概要描述
search数据迁移主要方式:
- 通过Data Migration Tool,参考 <search运维手册> ,但该迁移方式经可能不太稳定,特别是数据量较大的情况下;
- 本案例讲述通过hdfs插件repository-hdfs进行迁移:通过snapshot的方式将search数据导入hdfs中,再从hdfs中将数据重入search中。
使用前说明:
- 不论是同一集群还是不同集群间备份还原或迁移,集群都是关闭kerberos安全认证的;
- TDH从5.1版本开始对应开源的ElasticSearch的版本都是5.4.1,所以只要是TDH5.1以上的版本之间都是可以通过该方式来迁移数据的;
- 本案例讲述从TDH5.2.3版本迁移数据到TDH6.2.1版本
- 环境说明
TDH5.2.3为源集群:172.22.33.33/xixia01、172.22.33.34/xixia02、172.22.33.35/xixia03
TDH6.2.1为目标集群:172.22.33.1/mll01、172.22.33.2/mll02、172.22.33.3/mll03
详细说明
安装hdfs插件repository-hdfs
注意:
以下步骤除额外说明,每一步骤都要在各集群所有search相关节点都操作;
本步骤演示在TDH6.2.1版本安装插件,其他版本类似的步骤。
-
下载HDFS插件
从TDH5.1开始,search中使用的ElasticSearch的版本都是5.4.1,所以本案例我们下载repository-hdfs-5.4.1的包;
官网下载地址:https://artifacts.elastic.co/downloads/elasticsearch-plugins/repository-hdfs/repository-hdfs-5.4.1.zip ;
本地附件地址:repository-hdfs-5.4.1.zip -
解压 repository-hdfs-5.4.1.zip 插件包,解压后会生成elasticsearch的目录
unzip repository-hdfs-5.4.1.zip
mv elasticsearch repository-hdfs- 将repository-hdfs拷贝到search plugin路径下
TDH6.2.1对应的路径是:/etc/search1/instancegroup1/conf/plugins/
TDH5.2.3对应的路径是:/etc/search1/conf/plugins/

- 在manager节点修改 jvm.options 模板配置文件,避免在操作过程中出现 JVM 的 JSM 安全校验导致的报错
模板文件路径是:/var/lib/transwarp-manager/master/content/meta/services/SEARCH/transwarp-6.2.1-final/templates/jvm.options(不同版本,注意修改成对应的版本号)
在文件末尾加入配置内容:
-Djava.security.policy=/etc/search1/instancegroup1/conf/plugins/repository-hdfs/plugin-security.policy
plugin-security.policy文件所对应的路径以实际为准;

- 配置服务,重启search服务,安装插件完成
创建Repository,在源集群和目标集群各⾃创建repository
