- client client连接server,订阅instance,获取获得canal server解析过的binlog数据。有多种client,比如同步至关系型数据库的client,同步至hbase的client,同步至kafka的client,这里要使用的是同步至inceptor的client
- 整体理解: canal server负责加载instance,根据instance的配置从mysql获取binlog数据,一个canal server可以加载n个同步实例。而client负责订阅instance,根据业务需求将数据同步至不同地方。canal server和client解耦,可以分开部署。
技术概览:
- 开启MySQL的binary log日志记录
- 修改MySQL的binary log模式为ROW
- canal-server充当MySQL集群的一个slave,获取master的binary log信息
- canal-server将拿到的binary log信息推送给sync-client
- canal-server和sync-client采用多节点部署的方式提高可用性
- sync-client将json文件同步到hdfs集群
- transporter组件读取json文件同步到orc表
- workflow组件对transporter工作流实现准实时调度
架构图
详细说明
环境准备:
- TDH 5.2.2
- mysql 5.7
1. 配置canal server
1.1 准备工作
1.1.1 canal基于mysql的binlog功能,所以mysql需要开启binlog的写入功能,并且配置binlog模式为row。需要修改mysql的配置文件[mysqld文件],配置完成后重启mysql
[mysqld]
log-bin=mysql-bin #添加这一行就ok
binlog-format=ROW #选择row模式
server_id=1 #配置mysql replaction需要定义,不能和canal的slaveId重复1.1.2 在mysql客户端通过以下语句进行查询确认
show variables like 'binlog_format'; // 正确结果为 row
show variables like 'log_bin'; // 正确结果为 on1.1.3 在mysql上执行, canal是将自己伪装成slave向master请求binlog数据,因此需要给canal复制的权限
CREATE USER canal IDENTIFIED BY '1qaz!QAZ'; // 创建canal用户
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%'; // 赋予canal 用户权限
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES; // 让权限设置生效1.1.4 在mysql客户端通过以下语句进行查询确认:
show grants for 'canal';1.2 canal server配置
canal server的目录结构如下
canal server -
|- bin // canal server的启动、停止脚本目录
|- conf // canal server和instance的配置目录
|- lib // 相关依赖包存放目录
|- logs // canal server和instance的日志目录可以看到canal server和instance都在conf目录下进行配置,现在先关注canal server的配置,conf目录下的canal.properties即为canal server的配置文件,主要关注以下配置项:
- canal.id 默认是1 ,启动多个server时,可以依次使用1,2,…
- canal.ip canal server工作的ip,默认127.0.0.1,设置成server所在主机的ip
- canal.port canal server工作的端口,默认11111,可以设置成任何可用端口
- canal.instance.global.spring.xml instance的bean选择,默认为classpath:spring/file-instance.xml,会将同步位点写入本地文件系统
其余配置项保持默认即可,可以到官网查看其它配置项的含义:https://github.com/alibaba/canal/wiki/AdminGuide
2. 配置instance
server的加载基本对象是instance,instance配置文件中配置了同步的具体数据库、表。 conf目录内容如下:
conf -
|- canal.properties // canal server的配置文件
|- logback.xml // 日志配置文件
|- spring // java bean的配置文件存放目录,不要移动或修改
|- metrics // 暂时不用关注
|- example // 官方给出的一个默认instance的样例配置
|- instance.properties // example这个instance的配置文件可以看到官方给出了一个样例的instance,即一个名为example的文件夹,文件夹中保存着一个名为instance.properties的文件。按照canal server的默认配置,canal server会扫描conf目录下的所有文件夹,当发现某个文件夹下面存在instance.properties这个文件时,就将该文件夹识别为一个instance,该instance的名字即为文件夹的名字。所以官方给出的样例instance的名字即为example,其中的instance.properties即为这个instance的配置文件。该配置文件中关注以下配置项:
