概要描述
当在生产环境中,我们可能会定期从与业务相关的关系型数据库向Hadoop导入数据,导入数仓后进行后续离线分析。这种情况下我们不可能将所有数据重新再导入一遍,所以此时需要数据增量导入。
增量导入数据分为两种方式:
- 一是基于递增列的增量数据导入(Append方式)
- 二是基于时间列的数据增量导入(LastModified方式)
详细说明
1. 方式一:Append方式
比如:有一个订单表,里面每个订单有一个唯一标识自增列ID,在关系型数据库中以主键形式存在,之前已经将id在1-3的编号的订单导入到了Hive中,现在一段时间后我们需要将近期产生的新的订单数据(id为4、5的两条数据)导入Hdfs,供后续数仓进行分析。此时我们只需要指定-incremental参数为append,-last-value参数为3即可。表示只从大于3后开始导入。
重要参数说明:
| 参数 | 说明 |
|---|---|
| –incremental append | 基于递增列的增量导入(将递增列值大于阈值的所有数据增量导入hdfs) |
| –check-column | 递增列(int) |
| –last-value | 阈值(int) |
1.1 Oracle建表
CREATE TABLE appendTest (
id int,
name varchar2(255)
) ;1.2 导入数据
insert into appendTest(id,name) values(1,'name1');
insert into appendTest(id,name) values(2,'name2');
insert into appendTest(id,name) values(3,'name3');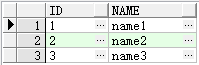
1.3 增量导入
#将id>0的三条数据进行导入
sqoop import \
--connect jdbc:oracle:thin:@172.22.23.9:1521/helowin \
--username lkw \
--password 123456 \
--query "select * from lkw.appendtest where \$CONDITIONS" \
--hive-drop-import-delims \
--null-string '\\N' \
--null-non-string '\\N' \
-m 1 \
--target-dir /tmp/tb01 \
--incremental append \
--check-column id \
--last-value 0 执行日志:
[root@tdh70001 ~]# sqoop import --connect jdbc:oracle:thin:@172.22.23.9:1521/helowin --username lkw --password 123456 --query "select * from lkw.appendtest where \$CONDITIONS" --hive-drop-import-delims --null-string '\\N' --null-non-string '\\N' -m 1 --target-dir /tmp/tb01 --incremental append --check-column id --last-value 0
Warning: /root/TDH-Client/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /root/TDH-Client/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /root/TDH-Client/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
2020-10-16 11:05:23,178 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5-transwarp-6.0.0
2020-10-16 11:05:23,212 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
2020-10-16 11:05:23,492 INFO oracle.OraOopManagerFactory: Data Connector for Oracle and Hadoop is disabled.
2020-10-16 11:05:23,510 INFO manager.SqlManager: Using default fetchSize of 1000
2020-10-16 11:05:23,510 INFO tool.CodeGenTool: Beginning code generation
2020-10-16 11:05:24,896 INFO manager.OracleManager: Time zone has been set to GMT
2020-10-16 11:05:25,024 INFO manager.SqlManager: Executing SQL statement: select * from lkw.appendtest where (1 = 0)
2020-10-16 11:05:25,036 INFO manager.SqlManager: Executing SQL statement: select * from lkw.appendtest where (1 = 0)
2020-10-16 11:05:25,063 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /root/TDH-Client/hadoop/hadoop-mapreduce
注: /tmp/sqoop-root/compile/d3b276c99c456cdef55c926825eea1b7/QueryResult.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
2020-10-16 11:05:26,512 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/d3b276c99c456cdef55c926825eea1b7/QueryResult.jar
2020-10-16 11:05:26,756 INFO util.KerberosUtil: Using principal pattern: HTTP/_HOST
2020-10-16 11:05:27,783 INFO tool.ImportTool: Maximal id query for free form incremental import: SELECT MAX(id) FROM (select * from lkw.appendtest where (1 = 1)) sqoop_import_query_alias
2020-10-16 11:05:27,785 INFO tool.ImportTool: Incremental import based on column id
2020-10-16 11:05:27,785 INFO tool.ImportTool: Lower bound value: 0
2020-10-16 11:05:27,785 INFO tool.ImportTool: Upper bound value: 3
2020-10-16 11:05:27,787 INFO mapreduce.ImportJobBase: Beginning query import.