- TDH6.2.1目标集群创建repository
curl -X PUT "localhost:9200/_snapshot/geo_repository" -H 'Content-Type:application/json' -d '
{
"type":"hdfs",
"settings":{
"uri":"hdfs://mll02:8020",
"path":"/user/backup",
"max_snapshot_bytes_per_sec":"500mb",
"max_restore_bytes_per_sec":"500mb",
"compress":"true",
"conf_location":"/root/TDH-Client/conf/hdfs1/hdfs-site.xml"}}'
- uri: hdfs active namenode的IP或主机名;
- path: hdfs上的目录,创建的snapshot保存在该目录下,确保 **elasticsearch** 用户对该目录有 **write** 权限;
- max_snapshot_bytes_per_sec、max_restore_bytes_per_sec、compress : 控制snapshot创建时的速度;
- conf_location : 指定配置文件;- TDH5.2.3源集群创建repository
curl -X PUT "localhost:9200/_snapshot/geo_repository" -H 'Content-Type:application/json' -d '
{
"type":"hdfs",
"settings":{
"uri":"hdfs://xixia02:8020",
"path":"/user/backup",
"max_snapshot_bytes_per_sec":"500mb",
"max_restore_bytes_per_sec":"500mb",
"compress":"true",
"conf_location":"/root/TDH-Client/conf/hdfs1/hdfs-site.xml"}}'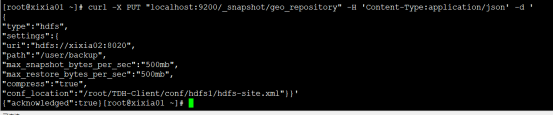
生成 snapshot
- 在TDH5.2.3源集群创建snapshot
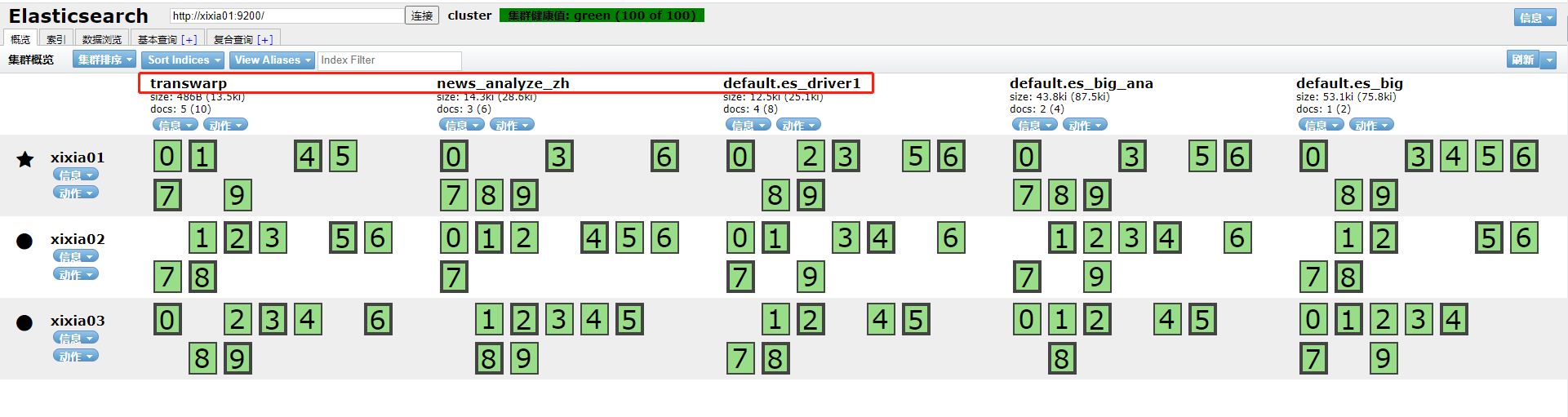
本案例测试将源集群TDH5.2.3环境中的 transwarp、news_analyze_zh、default.es_driver1 三个index迁移到目标集群TDH6.2.1环境中。
TDH5.2.3源集群search页面index信息如下:
curl -XPUT "172.22.33.33:9200/_snapshot/geo_repository/geo_snapshot_v?wait_for_completion=true" -H 'Content-Type:application/json' -d '{
"indices":"transwarp,news*,default.es*",
"ignore_unavailable":"true",
"include_global_state":"false"
}'- indices : 可以指定具体的index,以逗号分隔,也可以正则匹配;
