内容纲要
概要描述
客户业务场景中经常会使用到对text表或者orc普通表并发insert写入的场景,经常性的会报类似下面的错误:
ERROR i.t.workflow.job.AbstractJob - Failed to create or execute SQL statement
java.sql.SQLException: EXECUTION FAILED: Task EXEC PLSQL error HiveException: [Error 20534] copyFiles:
error while moving files!!! Cannot move hdfs://nameservice1/inceptor1/tmp/hive/hive/0a12df97-a3d1-4c26-be3f-ea83d0172667/hive_2020-09-18_06-04-11_508_8113783901299179345-6766/-ext-10000/000001_0 to hdfs://nameservice1/inceptor1/user/hive/warehouse/jx3600tmp.db/hive/tmp_apps_lp_nx_pjlpzq2_d/000001_0_copy_4用jmeter批量构造小文件场景时也可以复现该问题;20个并发,循环1000次,预期应该是20000条数据,而实际插入只有12845条,可见该问题影响还是蛮严重的。
本文通过jmeter工具复现该场景,并结合日志剖析异常出现的场景,并给出最终解释,希望能以更清晰的方式给客户以解释。
场景复现
0. 新建一张ORC普通表EMP_ORC
CREATE TABLE EMP_ORC(
EMPNO int,
ENAME string,
JOB string,
MGR INT,
HIREDATE DATE,
SAL INT,
COMM INT,
DEPTNO INT
)STORED AS ORC;1. jmeter用例配置
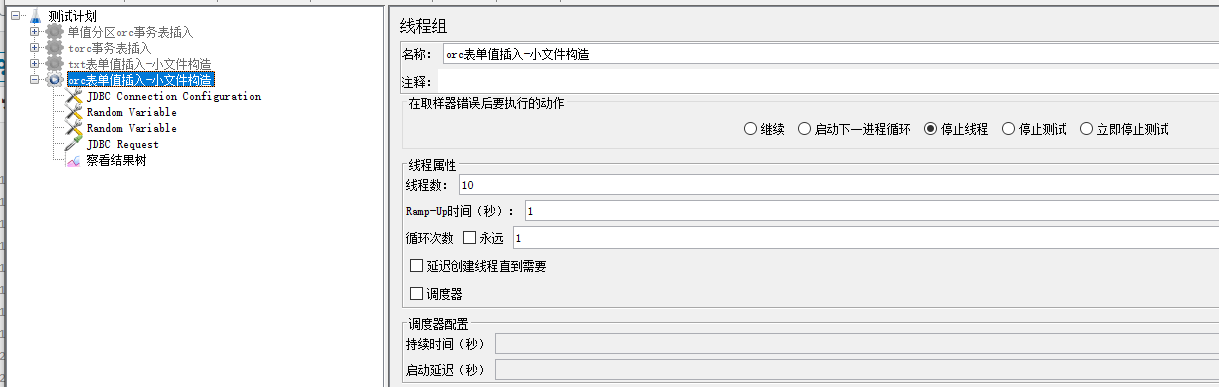
- 线程属性:线程数10,循环次数1,取样器执行错误之后停止线程
- JDBC Connection Configuration:以LDAP方式连接inceptor
- JDBC Request:通过Random Variable来随机定义2个列值
INSERT INTO EMP_ORC SELECT ${singleP},'SMITH','CLERK',${randomValue},tdh_todate('17-12-1980','dd-mm-yyyy'),800,NULL,20 FROM system.dual; - 察看结果树:检查每个取样器的请求和响应数据
2. 测试执行
10次请求中有一次返回了错误
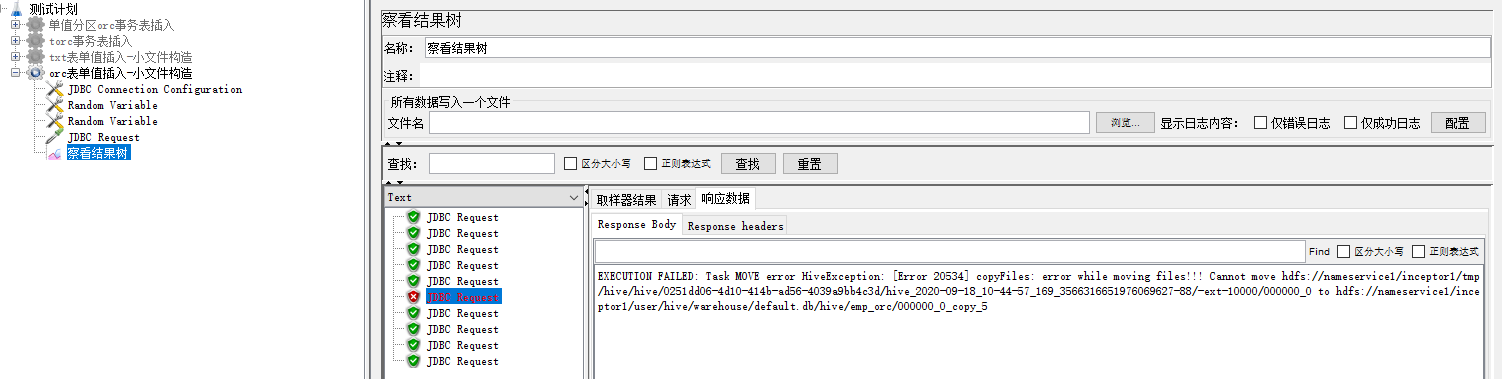
EXECUTION FAILED: Task MOVE error HiveException: [Error 20534] copyFiles: error while moving files!!!
Cannot move hdfs://nameservice1/inceptor1/tmp/hive/hive/0251dd06-4d10-414b-ad56-4039a9bb4c3d/hive_2020-09-18_10-44-57_169_3566316651976069627-88/-ext-10000/000000_0
to
hdfs://nameservice1/inceptor1/user/hive/warehouse/default.db/hive/emp_orc/000000_0_copy_5server日志通过"Renaming src"搜索,在数据文件目录下000000_0_copy_5有一次成功一次失败的记录:

详细说明
原因如下:
- 上面的插入语句都是往表的数据目录下插入,对应hdfs的同一个目录。
- 每个插入语句会生成一个文件000000_0并放在session的临时目录。此时,4040执行已经结束。
- SQL执行的最后一步需要把临时目录下的文件move到对应的hdfs目录。这个过程会检查 “目标目录下有没有重名的文件”。
但在并发环境下,几个操作同时检查,都认为没有000000_0,大家在把自己的000000_0 move到同一个目录时就冲突了。
解决办法:
- text和orc普通表都会有该问题,建议使用orc事务表。orc事务表在每次insert操作的时候都会形成一个delta目录,不会造成文件冲突,不过也要提防小文件过多的问题;
- 如果坚持使用text表或者orc普通表的话,可以使用insert union all的方式。