2020-10-16 11:05:27,801 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
2020-10-16 11:05:27,814 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
2020-10-16 11:05:28,465 INFO hdfs.DFSClient: Created HDFS_DELEGATION_TOKEN token 272 for hdfs on ha-hdfs:nameservice1
2020-10-16 11:05:28,494 INFO security.TokenCache: Got dt for hdfs://nameservice1; Kind: HDFS_DELEGATION_TOKEN, Service: ha-hdfs:nameservice1, Ident: (HDFS_DELEGATION_TOKEN token 272 for hdfs)
2020-10-16 11:05:28,551 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
2020-10-16 11:05:30,616 INFO db.DBInputFormat: Using read commited transaction isolation
2020-10-16 11:05:30,797 INFO mapreduce.JobSubmitter: number of splits:1
2020-10-16 11:05:31,041 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1600851944038_0014
2020-10-16 11:05:31,041 INFO mapreduce.JobSubmitter: Kind: HDFS_DELEGATION_TOKEN, Service: ha-hdfs:nameservice1, Ident: (HDFS_DELEGATION_TOKEN token 272 for hdfs)
2020-10-16 11:05:31,662 INFO impl.YarnClientImpl: Submitted application application_1600851944038_0014
2020-10-16 11:05:31,721 INFO mapreduce.Job: The url to track the job: http://tdh70002:8088/proxy/application_1600851944038_0014/
2020-10-16 11:05:31,722 INFO mapreduce.Job: Running job: job_1600851944038_0014
2020-10-16 11:05:41,987 INFO mapreduce.Job: Job job_1600851944038_0014 running in uber mode : false
2020-10-16 11:05:41,989 INFO mapreduce.Job: map 0% reduce 0%
2020-10-16 11:05:50,114 INFO mapreduce.Job: map 100% reduce 0%
2020-10-16 11:05:51,130 INFO mapreduce.Job: Job job_1600851944038_0014 completed successfully
2020-10-16 11:05:51,310 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=144786
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=24
HDFS: Number of read operations=4
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=5692
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=5692
Total vcore-milliseconds taken by all map tasks=5692
Total megabyte-milliseconds taken by all map tasks=5828608
Map-Reduce Framework
Map input records=3
Map output records=3
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=48
CPU time spent (ms)=1470
Physical memory (bytes) snapshot=279994368
Virtual memory (bytes) snapshot=4757753856
Total committed heap usage (bytes)=635437056
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=24
2020-10-16 11:05:51,319 INFO mapreduce.ImportJobBase: Transferred 24 bytes in 23.4942 seconds (1.0215 bytes/sec)
2020-10-16 11:05:51,324 INFO mapreduce.ImportJobBase: Retrieved 3 records.
2020-10-16 11:05:51,345 INFO util.AppendUtils: Creating missing output directory - tb01
2020-10-16 11:05:51,374 INFO tool.ImportTool: Incremental import complete! To run another incremental import of all data following this import, supply the following arguments:
2020-10-16 11:05:51,374 INFO tool.ImportTool: --incremental append
2020-10-16 11:05:51,374 INFO tool.ImportTool: --check-column id
2020-10-16 11:05:51,374 INFO tool.ImportTool: --last-value 3
2020-10-16 11:05:51,374 INFO tool.ImportTool: (Consider saving this with 'sqoop job --create')
结果
[root@tdh70001 ~]# hadoop fs -cat /tmp/tb01/part-m-00000
2020-10-16 11:06:27,085 INFO util.KerberosUtil: Using principal pattern: HTTP/_HOST
1,name1
2,name2
3,name3此时向表appendTest再次插入数据
insert into appendTest(id,name) values(4,'name4');
insert into appendTest(id,name) values(5,'name5');再次执行增量导入
#由于上一次导入的时候,,将--last-value设置为0,将id>0的三条数据导入后,现在进行导入了时候需要将last-value设置为3
sqoop import \
--connect jdbc:oracle:thin:@172.22.23.9:1521/helowin \
--username lkw \
--password 123456 \
--query "select * from lkw.appendtest where \$CONDITIONS" \
--hive-drop-import-delims \
--null-string '\\N' \
--null-non-string '\\N' \
-m 1 \
--target-dir /tmp/tb01 \
--incremental append \
--check-column id \
--last-value 3 结果
[root@tdh70001 ~]# hadoop fs -ls /tmp/tb01
2020-10-16 11:13:53,730 INFO util.KerberosUtil: Using principal pattern: HTTP/_HOST
Found 2 items
-rw-r--r-- 3 hdfs hadoop 24 2020-10-16 11:05 /tmp/tb01/part-m-00000
-rw-r--r-- 3 hdfs hadoop 16 2020-10-16 11:12 /tmp/tb01/part-m-00001