1. canal.instance.master.address, 必填项,被同步的数据库ip和端口
2. canal.instance.master.journal.name,选填项,指定要同步的binlog原始文件名,canal将从该文件开始往后解析,可以在mysql客户端中执行show binary logs来查看所有的binlog文件
3. canal.instance.master.position,选填项,指定binlog原始文件中的同步位点,canal 将从指定的binlog原始文件中的指定位点开始往后解析,只有在填写了上一个配置项之后才有意义。可以在mysql客户端执行show binlog events in 查看原始binlog文件中的具体内容,可以查到位点信息,但是不能查到时间
4. canal.instance.master.timestamp, 选填项,指定一个时间戳,该时间戳要在所有binlog原始文件中记录的时间范围内,canal将从这个时间戳最近的位置往后解析。在mysql所在机器的终端执行mysqlbinlog /命令来查看binglog文件中的信息,可查看到位点和时间信息
5. canal.instance.standby.address, 选填项,mysql slave的地址, master崩溃时会转向slave(目前canal server只支持一个slave)
6. canal.instance.dbUsername,必填项,访问数据库的用户名
7. canal.instance.dbPassword, 必填项,访问数据库的密码
8. canal.instance.filter.regex,二选一必填项,白名单正则表达式,能匹配该正则的库表都将进行同步
9. canal.instance.filter.black.regex,二选一必填项,黑名单正则表达式,匹配该正则的库表之外的所有库表都将进行同步 重要说明:
-
以上2、3、4三个配置项决定canal server从什么位置开始同步。2、3可以精确的确定一个位置;4可以模糊确定一个位置。但如果这三个选项都不填,则默认从canal server启动时的最新位点开始往后同步。附:关于mydql binlog的常用命令参考binlog
-
配置项8和9中填写的是定制的java正则表达式,分为三部分:[库正则][分隔符][表正则],分隔符固定为[.],多个正则之间以逗号[,]分隔, 常见例子:所有库所有表:.\..;test_db库下的所有表:test\..;test_db库下的所有以canal打头的表:test_db\.canal.;test_db库下的一张具体表test_table1:test_db\.test_table1;多个规则组合使用:test_db1\..*,test_db2\.test_table1,test_db2\.test_table2 (逗号分隔)
可以到官网查看instance所有配置项含义:https://github.com/alibaba/canal/wiki/AdminGuide
3. 配置sync client
sync client用于订阅instance,并将binlog数据解析成特定格式写入文件并上传到hdfs上,供TDT使用。sync client与canal server可以部署到不同机器上,只要保证机器能互相ping通即可。 sync client的目录结构如下所示:
sync client -
|- bin // sync client的启动、停止脚本目录
|- conf // sync client的配置文件目录
|- client-conf // client conf的配置文件存放的目录
|- sync-client.conf // 默认给出的client配置文件样例
|- logback.xml // 日志配置文件
|- hdfs-site.xml // 连接hdfs所需要的配置文件
|- core-site.xml // 连接hdfs所需要的配置文件
|- lib // 主运行程序存放目录
|- libext // 依赖包存放目录
|- logs // 日志存放目录,程序运行后自动生成,记录运行日志sync client需要连接hdfs,连接hdfs有两种方式,
第一种是RPC连接方式,适用于TDH集群的hdfs,这种连接方式需要将hdfs-site.xml和core-site.xml文件放入到conf目录下,如果hdfs开启了kerberos认证,还需要将krb5.conf文件放入到/etc目录下,需要将keytab文件放入到某个目录备用,使用klist命令查询keytab文件中的principal(该principal在hdfs上必须具有读写的权限),之后需要在sync client配置文件中填写这些信息。klist命令如下:
klist -kt 第二种连接方式是TCP连接方式,即使用httpfs,适用于TDC集群的hdfs,这种连接方式需要hdfs开启httpfs服务,需要在配置文件中填写外部可访问的httpfs的地址(可在TDC管理界面的hdfs服务信息获得),如果hdfs开启了kerberos认证,则还需要填写guardian_token(可在guardian管理界面获得)。
根据业务场景选择连接方式,然后开始填写sync client的配置文件。支持启动多个client,每个client使用不同的配置文件。 conf/client-conf目录下存放了这些配置文件,默认给出了一个配置文件样例sync-client.conf,各配置项含义如下
1. canal.server.ip canal server的ip,如果canal server配置了HA,可以填多个,以分号[;]进行分隔
