内容纲要
概要说明
本案例描述如何将流上数据落入到分区分桶表中。
注意事项:
- 分区表目前只支持对TEXT表、ORC表、CSV表和Holodesk表分区。
- 实验环境已开启安全
详细说明
1、通过kafka获取实时的流数据
开启安全的环境,slipstream如何接收kafka数据,参考文档:kafka开启Guardian安全后Slipstream接收Kafka消息操作步骤
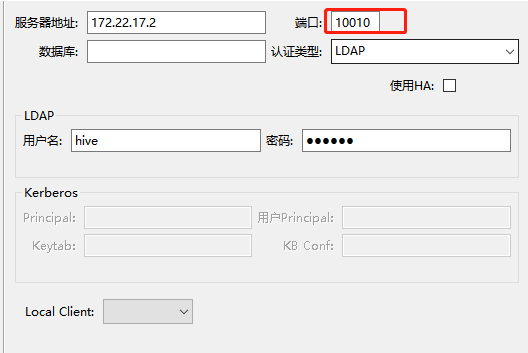
2、连接slipstream,通过SQL消费数据
本实验用waterdrop工具连接slipstream,注意端口号是 10010。
3、创建输入流
CREATE STREAM test_bucket(id INT,sex STRING, letter STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
TBLPROPERTIES("topic"="luoyang",
"kafka.zookeeper"="tdh524-03:2181,tdh524-02:2181,tdh524-01:2181",
"kafka.broker.list"="tdh524-03:9092,tdh524-02:9092,tdh524-01:9092",
"transwarp.consumer.security.protocol"="SASL_PLAINTEXT",
"transwarp.consumer.sasl.kerberos.service.name"="kafka",
"transwarp.consumer.sasl.jaas.config"="com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true storeKey=true keyTab=\"/etc/slipstream1/conf/kafka.keytab\" principal=\"kafka@TDH\""
);4、创建orc单值分区表
CREATE TABLE orc_bucket_table(id INT,sex STRING,letter string)
PARTITIONED BY (p_sex string)
CLUSTERED BY (id) INTO 3 BUCKETS STORED AS ORC
tblproperties("transactional"="true");5、创建StreamJob
CREATE STREAMJOB o1 AS (
"insert into orc_bucket_table PARTITION(p_sex)
select id,sex,letter,sex from test_bucket")
jobPROPERTIES("hive.exec.dynamic.partition"="TRUE","hive.enforce.bucketing"="true","morphling.result.auto.flush"="true");说明:
- hive.exec.dynamic.partition : 开启动态分区;
- hive.enforce.bucketing : 打开enforce bucketing开关,强制Slipstream分桶。这个开关默认情况下是打开的,但是可能在Slipstream使用过程中被关掉,所以向分桶表导数据前,请确保开关是打开的;
- morphling.result.auto.flush : 是否自动Sink。开启该开关后,只要有数据产生就立刻flush到目标表;
6、验证
-
登录4044查看streamjob正常运行

-
kafka生产数据

-
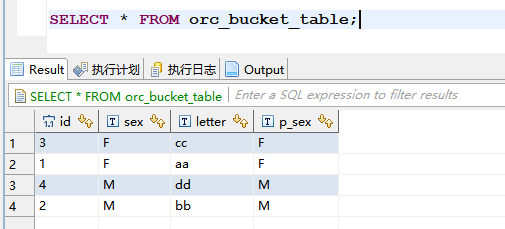
表中查看数据是否已落表
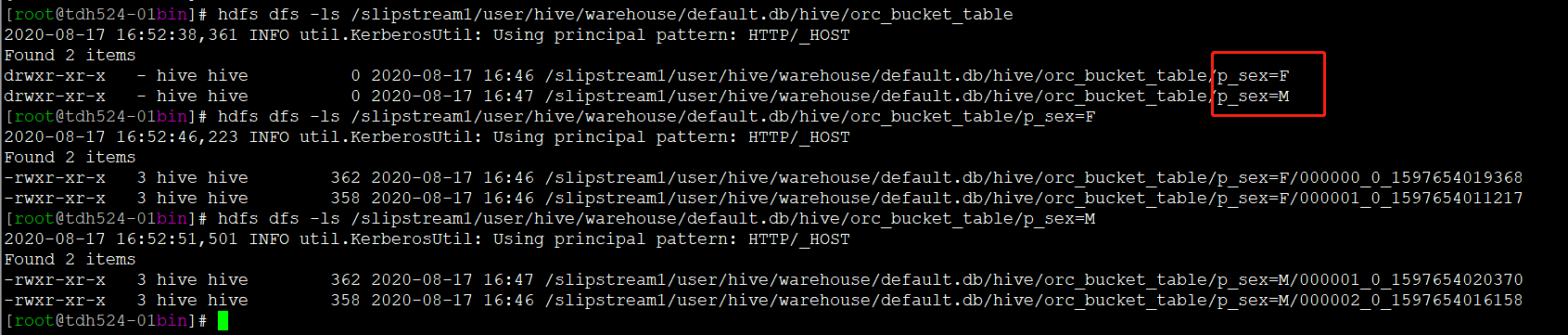
-
hdfs上验证分区分桶文件存储正常