[root@tdh70001 ~]# hadoop fs -cat /tmp/tb01/part*
2020-10-16 11:14:04,005 INFO util.KerberosUtil: Using principal pattern: HTTP/_HOST
1,name1
2,name2
3,name3
4,name4
5,name52. 方式二:LastModified方式
基于lastModify的方式,要求原表中有time字段,它能指定一个时间戳,让SQoop把该时间戳之后的数据导入至Hive,因为后续订单可能状态会发生变化,变化后time字段时间戳也会发生变化,此时SQoop依然会将相同状态更改后的订单导入Hive,当然我们可以指定merge-key参数为id,表示将后续新的记录与原有记录合并。
重要参数说明:
| 参数 | 说明 |
|---|---|
| –incremental lastmodified | 基于时间列的增量导入(将时间列值大于阈值的所有数据增量导入hdfs) |
| –check-column | 递增列(int) |
| –last-value | 阈值(int) |
| –merge-key | 合并列(主键,合并键值相同的记录) |
2.1 Oracle建表
CREATE TABLE lastModifyTest (
id INT,
name VARCHAR2(20),
last_mod TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);2.2 导入数据
insert into lastModifyTest(id,name,last_mod) values(1,'enzo',to_timestamp('20190514151716','yyyymmddhh24miss'));
insert into lastModifyTest(id,name,last_mod) values(2,'din',to_timestamp('20190514151723','yyyymmddhh24miss'));
insert into lastModifyTest(id,name,last_mod) values(3,'fz',to_timestamp('20190514151729','yyyymmddhh24miss'));
insert into lastModifyTest(id,name,last_mod) values(4,'dx',to_timestamp('20190514151734','yyyymmddhh24miss'));
insert into lastModifyTest(id,name,last_mod) values(5,'ef',to_timestamp('20190514151740','yyyymmddhh24miss'));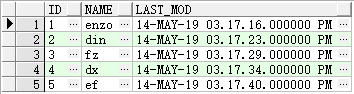
2.3 增量导入
#将last_mod值2019-05-14 15:17:23时间以后的数据进行导入
sqoop import \
--connect jdbc:oracle:thin:@172.22.23.9:1521/helowin \
--username lkw \
--password 123456 \
--query "select * from lkw.lastModifyTest where \$CONDITIONS" \
--hive-drop-import-delims \
--null-string '\\N' \
--null-non-string '\\N' \
-m 1 \
--target-dir /tmp/tb02 \
--incremental lastmodified \
--check-column LAST_MOD \
--last-value "2019-05-14 15:17:23"执行日志:
[root@tdh70001 ~]# sqoop import --connect jdbc:oracle:thin:@172.22.23.9:1521/helowin --username lkw --password 123456 --query "select * from lkw.lastModifyTest where \$CONDITIONS" --hive-drop-import-delims --null-string '\\N' --null-non-string '\\N' -m 1 --target-dir /tmp/tb02 --incremental lastmodified --check-column LAST_MOD --last-value "2019-05-14 15:17:23"
Warning: /root/TDH-Client/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /root/TDH-Client/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /root/TDH-Client/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
2020-10-16 11:35:01,134 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5-transwarp-6.0.0
2020-10-16 11:35:01,169 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
2020-10-16 11:35:01,453 INFO oracle.OraOopManagerFactory: Data Connector for Oracle and Hadoop is disabled.
2020-10-16 11:35:01,471 INFO manager.SqlManager: Using default fetchSize of 1000
2020-10-16 11:35:01,472 INFO tool.CodeGenTool: Beginning code generation
2020-10-16 11:35:03,138 INFO manager.OracleManager: Time zone has been set to GMT
2020-10-16 11:35:03,280 INFO manager.SqlManager: Executing SQL statement: select * from lkw.lastModifyTest where (1 = 0)
2020-10-16 11:35:03,294 INFO manager.SqlManager: Executing SQL statement: select * from lkw.lastModifyTest where (1 = 0)
2020-10-16 11:35:03,321 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /root/TDH-Client/hadoop/hadoop-mapreduce
注: /tmp/sqoop-root/compile/a0940f58ee2cb5824a4d4dffea926fba/QueryResult.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
2020-10-16 11:35:04,844 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/a0940f58ee2cb5824a4d4dffea926fba/QueryResult.jar
2020-10-16 11:35:05,118 INFO util.KerberosUtil: Using principal pattern: HTTP/_HOST
2020-10-16 11:35:06,456 INFO manager.SqlManager: Executing SQL statement: select * from lkw.lastModifyTest where (1 = 0)
2020-10-16 11:35:06,461 INFO tool.ImportTool: Incremental import based on column LAST_MOD
2020-10-16 11:35:06,461 INFO tool.ImportTool: Lower bound value: TO_TIMESTAMP('2019-05-14 15:17:23', 'YYYY-MM-DD HH24:MI:SS.FF')
2020-10-16 11:35:06,461 INFO tool.ImportTool: Upper bound value: TO_TIMESTAMP('2020-10-16 11:35:06.0', 'YYYY-MM-DD HH24:MI:SS.FF')
2020-10-16 11:35:06,464 INFO mapreduce.ImportJobBase: Beginning query import.