2. canal.server.port canal server的端口号,如果canal server配置了HA,可以填多个,以分号[;]分隔,但必须与ip保持一一对应
3. canal.instance.list client订阅的instance列表,用分号[;]进行分隔
4. canal.instance.max.number client能订阅的instance最大数量,默认为100
5. canal.db.table.merge.rule 分库分表合并规则
6. canal.client.retry.time client遇到错误后重试次数,默认为3次
7. canal.file.max.records 生成的解析文件记录条数上限,默认为10万条
8. canal.file.flush.time 默认产生新的解析文件的频率,默认为60秒
9. canal.file.check.interval 默认的刷新频率,默认为1秒,不需要关注
10. canal.file.local.reserve.time 解析文件本地保留时间,默认是0,即不保留
11. canal.file.local.reserve.dir 解析文件的本地备份目录,需要设置为777的权限
12. canal.file.local.store.dir 解析文件的本地临时存储目录,默认为/tmp/binlogsync,需要设置为777的权限
13. canal.file.hdfs.target.dir 上传到hdfs的目录,开启安全情况下需要对principal具有写权限,没开安全情况下需要具有写权限
14. canal.hdfs.auth.mode hdfs的认证模式,有三种认证模式simple、kerberos以及token,默认为simple
15. canal.hdfs.principal 如果认证模式填写kerberos,则必须填写principal
16. canal.hdfs.keytab 如果认证模式填写kerberos,则必须填写keytab文件路径
17. canal.httpfs.address 如果认证模式填写token,将会以httpfs的方式访问hdfs,必须填写外部能访问的httpfs地址
18. canal.httpfs.token 如果认证模式填写token,并且集群开启了guardian,则必须填写guardian_token,如果集群没有开启guardian,则不用填写重要说明
1、第5条配置项,分库分表合并规则需要填写定制的正则表达式,分为三部分:[合并后的库表名][分隔符][库表正则表达式],分隔符默认为[:],多个规则之间以[;]分隔,注意合并后的库表名尽量不含有特殊字符,且是schema.table的格式。下面进行举例说明,假如现在有两个分库sync_db_01和sync_db_02,分表情况如下:
sync_db_01
|- table_a_01
|- table_b_01
sync_db_02
|- table_a_02
|- table_b_02要将sync_db_01.table_a_01和sync_db_02.table_a_02合并成sync_db.table_a,将sync_db_01.table_b_02和sync_db_02.table_b_02合并为sync_db.table_b,那么合并规则为:
sync_db.table_a:sync_db_[0-9]*.table_a_[0-9]*;sync_db.table_b:sync_db_[0-9]*.table_b_[0-9]*
2、第7和第8条配置项共同决定了解析文件的生成频率,两个条件满足其中一个就会生成一个新的解析文件,现场应该按照同步日志的生成速度自行把握,保持默认也可以
4. 启动步骤
4.1 启动canal server
在配置完canal server和instance之后就可以启动canal server了,在canal server的bin目录下面执行以下命令
bash startup.sh可以在logs目录中查看日志来确认canal server是否启动成功。 要停止canal server则运行命令bash stop.sh
4.2 启动sync client
在启动完canal server之后,就可以启动sync client了,在sync client的bin目录下面执行以下命令
nohup bash start-client.sh -f ../conf/client-conf/ > client.log 2>&1 & 可以在logs目录查看日志来确认sync client是否启动成功 client代码中注册时jvm hook实现优雅停机, 直接使用kill jvmid即可, 不建议使用kill -9 jvmid
5. 配置tdt数据流读取hdfs文件
参考如下数据流进行配置,JSON_SYNC_READER选择对应的hdfs目录,ORCTRANSACTIONSYNC_GENERIC_WRITER选择对应的表
6. workflow定时调度实现准实时导入
对发布的TDT工作流进行定时调度,可自定义同步频率实现准实时
7. 附录:
sync hdfs wirter中的目标路径填写规则示例:
.*..*:/tmp/test
解释:以冒号分隔,分为两部分,前面 ...是库表匹配的正则表达式,表示匹配所有库所有表, 后面/tmp/test是hdfs目录,所以这个的含义是将所有库所有表的同步日志都写到/tmp/hdfs目录下
多个设置可以用逗号分隔,示例:
canal_db..*:/tmp/canal,tdt_db..*:/tmp/tdt
解释:将canal_db这个库下的所有表的同步日志写到/tmp/canal目录下,将tdt_db这个库下的所有表写入到/tmp/tdt这个目录下