概要说明
线上长时间运行的大规模Hadoop集群,各个datanode节点磁盘空间使用率经常会出现分布不均衡的情况,尤其在新增和下架节点、或者人为干预副本数量的时候。节点空间使用率不均匀会导致计算引擎频繁在跨节点拷贝数据(A节点上运行的task所需数据在其它节点上),引起不必要的耗时和带宽。
详细说明
当部分节点空间使用率很高但未满(90%左右)时,分配在该节点上的task会存在任务失败的风险。因此,引入balance策略使集群中的节点空间使用率均匀分布必不可少。
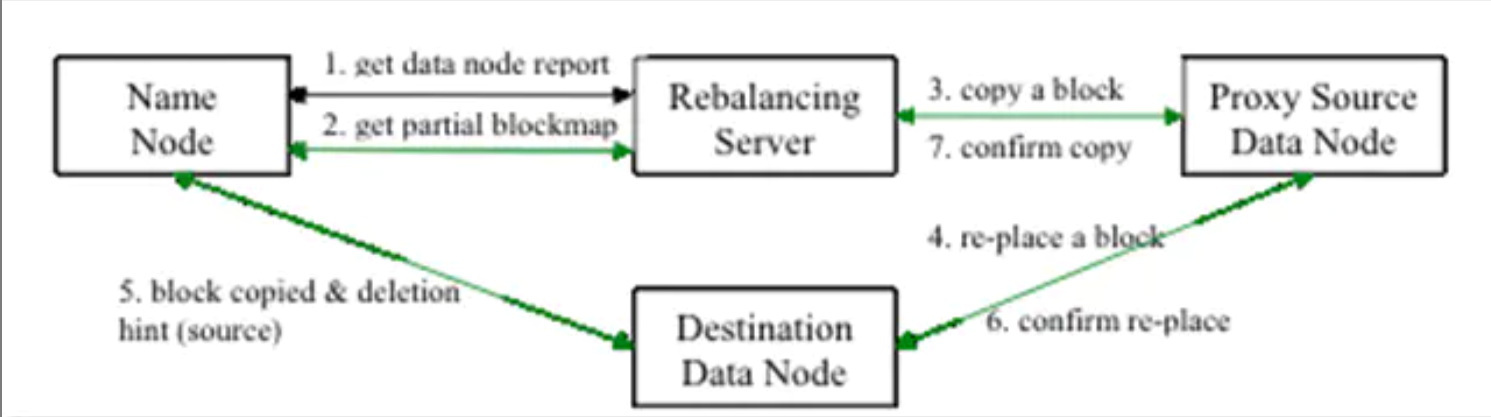
Rebalance程序作为一个独立的进程与name node进行分开执行。
1 Rebalance Server从Name Node中获取所有的Data Node情况:每一个Data Node磁盘使用情况。
2 Rebalance Server计算哪些机器需要将数据移动,哪些机器可以接受移动的数据。并且从Name Node中获取需要移动的数据分布情况。
3 Rebalance Server计算出来可以将哪一台机器的block移动到另一台机器中去。
4,5,6 需要移动block的机器将数据移动的目的机器上去,同时删除自己机器上的block数据。
7 Rebalance Server获取到本次数据移动的执行结果,并继续执行这个过程,一直没有数据可以移动或者HDFS集群以及达到了平衡的标准为止。
1.Balance命令详解
Usage: hdfs balancer
[-policy ] the balancing policy: datanode or blockpool
[-threshold ] Percentage of disk capacity
[-exclude [-f | ]] Excludes the specified datanodes.
[-include [-f | ]] Includes only the specified datanodes.
[-idleiterations ] Number of consecutive idle iterations (-1 for Infinite) before exit.
[-runDuringUpgrade] Whether to run the balancer during an ongoing HDFS upgrade.This is usually not desired since it will not affect used space on over-utilized machines.
Generic options supported are
-conf specify an application configuration file
-D use value for given property
-fs specify a namenode
-jt specify a ResourceManager
-files specify comma separated files to be copied to the map reduce cluster
-libjars specify comma separated jar files to include in the classpath.
-archives specify comma separated archives to be unarchived on the compute machines.
The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions] 参数举例说明:
hdfs balancer
-threshold 10 \\集群平衡的条件,datanode间磁盘使用率相差阈值,区间选择:0~100
-policy datanode \\默认为datanode,datanode级别的平衡策略
-exclude -f /tmp/ip1.txt \\默认为空,指定该部分ip不参与balance, -f:指定输入为文件
-include -f /tmp/ip2.txt \\默认为空,只允许该部分ip参与balance,-f:指定输入为文件
-idleiterations 5 \\迭代次数,默认为 52.Balance退出条件
- The cluster is balanced;
- No block can be moved;
- No block has been moved for specified consecutive iterations (5 by default);
- An IOException occurs while communicating with the namenode;
- Another balancer is running.
