概要描述
MapJoin是Hive的一种优化操作,其适用于小表JOIN大表的场景,由于表的JOIN操作是在Map端且在内存进行的,所以其并不需要启动Reduce任务也就不需要经过shuffle阶段,从而能在一定程度上节省资源提高JOIN效率。
可以有如下2种方式触发mapjoin
- 手工加Mapjoin hint的方式
- 自动转换的方式
- SET ngmr.mapjoin.autoconvert :控制开关,默认为true
- SET hive.mapjoin.smalltable.filesize: :根据小表在HDFS上的大小判断是否做mapjoin
而通过自动转换的方式大家可以看到,由于ORC文件是zlib列式存储下压缩的,通常在3X左右,如果库里面有大量重复的数据,压缩比会非常高,导致一个千万行的表被作为小表,当建Hash表时,内存就爆掉了,这也是触发executor异常最主要的场景之一。
本文主要围绕这个故障场景案例从实际场景的角度进行故障排查,希望能够加深大家对该问题的理解。
故障现象
SQL执行报错,
Job aborted due to stage failure: Task 4 in stage 466.2 failed 4 times, most recent failure: Lost task 4.3 in stage 466.2 (TID 10312, 10.50.52.35): ExecutorLostFailure (executor lost)
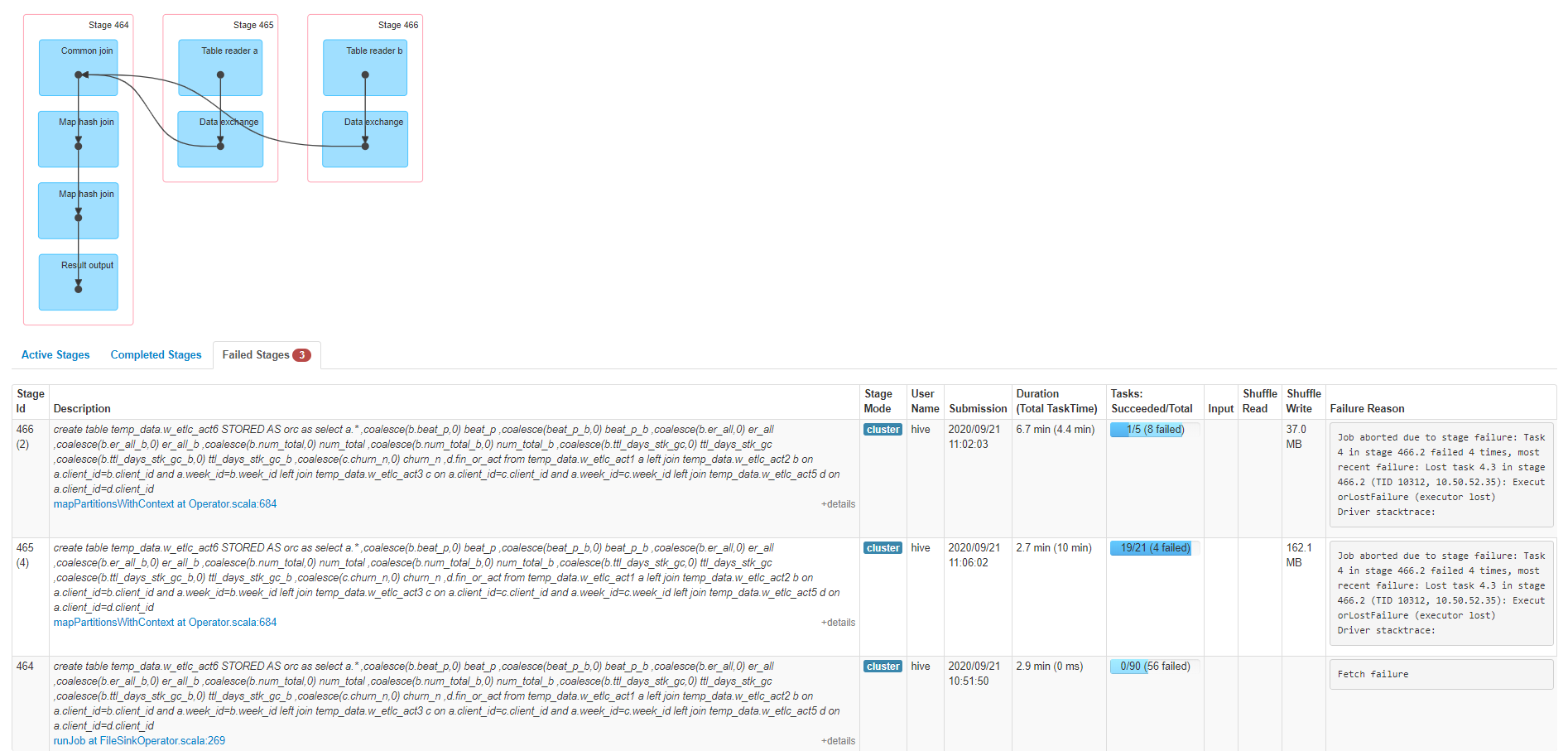
执行的sql语句:
create table
temp_data.w_etlc_act6 STORED
AS orc
as
select a.* ,
coalesce(b.beat_p,0) beat_p ,
coalesce(beat_p_b,0) beat_p_b ,
coalesce(b.er_all,0) er_all ,
coalesce(b.er_all_b,0) er_all_b ,
coalesce(b.num_total,0) num_total ,
coalesce(b.num_total_b,0) num_total_b ,
coalesce(b.ttl_days_stk_gc,0) ttl_days_stk_gc ,
coalesce(b.ttl_days_stk_gc_b,0) ttl_days_stk_gc_b ,
coalesce(c.churn_n,0) churn_n ,
d.fin_or_act
from temp_data.w_etlc_act1 a
left join temp_data.w_etlc_act2 b
on a.client_id=b.client_id and a.week_id=b.week_id
left join temp_data.w_etlc_act3 c
on a.client_id=c.client_id and a.week_id=c.week_id
left join temp_data.w_etlc_act5 d
on a.client_id=d.client_id故障排查
1. executor日志分析