- wait_for_completion=true : 如果不希望备份操作以后台方式运行,而是希望在前台发送请求时等待备份操作执行完成,添加该参数;
- ignore_unavailable : 如果设置为true的话,那么那些不存在的index就会被忽略掉。默认情况下,这个参数是不设置的,那么此时如果某个index丢失了,会导致备份过程失败;
- include_global_state : 可以阻止cluster的全局state也作为snapshot的一部分被备份;上述命令执行没有报错表示执行成功,可以在hdfs对应路径上看到生成的snapshot信息:
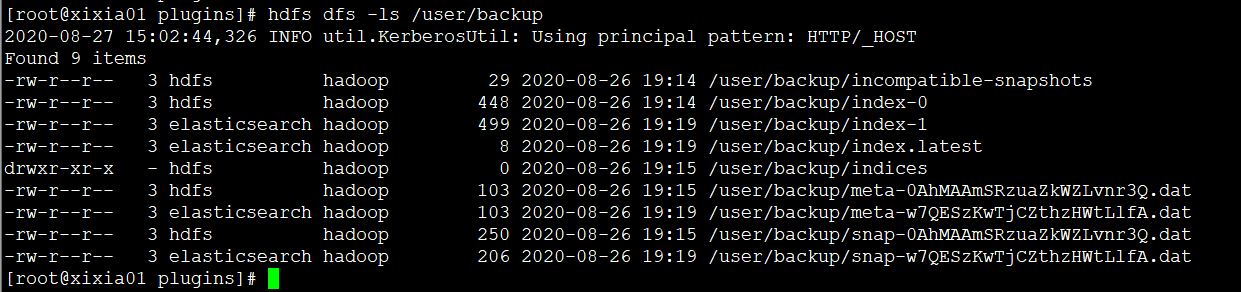
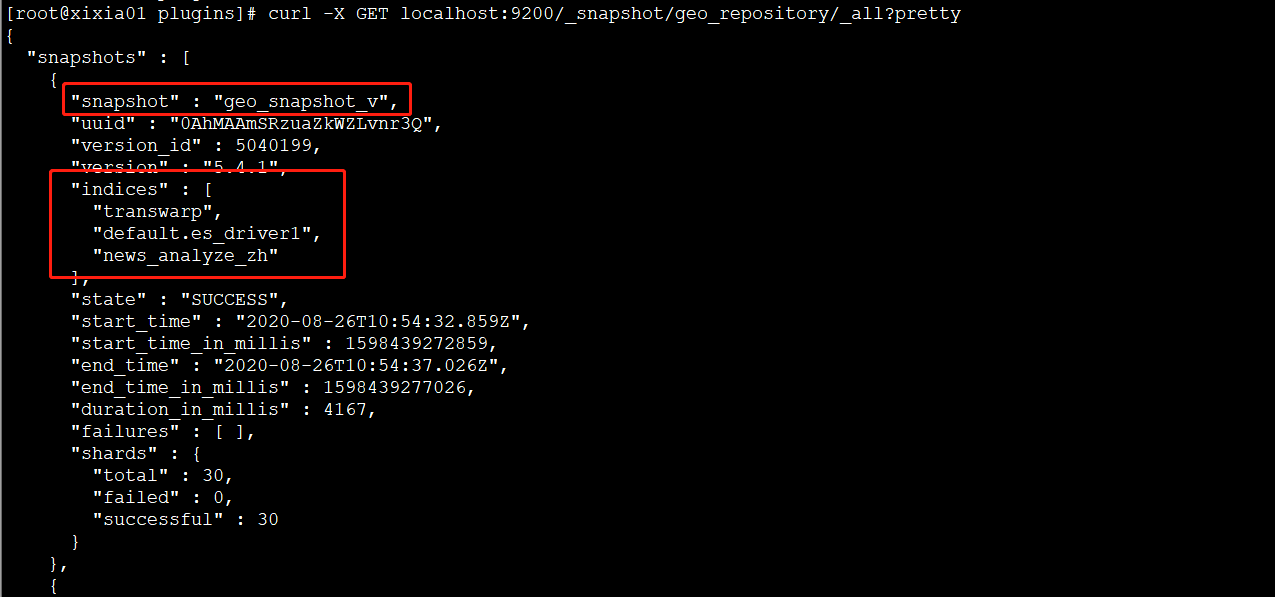
也可以通过curl命令查看所有snapshot:
curl -X GET localhost:9200/_snapshot/geo_repository/_all?pretty可以看到geo_snapshot_v下面已经有了transwarp、news_analyze_zh、default.es_driver1 三个index的snapshot了。
copy snapshot
- 将源集群TDH5.2.3hdfs上/user/backup目录下的所有文件拷贝到目标集群TDH6.2.1环境创建repository时指定的hdfs路径下
本案例中,源集群TDH5.2.3和目标TDH6.2.1创建repository时指定的hdfs路径都是 /user/backup 。
拷贝完成后,目标集群TDH6.2.1环境hdfs上/user/backup内容如下,应该和源集群内容是保持一致的:
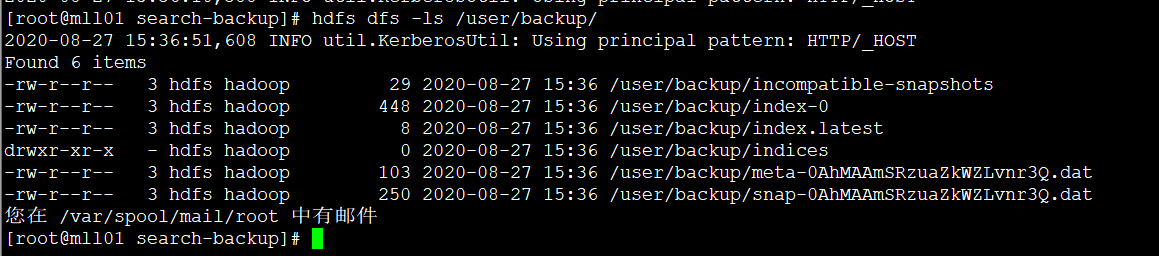
同步完hdfs上数据之后,可以在目标集群通过 curl 命令查看所有的 snapshot
curl -X GET localhost:9200/_snapshot/geo_repository/_all?pretty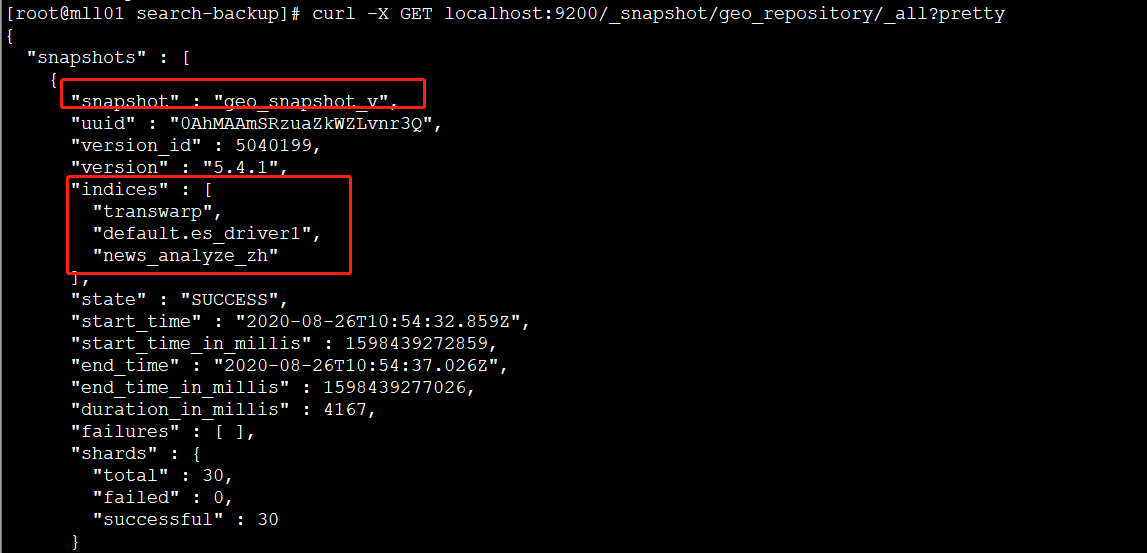
在TDH6.2.1目标集群上通过snapshot恢复数据
TDH6.2.1目标集群search页面index信息如下:
通过以下命令恢复数据:
curl -X POST "172.22.33.1:9200/_snapshot/geo_repository/geo_snapshot_v/_restore?wait_for_completion=true" -H 'Content-Type:application/json' -d '{
"indices":"news_analyze_zh,transwarp,default.es_driver1",
"ignore_unavailable":"true",
"include_global_state":"false"
}'- wait_for_completion=true : restore过程也是在后台运行的,如果要在前台等待它运行完,添加该参数;
- indices : 可以指定具体的index,以逗号分隔,也可以正则匹配。 
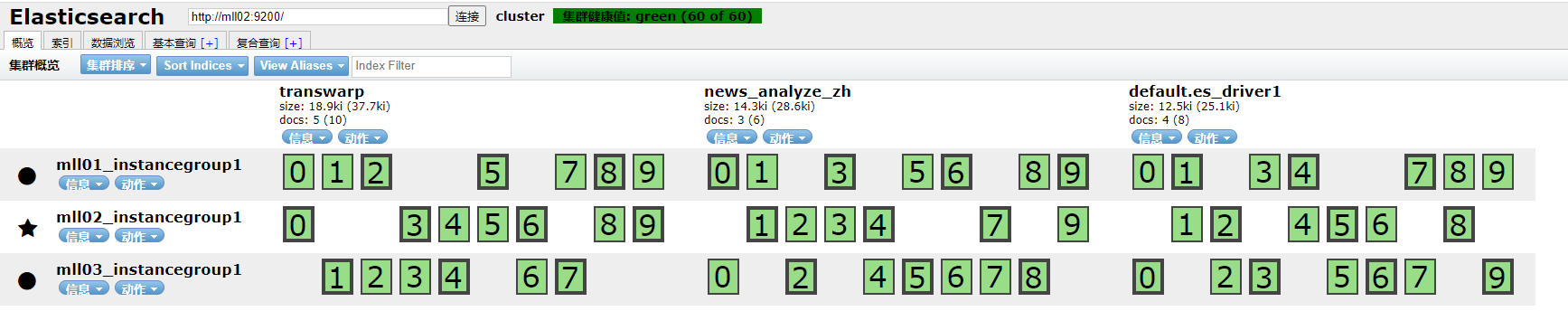
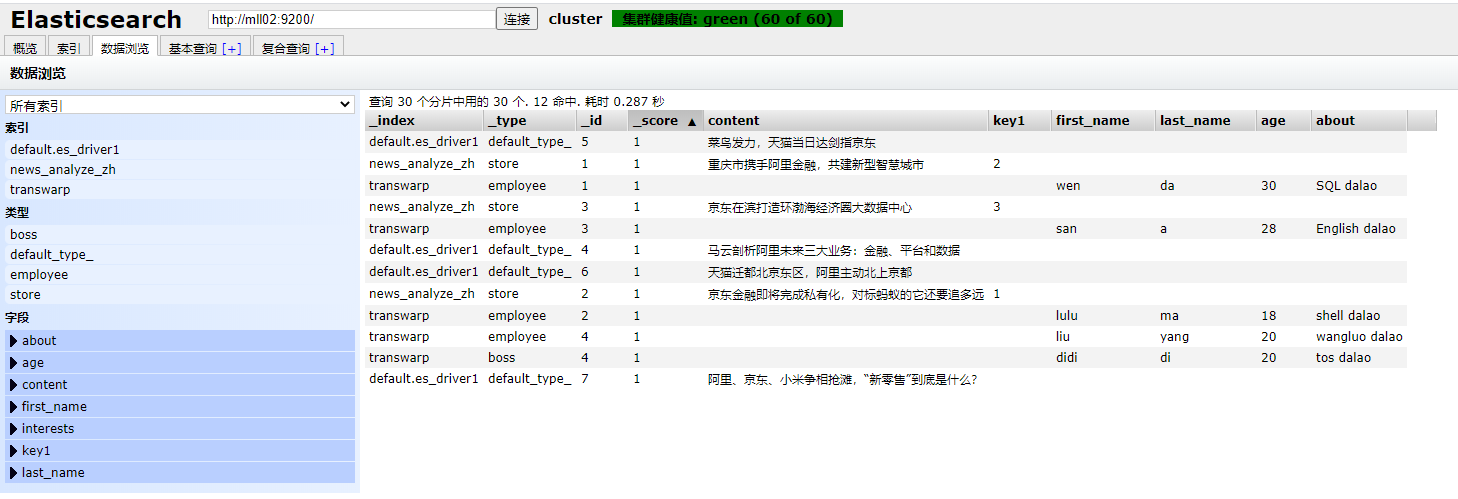
然后在search页面查看数据:
常见问题