2020-10-16 11:35:06,483 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
2020-10-16 11:35:06,500 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
2020-10-16 11:35:07,094 INFO hdfs.DFSClient: Created HDFS_DELEGATION_TOKEN token 274 for hdfs on ha-hdfs:nameservice1
2020-10-16 11:35:07,144 INFO security.TokenCache: Got dt for hdfs://nameservice1; Kind: HDFS_DELEGATION_TOKEN, Service: ha-hdfs:nameservice1, Ident: (HDFS_DELEGATION_TOKEN token 274 for hdfs)
2020-10-16 11:35:07,178 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
2020-10-16 11:35:09,124 INFO db.DBInputFormat: Using read commited transaction isolation
2020-10-16 11:35:09,301 INFO mapreduce.JobSubmitter: number of splits:1
2020-10-16 11:35:09,895 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1600851944038_0016
2020-10-16 11:35:09,895 INFO mapreduce.JobSubmitter: Kind: HDFS_DELEGATION_TOKEN, Service: ha-hdfs:nameservice1, Ident: (HDFS_DELEGATION_TOKEN token 274 for hdfs)
2020-10-16 11:35:10,529 INFO impl.YarnClientImpl: Submitted application application_1600851944038_0016
2020-10-16 11:35:10,621 INFO mapreduce.Job: The url to track the job: http://tdh70002:8088/proxy/application_1600851944038_0016/
2020-10-16 11:35:10,623 INFO mapreduce.Job: Running job: job_1600851944038_0016
2020-10-16 11:35:19,882 INFO mapreduce.Job: Job job_1600851944038_0016 running in uber mode : false
2020-10-16 11:35:19,884 INFO mapreduce.Job: map 0% reduce 0%
2020-10-16 11:35:28,125 INFO mapreduce.Job: map 100% reduce 0%
2020-10-16 11:35:29,148 INFO mapreduce.Job: Job job_1600851944038_0016 completed successfully
2020-10-16 11:35:29,410 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=144928
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=109
HDFS: Number of read operations=4
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=5760
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=5760
Total vcore-milliseconds taken by all map tasks=5760
Total megabyte-milliseconds taken by all map tasks=5898240
Map-Reduce Framework
Map input records=4
Map output records=4
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=56
CPU time spent (ms)=1540
Physical memory (bytes) snapshot=274501632
Virtual memory (bytes) snapshot=4757753856
Total committed heap usage (bytes)=635437056
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=109
2020-10-16 11:35:29,420 INFO mapreduce.ImportJobBase: Transferred 109 bytes in 22.9066 seconds (4.7585 bytes/sec)
2020-10-16 11:35:29,425 INFO mapreduce.ImportJobBase: Retrieved 4 records.
2020-10-16 11:35:29,452 INFO tool.ImportTool: Incremental import complete! To run another incremental import of all data following this import, supply the following arguments:
2020-10-16 11:35:29,452 INFO tool.ImportTool: --incremental lastmodified
2020-10-16 11:35:29,452 INFO tool.ImportTool: --check-column LAST_MOD
2020-10-16 11:35:29,452 INFO tool.ImportTool: --last-value 2020-10-16 11:35:06.0
2020-10-16 11:35:29,452 INFO tool.ImportTool: (Consider saving this with 'sqoop job --create')结果:
[root@tdh70001 ~]# hadoop fs -ls /tmp/tb02
2020-10-16 11:35:58,731 INFO util.KerberosUtil: Using principal pattern: HTTP/_HOST
Found 2 items
-rw-r--r-- 3 hdfs hadoop 0 2020-10-16 11:35 /tmp/tb02/_SUCCESS
-rw-r--r-- 3 hdfs hadoop 109 2020-10-16 11:35 /tmp/tb02/part-m-00000
[root@tdh70001 ~]# hadoop fs -cat /tmp/tb02/part*
2020-10-16 11:36:11,114 INFO util.KerberosUtil: Using principal pattern: HTTP/_HOST
2,din,2019-05-14 15:17:23.0
3,fz,2019-05-14 15:17:29.0
4,dx,2019-05-14 15:17:34.0
5,ef,2019-05-14 15:17:40.0
3. sqoop job的结合使用
前面我们介绍了Append和LastModified方式下,如何根据指定的–last-value来做增量导入,细心的小伙伴肯定发现了,增量导入作为一个后台常驻的导入任务(需要配置成crontab任务,或者Azkaban、Oozie之类的调度工具去定时调度),难道每次都要手动获取这个–last-value再传递到下个增量导入任务中去么?这里就要sqoop job命令登场了!