一般来说,导致executor发生full GC的情况比较少,最常见的就是mapjoin的小表太大了,导致executor端构建的小表hashtable太大,造成内存使用爆炸。
通过关键字"SmallTable disk size "在executor日志中进行搜索,由于hive.mapjoin.smalltable.filesize参数默认为25M,所以1767917.2822265625 KBytes这种超过1G,executor基本就挂了。
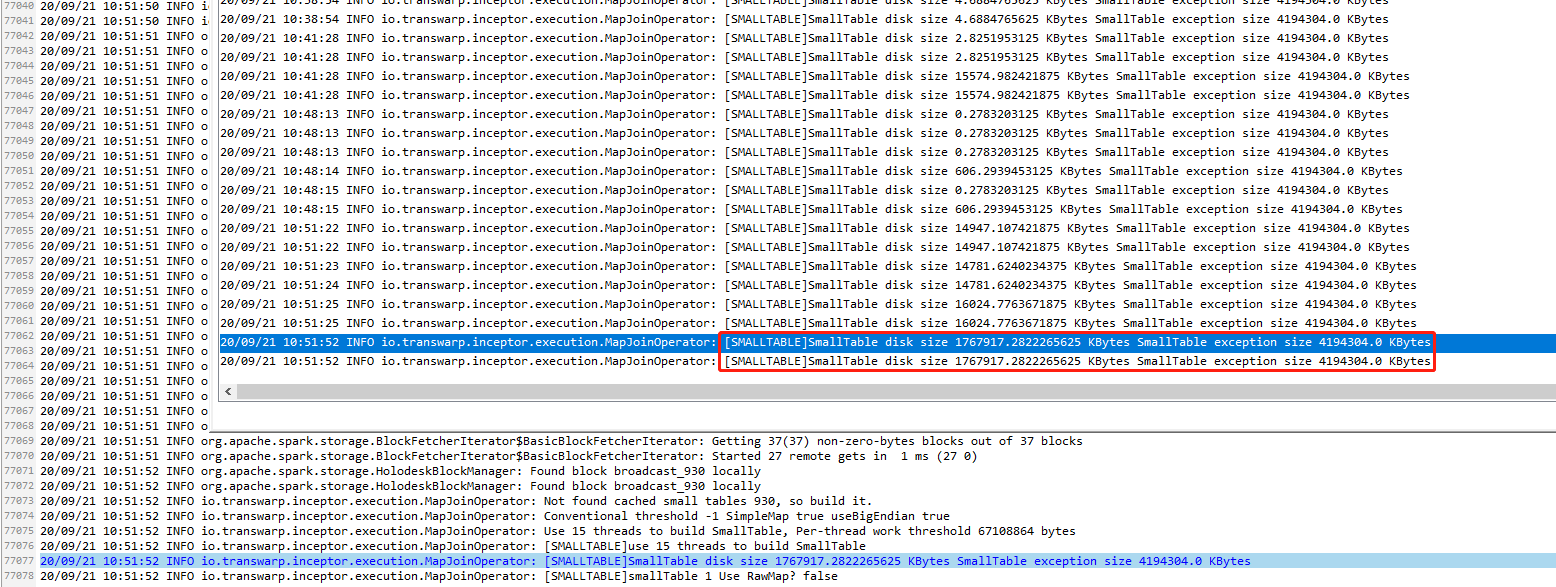
2. server日志分析
通过关键字"For mapjoin autoconvert"在executor日志中进行搜索获取到join的4张表在hdfs中的大小,另外结合analyze命令获取numFiles、numRows、totalSize等信息
| TableName | numFiles | NumRows | TotalSize(byte) | TotalSize(Mb) |
|---|---|---|---|---|
| temp_data.w_etlc_act1 | 90 | 54279997 | 164577007 | 157 |
| temp_data.w_etlc_act2 | 37 | 54859009 | 135889449 | 129 |
| temp_data.w_etlc_act3 | 62 | 54859009 | 13908288 | 13.2 |
| temp_data.w_etlc_act5 | 30 | 654587 | 3573763 | 3.40 |
Map Join Converter: Table temp_data.w_etlc_act1 => 164577007.
Map Join Converter: Table temp_data.w_etlc_act2 => 1358894492.
For mapjoin autoconvert, the size of two join tables is 164577007 and 1358894492
Map Join Converter: Table temp_data.w_etlc_act3 => 13908288.
For mapjoin autoconvert, the size of two join tables is 3046942998 and 13908288
Map Join Converter: Table temp_data.w_etlc_act5 => 3573763.
For mapjoin autoconvert, the size of two join tables is 6121702572 and 3573763
temp_data.w_etlc_act3小表显示仅仅只有13.3M,也就是说在HDFS中实际存储13.3M,但是在executor中占用了1.68G,猜测该表压缩比非常高,重复数据很多.
3. 检查表的重复率
检查表的重复率的方法,这里列举2种
a、利用compute_stats函数获取struct中的numdistinctvalues,数值/总条数的比率越少,代表重复率越高
select
compute_stats(column_1).numdistinctvalues,
compute_stats(column_2).numdistinctvalues,