3.统计参与balancer的datanode
- 1.忽略退役节点
- 2.忽略正在退役的节点
- 3.忽略-exclude里面包含的节点
- 4.忽略不在-include里面的节点
4.相关参数和阈值的计算规则
集群平均使用率(计算公式):average = totalUsedSpaces * 100 / totalCapacities
totalUsedSpaces:各datanode已使用空间(dfsUsed,不包含non dfsUsed)相加;
totalCapacities:各datanode总空间(DataNode配置的服务器磁盘目录)相加;
单个datanode使用率:utilization = dfsUsed * 100.0 / 该节点capacity;
dfsUsed:当前datanode dfs(dfsUsed,不包含non dfsUsed)已使用空间;
capacity:当前datanode(DataNode配置的服务器磁盘目录)总空间;
单个datanode使用率与集群平均使用率差值:utilizationDiff = utilization – average
单个datanode utilizationDiff与阈值的差值: thresholdDiff = |utilizationDiff| – threshold
某个datanode需要迁移或者可以迁入的空间:maxSize2Move = |utilizationDiff| * capacity
可以迁入的空间计算:Math.min(remaining, maxSizeToMove)
需要迁移的空间计算:Math.min(max, maxSizeToMove)
remaining: datanode节点剩余空间
max: 默认单个datanode单次balance迭代可以迁移的最大空间限制,缺省10G)
默认迭代次数为5,即运行一次balance脚本,单个datanode可以最大迁移的空间为:5*10G = 50G
overUtilized:utilizationDiff > 0 && thresholdDiff > 0 <使用率超过平均值,且差值大于阈值>
aboveAvgUtilized:utilizationDiff > 0 && thresholdDiff <= 0 <使用率超过平均值,且差值小于等于阈值>
belowAvgUtilized:utilizationDiff < 0 && thresholdDiff <= 0 <使用率低于平均值,且差值小于等于阈值>
underUtilized:utilizationDiff > 0 && thresholdDiff > 0 <使用率低于平均值,且差值大于等于阈值>
数据迁移配对(原则:1. 优先为同机架,其次为其它机架; 2. 一对多配对):
第一步[Source -> Target]:each overUtilized datanode => one or more underUtilized datanodes
第二步[Source -> Target]:match each remaining overutilized datanode => one or more belowAvgUtilized datanodes
第三步[Target -> Source]:each remaining underutilized datanode (step 1未和overUtilized匹配过) => one or more aboveAvgUtilized datanodes
操作步骤
1. 设置balancer的传输带宽
开启安全需要先进行kinit hdfs认证:
$ kinit hdfs
$ hadoop dfsadmin -setBalancerBandwidth xxxx未开启安全需要先export:
$ export HADOOP_USER_NAME=hdfs
$ hdfs dfsadmin -setBalancerBandwidth xxxxxxx代表设置的带宽值,默认为1048576,即1MB/s,这个需要根据自己的机器以及网络配置来进行设置
2. 页面上先确认下当前datanode的空间使用情况:
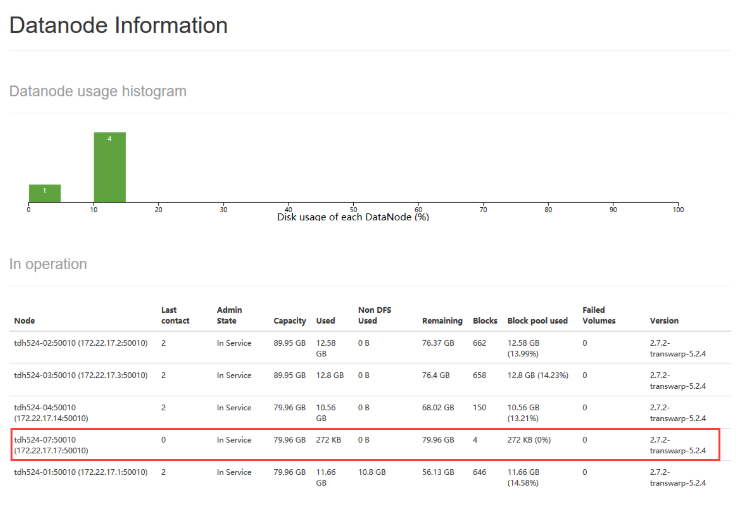
此时可以看到,新加的datanode使用率基本为0
3. 执行balancer:
$ hdfs balancer -threshold 1如果当前集群有若干datanode空间快满,建议将threshold设置为比较大的值,这样会优先从使用率比较高的节点往新节点平衡。如果是平时正常时候的建议设置为10%左右。
4. balance完成后验证结果
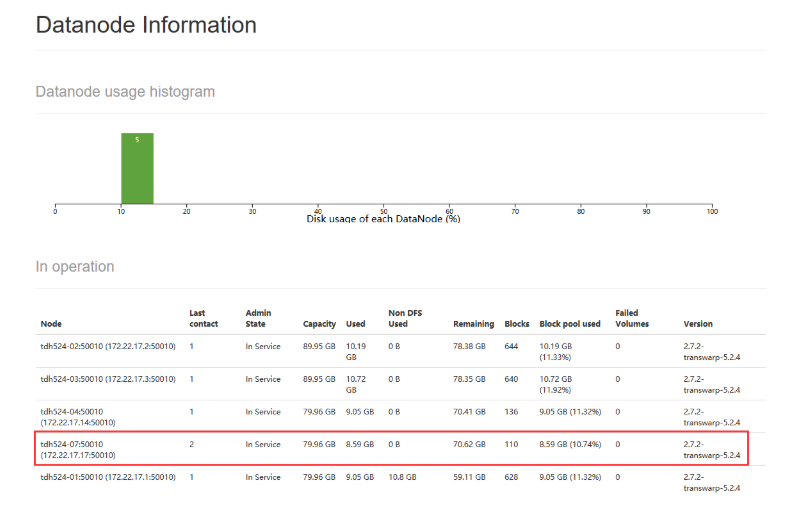
此时可以看到,各个节点基本均衡,如果对均衡结果不满意,可以尝试再次执行balance命令
FAQ
1. 如果集群本身吞吐量很大或者数据量很大,可能均衡效果不是很好,需要多执行几次
2. 如果需要balance的数据量非常大,平衡速度远远达不到要求
可以尝试采取退役对应的datanode,然后格式化对应的数据存储磁盘,然后重新添加节点的方法。如果采取此种方法,理论上为了数据安全,同时退役的节点数不能超过默认的副本数(默认是3),即同时退役的最大节点数为2。