- 部署完插件重启search时启动失败,查看pod日志报错如下
Caused by: java.nio.file.FileSystemException: /usr/lib/elasticsearch/elasticsearch-5.4.1-transwarp/plugins/repository-hdfs-5.4.1.zip/plugin-descriptor.properties: Not a directory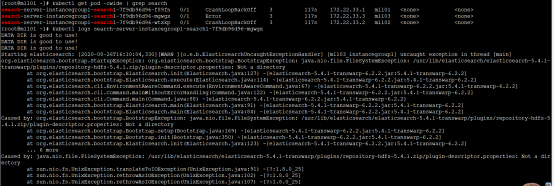
解决方案:检查search plugin目录下是不是没有删除repository-hdfs-5.4.1.zip压缩包,该目录下不能有压缩包,只需要保留解压后的文件夹即可。
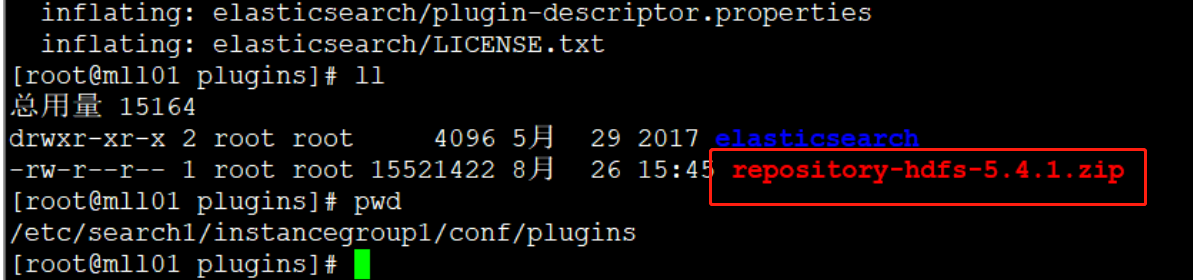
- 部署完插件重启search,netstat -anpl | grep 9200 查看端口没有监听,查看search server的pod报错
Caused by: java.lang.IllegalStateException: jar hell!
class: org.apache.commons.logging.impl.AvalonLogger
jar1: /usr/lib/elasticsearch/elasticsearch-5.4.1-transwarp/plugins/elasticsearch/commons-logging-1.1.3.jar
jar2: /usr/lib/elasticsearch/elasticsearch-5.4.1-transwarp/lib/commons-logging-1.2.jar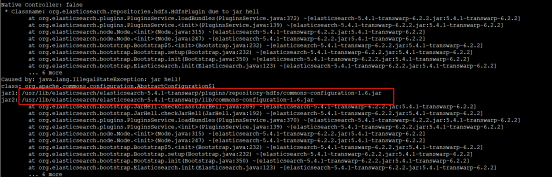
解决方案:jar包有冲突,对比两个目录下的jar包,将search plugin目录下所有重复的包都移走
TDH6.2.1search plugin目录:/etc/search1/instancegroup1/conf/plugins/repository-hdfs
TDH6.2.1自带的jar,pod内的路径:/usr/lib/elasticsearch/elasticsearch-5.4.1-transwarp/lib/
- 创建repository时报错如下
{"error":{"root_cause":[{"type":"repository_exception","reason":"[geo_repository] failed to create repository"}],"type":"repository_exception","reason":"[geo_repository] failed to create repository","caused_by":{"type":"unchecked_i_o_exception","reason":"Cannot create HDFS repository for uri [hdfs://xixia01:8020]","caused_by":{"type":"remote_exception","reason":"Operation category WRITE is not supported in state standby\n\tat org.apache.hadoop.hdfs.server.namenode.ha.StandbyState.checkOperation(StandbyState.java:87)解决方案:创建repository时指定的uri需要是hdfs当前active的namenode节点