compute_stats(column_3).numdistinctvalues
...
from temp_data.w_etlc_act3;b、利用analyze table … for columns 命令对表进行元数据分析,将结果生成到元数据表
ANALYZE TABLE temp_data.w_etlc_act3 compute statistics for columns;然后到元数据中关联查询
select t.TBL_NAME '表名',
d.NAME '库名',
tcs.COLUMN_NAME '字段名',
NUM_NULLS*1.0/tp.numRows '空值率',
1-NUM_DISTINCTS*1.0/tp.numRows '重复字段占比'
from DBS d
/*DBS的主键DB_ID*/
inner join TBLS t
on d.DB_ID = t.DB_ID
inner join TAB_COL_STATS tcs
on t.TBL_ID=tcs.TBL_ID
left join (
select TBL_ID,
/*文件存储的大小*/
max(case PARAM_KEY when 'numRows'
then PARAM_VALUE else 0 end) numRows
/*TABLE_PARAMS 记录的表属性*/
from TABLE_PARAMS
GROUP BY TBL_ID
) tp
on t.TBL_ID=tp.TBL_ID
where d.NAME='temp_data' and t.TBL_NAME='w_etlc_act3';客户根据方法1获取到temp_data.w_etlc_act3表3列数据的列重复值数量,表总条数54859009行,week_id和churn_n列的值只有不到100个,压缩比很高
> select
compute_stats(client_id).numdistinctvalues,
compute_stats(week_id).numdistinctvalues,
compute_stats(churn_n).numdistinctvalues
from temp_data.w_etlc_act3;
+--------------------+--------------------+--------------------+
| numdistinctvalues | numdistinctvalues | numdistinctvalues |
+--------------------+--------------------+--------------------+
| 808974 | 93 | 20 |
+--------------------+--------------------+--------------------+
1 row selected (3.916 seconds)解决方法
为了避免出现上述问题,高版本inceptor降低了参数 hive.mapjoin.smalltable.filesize 的值,从原来的 25000000 降低到 5000000,很大程度上避免了该问题的发生。
退化到 common join,如果出现计算倾斜问题,可以考虑 新版本的 skewjoin 功能。