先说重要结论:
执行job后,会更新job中记录的incremental.last.value,这个时间是执行完job的时间,不是表的–check-column字段最晚的时间!
也就是说,每次执行sqoop job更新的是incremental.last.value中的值所表示的时间到当前系统时间的时间段的数据。
常用命令:
> sqoop job --list #列出所有的job
> sqoop job --show jobname #显示jobname的信息(包括incremental.last.value和其他job的参数信息)
> sqoop job --delete jobname #删除jobname
> sqoop job --exec jobname #执行jobname3.1 sqoop job和LastModified的结合使用
3.1.1 插入新增数据
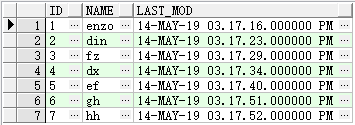
在lastModifyTest表原有的5条数据的基础上,新增2条数据
insert into lastModifyTest(id,name,last_mod) values(6,'gh',to_timestamp('20190514151751','yyyymmddhh24miss'));
insert into lastModifyTest(id,name,last_mod) values(7,'hh',to_timestamp('20190514151752','yyyymmddhh24miss'));目前总览如下:
3.1.2 创建sqoop job
# 1、sqoop job创建时,必须使用-P手动输入,或者通过--password-file密码文件的方式,不能够使用--password
# 否则报错:WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
# 2、如果加上-m的话,就必须在使用--incremental lastmodified、输出目录已存在时,使用--merge-key或者--append
# 否则报错:ERROR tool.ImportTool: Error during import: --merge-key or --append is required when using --incremental lastmodified and the output directory exists.
# 3、列名必须大写,否则报错 Imported Failed: column not found: id
# 4、这里指定--last-value "2019-05-14 15:17:40"
sqoop job \
--create job01 \
-- import \
--connect jdbc:oracle:thin:@172.22.23.9:1521/helowin \
--username lkw \
-P \
--query "select * from lkw.lastModifyTest where \$CONDITIONS" \
--hive-drop-import-delims \
--null-string '\\N' \
--null-non-string '\\N' \
-m 1 \
--target-dir /tmp/tb02 \
--merge-key ID \
--incremental lastmodified \
--check-column LAST_MOD \
--last-value "2019-05-14 15:17:40"3.1.3 执行sqoop job
sqoop job --exec job01执行日志:
[root@tdh70001 ~]# sqoop job --exec job01
#执行该命令后,与直接导入不同,该命令启动了2个mapreduce任务,这样就把数据增量merge导入hdfs了。
Warning: /root/TDH-Client/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /root/TDH-Client/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /root/TDH-Client/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
2020-10-16 14:09:44,582 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5-transwarp-6.0.0
Enter password:
2020-10-16 14:10:48,949 INFO oracle.OraOopManagerFactory: Data Connector for Oracle and Hadoop is disabled.
2020-10-16 14:10:48,965 INFO manager.SqlManager: Using default fetchSize of 1000
2020-10-16 14:10:48,965 INFO tool.CodeGenTool: Beginning code generation
2020-10-16 14:10:50,432 INFO manager.OracleManager: Time zone has been set to GMT
2020-10-16 14:10:50,523 INFO manager.SqlManager: Executing SQL statement: select * from lkw.lastModifyTest where (1 = 0)
2020-10-16 14:10:50,533 INFO manager.SqlManager: Executing SQL statement: select * from lkw.lastModifyTest where (1 = 0)
2020-10-16 14:10:50,556 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /root/TDH-Client/hadoop/hadoop-mapreduce
注: /tmp/sqoop-root/compile/4256f4d8cccf30b96f0bca7714fde250/QueryResult.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
2020-10-16 14:10:52,066 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/4256f4d8cccf30b96f0bca7714fde250/QueryResult.jar
2020-10-16 14:10:52,339 INFO util.KerberosUtil: Using principal pattern: HTTP/_HOST
2020-10-16 14:10:53,563 INFO manager.SqlManager: Executing SQL statement: select * from lkw.lastModifyTest where (1 = 0)
2020-10-16 14:10:53,567 INFO tool.ImportTool: Incremental import based on column LAST_MOD
#这里可以看到对应的下界就是我们定义的--last-value,上界是当前执行时间
2020-10-16 14:10:53,567 INFO tool.ImportTool: Lower bound value: TO_TIMESTAMP('2019-05-14 15:17:40', 'YYYY-MM-DD HH24:MI:SS.FF')
2020-10-16 14:10:53,567 INFO tool.ImportTool: Upper bound value: TO_TIMESTAMP('2020-10-16 14:10:53.0', 'YYYY-MM-DD HH24:MI:SS.FF')
2020-10-16 14:10:53,570 INFO mapreduce.ImportJobBase: Beginning query import.