- 创建repository时报错信息如下
{"error":{"root_cause":[{"type":"repository_exception","reason":"[geo_repository] failed to create repository"}],"type":"repository_exception","reason":"[geo_repository] failed to create repository","caused_by":{"type":"unchecked_i_o_exception","reason":"Cannot create HDFS repository for uri [hdfs://xixia02:8020]","caused_by":{"type":"i_o_exception","reason":"com.google.protobuf.ServiceException: java.security.AccessControlException: access denied (\"javax.security.auth.PrivateCredentialPermission\" \"org.apache.hadoop.security.Credentials\" \"read\")","caused_by":{"type":"service_exception","reason":"java.security.AccessControlException: access denied (\"javax.security.auth.PrivateCredentialPermission\" \"org.apache.hadoop.security.Credentials\" \"read\")","caused_by":{"type":"access_control_exception","reason":"access denied (\"javax.security.auth.PrivateCredentialPermission\" \"org.apache.hadoop.security.Credentials\" \"read\")"}}}}},"status":500}解决方案:检查manager节点模板文件 /var/lib/transwarp-manager/master/content/meta/services/SEARCH/transwarp-6.2.1-final/templates/jvm.options 中指定的 plugin-security.policy 文件是否正确。
- 创建repository时报错信息如下
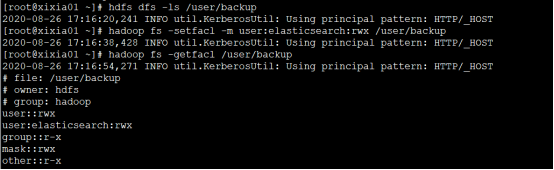
