内容纲要
概要描述
跑MapReduce任务,任务提交到yarn后一直卡在某个reduce阶段,
查看yarn的nodemanager日志(/var/log/yarn1/hadoop-yarn-nodemanager-mll01.log),有类似OPERATION=Container Finished – Killed 报错,详细日志信息如下:
INFO:org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch: Cleaning up container container_e32_1558929087194_0228_01_000002
WARN:org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor: Exit code from container container_e32_1558929087194_0228_01_000002 is : 143
INFO:org.apache.hadoop.yarn.server.nodemanager.containermanager.container.ContainerImpl: Container container_e32_1558929087194_0228_01_000002 transitioned from KILLING to CONTAINER_CLEANEDUP_AFTER_KILL
INFO:org.apache.hadoop.yarn.server.nodemanager.NMAuditLogger: USER=hive OPERATION=Container Finished - Killed TARGET=ContainerImpl RESULT=SUCCESS APPID=application_1558929087194_0228 CONTAINERID=container_e32_1558929087194_0228_01_000002
INFO:org.apache.hadoop.yarn.server.nodemanager.containermanager.container.ContainerImpl: Container container_e32_1558929087194_0228_01_000002 transitioned from CONTAINER_CLEANEDUP_AFTER_KILL to DONE
INFO:org.apache.hadoop.yarn.server.nodemanager.containermanager.application.ApplicationImpl: Removing container_e32_1558929087194_0228_01_000002 from application application_1558929087194_0228
INFO :org.apache.hadoop.yarn.server.nodemanager.containermanager.monitor.ContainersMonitorImpl: Neither virutal-memory nor physical-memory monitoring is needed. Not running the monitor-thread
INFO:org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.AppLogAggregatorImpl: Considering container container_e32_1558929087194_0228_01_000002 for log-aggregation详细说明
从yarn的nodemanager日志信息,可以看出在执行reduce阶段container被kill掉了,导致任务失败。
大部分此类情况都可能是由于物理内存不足导致的,可以尝试增大yarn的内存配置:
- 在beeline上(点击查看beeline使用方法)运行如下两个命令查看关于mapreduce container内存的当前配置:
SET mapreduce.map.memory.mb;
SET mapreduce.reduce.memory.mb;
例如:0: jdbc:hive2://bryan1:10000> SET mapreduce.map.memory.mb; +-------------------------------+ | set | +-------------------------------+ | mapreduce.map.memory.mb=1024 | +-------------------------------+ 1 row selected (0.266 seconds) 0: jdbc:hive2://bryan1:10000> SET mapreduce.reduce.memory.mb; +----------------------------------+ | set | +----------------------------------+ | mapreduce.reduce.memory.mb=1024 | +----------------------------------+ 1 row selected (0.007 seconds)TDH 5.2.x,默认内存设置为1G,TDH 6.0.x,默认内存设置为map 1G,reduce 2G
- 根据当前集群的物理内存使用情况,决定调整后的内存配置(例如增大到4G)
- 登录 Manager 页面 (http://manager_ip:8180)
- 点击 YARN 组件,并点击 配置 按钮进入YARN组件的配置参数页面
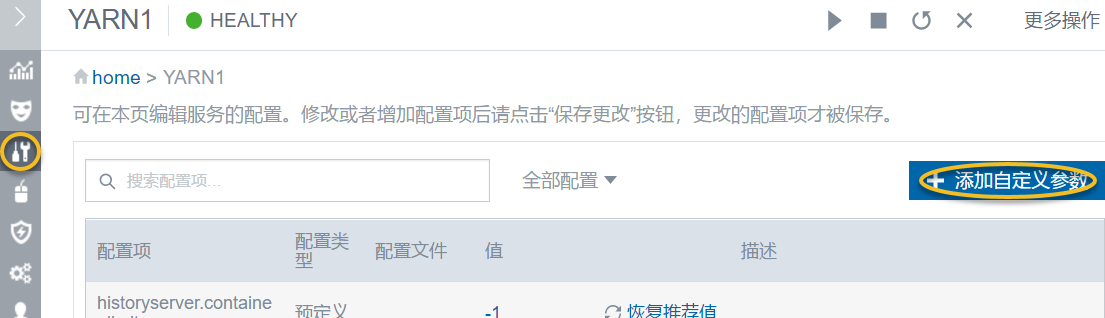
- 点击 添加自定义参数 按钮,添加如下自定义属性参数:
mapreduce.map.memory.mb
mapreduce.reduce.memory.mb
值为第2步决定的内存大小,4G对应值为4096,配置文件:mapred_site,参考下图:

- 参数添加完成后,点击 更多操作 > 配置服务
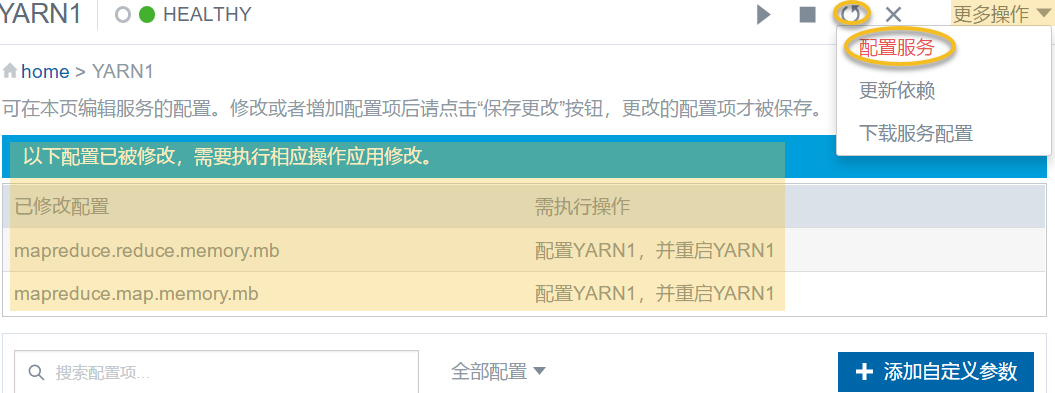
- 配置完成后,重启 YARN 组件服务
若问题依然存在,请联系星环科技技术支持中心