2020-10-16 14:10:53,589 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
2020-10-16 14:10:53,605 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
2020-10-16 14:10:54,240 INFO hdfs.DFSClient: Created HDFS_DELEGATION_TOKEN token 279 for hdfs on ha-hdfs:nameservice1
2020-10-16 14:10:54,268 INFO security.TokenCache: Got dt for hdfs://nameservice1; Kind: HDFS_DELEGATION_TOKEN, Service: ha-hdfs:nameservice1, Ident: (HDFS_DELEGATION_TOKEN token 279 for hdfs)
2020-10-16 14:10:54,319 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
2020-10-16 14:10:56,324 INFO db.DBInputFormat: Using read commited transaction isolation
2020-10-16 14:10:56,498 INFO mapreduce.JobSubmitter: number of splits:1
2020-10-16 14:10:56,774 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1600851944038_0021
2020-10-16 14:10:56,774 INFO mapreduce.JobSubmitter: Kind: HDFS_DELEGATION_TOKEN, Service: ha-hdfs:nameservice1, Ident: (HDFS_DELEGATION_TOKEN token 279 for hdfs)
2020-10-16 14:10:57,360 INFO impl.YarnClientImpl: Submitted application application_1600851944038_0021
2020-10-16 14:10:57,416 INFO mapreduce.Job: The url to track the job: http://tdh70002:8088/proxy/application_1600851944038_0021/
2020-10-16 14:10:57,416 INFO mapreduce.Job: Running job: job_1600851944038_0021
2020-10-16 14:11:07,681 INFO mapreduce.Job: Job job_1600851944038_0021 running in uber mode : false
2020-10-16 14:11:07,683 INFO mapreduce.Job: map 0% reduce 0%
2020-10-16 14:11:15,824 INFO mapreduce.Job: map 100% reduce 0%
2020-10-16 14:11:15,836 INFO mapreduce.Job: Job job_1600851944038_0021 completed successfully
2020-10-16 14:11:16,019 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=145177
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=81
HDFS: Number of read operations=4
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=5666
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=5666
Total vcore-milliseconds taken by all map tasks=5666
Total megabyte-milliseconds taken by all map tasks=5801984
Map-Reduce Framework
Map input records=3
Map output records=3
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=44
CPU time spent (ms)=1600
Physical memory (bytes) snapshot=278683648
Virtual memory (bytes) snapshot=4757753856
Total committed heap usage (bytes)=635437056
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=81
2020-10-16 14:11:16,029 INFO mapreduce.ImportJobBase: Transferred 81 bytes in 22.4118 seconds (3.6142 bytes/sec)
2020-10-16 14:11:16,034 INFO mapreduce.ImportJobBase: Retrieved 3 records.
2020-10-16 14:11:16,200 INFO Configuration.deprecation: mapred.output.key.class is deprecated. Instead, use mapreduce.job.output.key.class
2020-10-16 14:11:16,256 INFO hdfs.DFSClient: Created HDFS_DELEGATION_TOKEN token 280 for hdfs on ha-hdfs:nameservice1
2020-10-16 14:11:16,256 INFO security.TokenCache: Got dt for hdfs://nameservice1; Kind: HDFS_DELEGATION_TOKEN, Service: ha-hdfs:nameservice1, Ident: (HDFS_DELEGATION_TOKEN token 280 for hdfs)
2020-10-16 14:11:16,263 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
2020-10-16 14:11:17,842 INFO input.FileInputFormat: Total input paths to process : 2
2020-10-16 14:11:18,046 INFO mapreduce.JobSubmitter: number of splits:2
2020-10-16 14:11:18,165 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1600851944038_0022
2020-10-16 14:11:18,165 INFO mapreduce.JobSubmitter: Kind: HDFS_DELEGATION_TOKEN, Service: ha-hdfs:nameservice1, Ident: (HDFS_DELEGATION_TOKEN token 280 for hdfs)
2020-10-16 14:11:18,509 INFO impl.YarnClientImpl: Submitted application application_1600851944038_0022
2020-10-16 14:11:18,513 INFO mapreduce.Job: The url to track the job: http://tdh70002:8088/proxy/application_1600851944038_0022/
