内容纲要
概要描述
排查问题时发现部分节点上的所有 pod 日志都无法查看,本文描述出现该情况的解决方法。
详细说明
1 故障场景
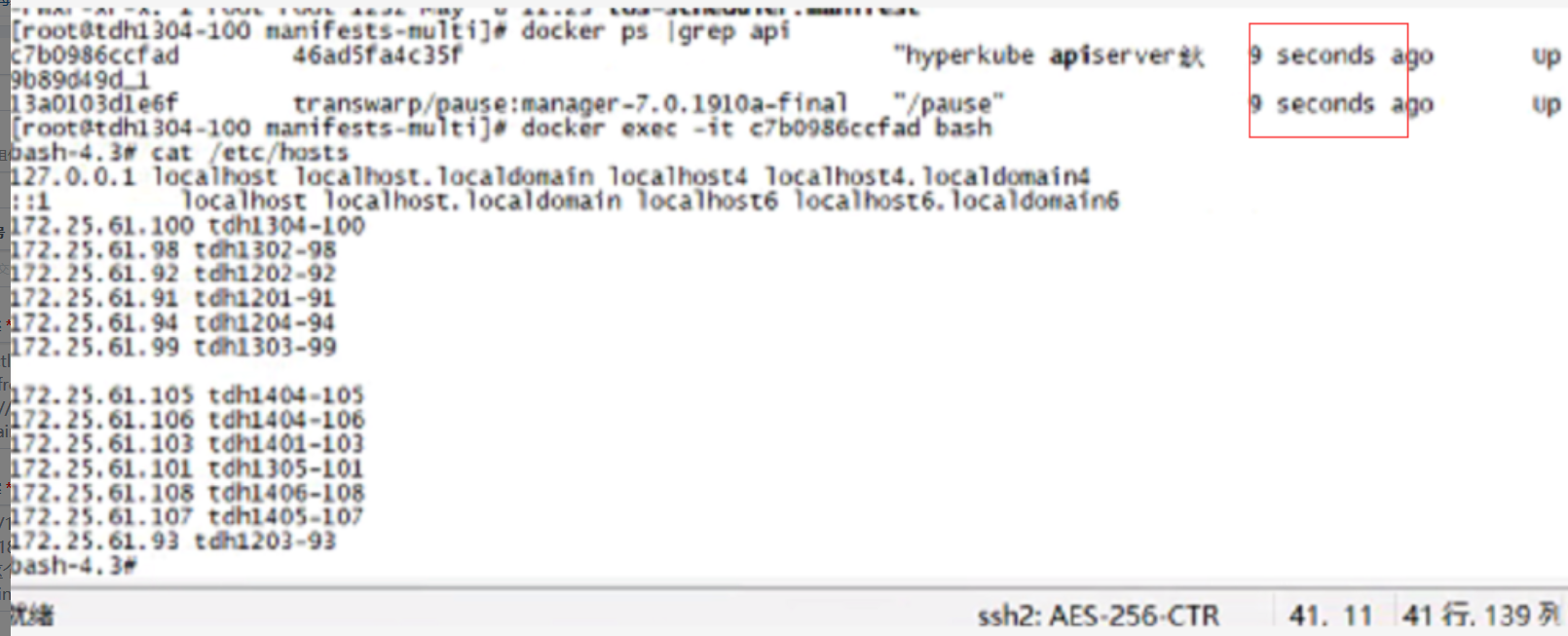
服务的 pod 实际运行正常,但是进行其他故障排查时发现,部分 ip 靠后节点上的所有 pod,使用 kubectl log <pod-id> 命令报错,报错如下:
[root@tdh1204-94 ~]# kubectl log workflow-server-workflow1-7c6f6c8866-nv4f8
Error from server: Get https://tdh1401-103:10250/containerLogs/default/workflow-server-workflow1-7c6f6c8866-nv4f8/workflow-server-workflow1: dial tcp: lookup tdh1401-103 on [::1]:53: read udp [::1]:48666->[::1]:53: read: connection refused2 确认集群状态
和负责集群人员沟通确认,该集群做过扩容节点的操作,无法查看日志的节点,均为扩容后添加的节点
3 问题原因
出现该情况的原因是 apiserver 所对应容器里的 /etc/hosts 信息记录不完全