{"error":{"root_cause":[{"type":"exception","reason":"failed to create blob container"}],"type":"exception","reason":"failed to create blob container","caused_by":{"type":"access_control_exception","reason":"Permission denied: user=elasticsearch, access=WRITE, inode=\"/user/backup\":hdfs:hadoop:drwxr-xr-x\n\tat org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:324)\n\tat org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:223)\n\tat org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:199)\n\tat org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1771)\n\tat org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1755)\n\tat org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1738)\n\tat org.apache.hadoop.hdfs.server.namenode.FSDirMkdirOp.mkdirs(FSDirMkdirOp.java:69)\n\tat org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:3946)\n\tat org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:981)\n\tat org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:634)\n\tat org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)\n\tat org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:616)\n\tat org.apache.hadoop.ipc.RPC$Server.call(RPC.java:969)\n\tat org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2217)\n\tat org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2213)\n\tat java.security.AccessController.doPrivileged(Native Method)\n\tat javax.security.auth.Subject.doAs(Subject.java:415)\n\tat org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1988)\n\tat org.apache.hadoop.ipc.Server$Handler.run(Server.java:2211)\n","caused_by":{"type":"remote_exception","reason":"Permission denied: user=elasticsearch, access=WRITE, inode=\"/user/backup\":hdfs:hadoop:drwxr-xr-x\n\tat org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:324)\n\tat org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:223)\n\tat org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:199)\n\tat org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1771)\n\tat org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1755)\n\tat org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1738)\n\tat org.apache.hadoop.hdfs.server.namenode.FSDirMkdirOp.mkdirs(FSDirMkdirOp.java:69)\n\tat org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:3946)\n\tat org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:981)\n\tat org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:634)\n\tat org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)\n\tat org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:616)\n\tat org.apache.hadoop.ipc.RPC$Server.call(RPC.java:969)\n\tat org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2217)\n\tat org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2213)\n\tat java.security.AccessController.doPrivileged(Native Method)\n\tat javax.security.auth.Subject.doAs(Subject.java:415)\n\tat org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1988)\n\tat org.apache.hadoop.ipc.Server$Handler.run(Server.java:2211)\n"}}},"status":500}解决方案:elasticsearch用户对repository中指定的path没有写权限;
通过如下命令加入权限:
hadoop fs -setfacl -m user:elasticsearch:rwx /user/backup