2020-10-16 14:11:18,514 INFO mapreduce.Job: Running job: job_1600851944038_0022
2020-10-16 14:11:28,710 INFO mapreduce.Job: Job job_1600851944038_0022 running in uber mode : false
2020-10-16 14:11:28,711 INFO mapreduce.Job: map 0% reduce 0%
^[[A2020-10-16 14:11:35,784 INFO mapreduce.Job: map 100% reduce 0%
2020-10-16 14:11:42,847 INFO mapreduce.Job: map 100% reduce 100%
2020-10-16 14:11:42,860 INFO mapreduce.Job: Job job_1600851944038_0022 completed successfully
2020-10-16 14:11:42,947 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=343
FILE: Number of bytes written=437065
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=452
HDFS: Number of bytes written=163
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=8345
Total time spent by all reduces in occupied slots (ms)=4589
Total time spent by all map tasks (ms)=8345
Total time spent by all reduce tasks (ms)=4589
Total vcore-milliseconds taken by all map tasks=8345
Total vcore-milliseconds taken by all reduce tasks=4589
Total megabyte-milliseconds taken by all map tasks=8545280
Total megabyte-milliseconds taken by all reduce tasks=4699136
Map-Reduce Framework
Map input records=7
Map output records=7
Map output bytes=323
Map output materialized bytes=349
Input split bytes=262
Combine input records=0
Combine output records=0
Reduce input groups=6
Reduce shuffle bytes=349
Reduce input records=7
Reduce output records=6
Spilled Records=14
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=101
CPU time spent (ms)=2300
Physical memory (bytes) snapshot=991227904
Virtual memory (bytes) snapshot=14205108224
Total committed heap usage (bytes)=1642070016
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=190
File Output Format Counters
Bytes Written=163
2020-10-16 14:11:42,994 INFO tool.ImportTool: Saving incremental import state to the metastore
2020-10-16 14:11:43,134 INFO tool.ImportTool: Updated data for job: job01结果:
[root@tdh70001 ~]# hadoop fs -ls /tmp/tb02
2020-10-16 14:11:51,829 INFO util.KerberosUtil: Using principal pattern: HTTP/_HOST
Found 2 items
-rw-r--r-- 3 hdfs hadoop 0 2020-10-16 14:11 /tmp/tb02/_SUCCESS
-rw-r--r-- 3 hdfs hadoop 163 2020-10-16 14:11 /tmp/tb02/part-r-00000
[root@tdh70001 ~]# hadoop fs -cat /tmp/tb02/part-r-00000
2020-10-16 14:12:00,833 INFO util.KerberosUtil: Using principal pattern: HTTP/_HOST
2,din,2019-05-14 15:17:23.0
3,fz,2019-05-14 15:17:29.0
4,dx,2019-05-14 15:17:34.0
5,ef,2019-05-14 15:17:40.0
6,gh,2019-05-14 15:17:51.0
7,hh,2019-05-14 15:17:52.0关键日志:
2020-10-16 14:10:53,567 INFO tool.ImportTool: Lower bound value: TO_TIMESTAMP('2019-05-14 15:17:40', 'YYYY-MM-DD HH24:MI:SS.FF')
2020-10-16 14:10:53,567 INFO tool.ImportTool: Upper bound value: TO_TIMESTAMP('2020-10-16 14:10:53.0', 'YYYY-MM-DD HH24:MI:SS.FF')而再次检查sqoop job中的incremental.last.value,已经变成了2020-10-16 14:10:53.0,下次再次执行该sqoop job,就会以这个时间作为–last-value开始时间 进行判断!
3.2 sqoop job和Append的结合使用
与LastModified同理,这里截取一下关键日志和特征:
sqoop job
--create job02
-- import
--connect jdbc:oracle:thin:@172.22.23.9:1521/helowin
--username lkw
-P
--query "select * from lkw.appendtest where \$CONDITIONS"
--hive-drop-import-delims
--null-string '\\N'
--null-non-string '\\N'
-m 1
--target-dir /tmp/tb01
--merge-key ID
--incremental append
--check-column ID
--last-value 3执行日志:
[root@tdh70001 ~]# sqoop job --exec job02
Warning: /root/TDH-Client/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /root/TDH-Client/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /root/TDH-Client/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
2020-10-16 15:15:42,704 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5-transwarp-6.0.0
Enter password:
2020-10-16 15:15:45,840 INFO oracle.OraOopManagerFactory: Data Connector for Oracle and Hadoop is disabled.