4 修复方法
1 确认 apiserver 所在的 server 信息,查看 TOS 角色信息能得知 3 个节点部署了 apiserver 的 pod
$ kubectl get pods -owide -n kube-system | grep apiserver2 分别 ssh 登录这三台服务器,执行
$ docker ps | grep apiserver
3 分别进入相关的 container 内,查看 /etc/hosts 信息
$ docker exec -it bash
$ cat /etc/hosts 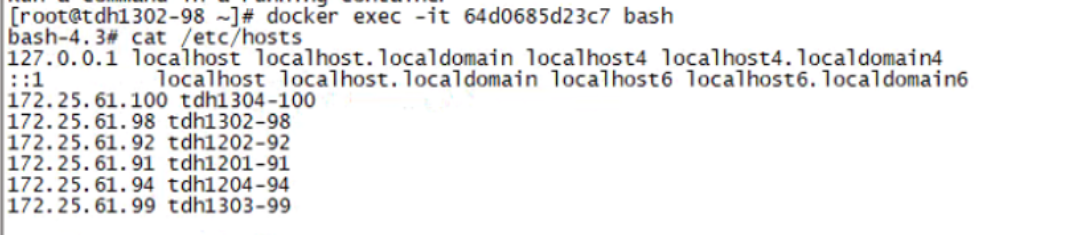
4 记录正常的 /etc/hosts 信息应当如下,对比可以看出 apiserver 的 container 内 /etc/hosts 信息有很多缺失,且缺失部分所在节点均无法正常查看 pod 日志

5 在 apiserver 的 container 内直接修改 hosts 信息
$ docker exec -it bash
$ vi /etc/hosts /etc/hosts 文件添加缺失节点的 ip 和 hostname 映射
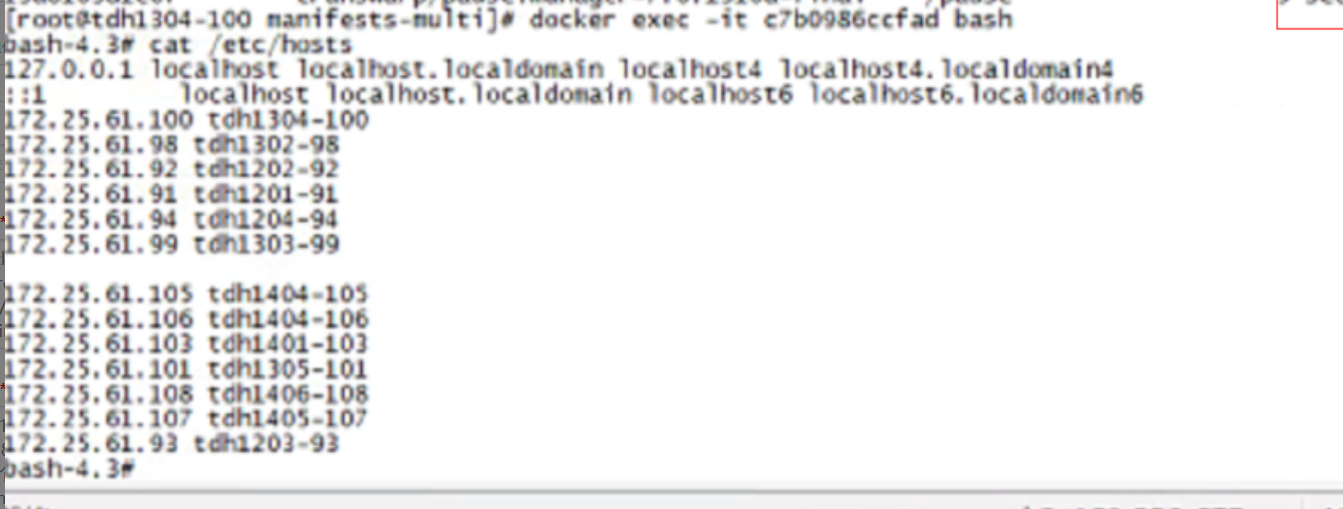
6 经过验证,在 container 内修改后,即使重启该 container,/etc/hosts 信息仍然会保留