2020-10-16 15:15:45,856 INFO manager.SqlManager: Using default fetchSize of 1000
2020-10-16 15:15:45,856 INFO tool.CodeGenTool: Beginning code generation
2020-10-16 15:15:47,225 INFO manager.OracleManager: Time zone has been set to GMT
2020-10-16 15:15:47,344 INFO manager.SqlManager: Executing SQL statement: select * from lkw.appendtest where (1 = 0)
2020-10-16 15:15:47,357 INFO manager.SqlManager: Executing SQL statement: select * from lkw.appendtest where (1 = 0)
2020-10-16 15:15:47,381 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /root/TDH-Client/hadoop/hadoop-mapreduce
注: /tmp/sqoop-root/compile/a3b2b1e0eb058201be32e9def39efaf8/QueryResult.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
2020-10-16 15:15:48,837 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/a3b2b1e0eb058201be32e9def39efaf8/QueryResult.jar
2020-10-16 15:15:49,128 INFO util.KerberosUtil: Using principal pattern: HTTP/_HOST
2020-10-16 15:15:50,380 INFO tool.ImportTool: Maximal id query for free form incremental import: SELECT MAX(ID) FROM (select * from lkw.appendtest where (1 = 1)) sqoop_import_query_alias
2020-10-16 15:15:50,384 INFO tool.ImportTool: Incremental import based on column ID
2020-10-16 15:15:50,384 INFO tool.ImportTool: Lower bound value: 3
2020-10-16 15:15:50,385 INFO tool.ImportTool: Upper bound value: 5
2020-10-16 15:15:50,387 INFO mapreduce.ImportJobBase: Beginning query import.
2020-10-16 15:15:50,402 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
2020-10-16 15:15:50,415 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
2020-10-16 15:15:51,010 INFO hdfs.DFSClient: Created HDFS_DELEGATION_TOKEN token 283 for hdfs on ha-hdfs:nameservice1
2020-10-16 15:15:51,038 INFO security.TokenCache: Got dt for hdfs://nameservice1; Kind: HDFS_DELEGATION_TOKEN, Service: ha-hdfs:nameservice1, Ident: (HDFS_DELEGATION_TOKEN token 283 for hdfs)
2020-10-16 15:15:51,087 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
2020-10-16 15:15:53,052 INFO db.DBInputFormat: Using read commited transaction isolation
2020-10-16 15:15:53,231 INFO mapreduce.JobSubmitter: number of splits:1
2020-10-16 15:15:53,500 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1600851944038_0025
2020-10-16 15:15:53,500 INFO mapreduce.JobSubmitter: Kind: HDFS_DELEGATION_TOKEN, Service: ha-hdfs:nameservice1, Ident: (HDFS_DELEGATION_TOKEN token 283 for hdfs)
2020-10-16 15:15:54,100 INFO impl.YarnClientImpl: Submitted application application_1600851944038_0025
2020-10-16 15:15:54,159 INFO mapreduce.Job: The url to track the job: http://tdh70002:8088/proxy/application_1600851944038_0025/
2020-10-16 15:15:54,160 INFO mapreduce.Job: Running job: job_1600851944038_0025
2020-10-16 15:16:03,384 INFO mapreduce.Job: Job job_1600851944038_0025 running in uber mode : false
2020-10-16 15:16:03,386 INFO mapreduce.Job: map 0% reduce 0%
2020-10-16 15:16:21,729 INFO mapreduce.Job: map 100% reduce 0%
2020-10-16 15:16:22,750 INFO mapreduce.Job: Job job_1600851944038_0025 completed successfully
2020-10-16 15:16:22,927 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=145035
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=24
HDFS: Number of read operations=4
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=15807
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=15807
Total vcore-milliseconds taken by all map tasks=15807
Total megabyte-milliseconds taken by all map tasks=16186368
Map-Reduce Framework
Map input records=3
Map output records=3
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=75
CPU time spent (ms)=1720
Physical memory (bytes) snapshot=267665408
Virtual memory (bytes) snapshot=4757753856
Total committed heap usage (bytes)=494927872
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=24
2020-10-16 15:16:22,936 INFO mapreduce.ImportJobBase: Transferred 24 bytes in 32.5106 seconds (0.7382 bytes/sec)
2020-10-16 15:16:22,941 INFO mapreduce.ImportJobBase: Retrieved 3 records.
2020-10-16 15:16:22,964 INFO util.AppendUtils: Appending to directory tb01
2020-10-16 15:16:22,975 INFO util.AppendUtils: Using found partition 2
2020-10-16 15:16:22,996 INFO tool.ImportTool: Saving incremental import state to the metastore
2020-10-16 15:16:23,133 INFO tool.ImportTool: Updated data for job: job02关键日志:
2020-10-16 15:15:50,380 INFO tool.ImportTool: Maximal id query for free form incremental import: SELECT MAX(ID) FROM (select * from lkw.appendtest where (1 = 1)) sqoop_import_query_alias
2020-10-16 15:15:50,384 INFO tool.ImportTool: Incremental import based on column ID
2020-10-16 15:15:50,384 INFO tool.ImportTool: Lower bound value: 3
2020-10-16 15:15:50,385 INFO tool.ImportTool: Upper bound value: 5执行之后,通过sqoop job –show job02可以看到incremental.last.value=5,下次执行sqoop job会以ID>5的数据进行导入。