问题描述
客户描述,TDH6.0.2版本下,下面2个sql语句在使用时,SQL2执行只需要1s,而SQL1执行需要1900s+。
--SQL1:
> select * from jtw.v_td_gps_v1_bus2020 where select_dt =date_add((sysdate),-3) limit 1;
--SQL2:
> select * from jtw.v_td_gps_v1_bus2020 where select_dt='2020-11-01' limit 1;排查思路
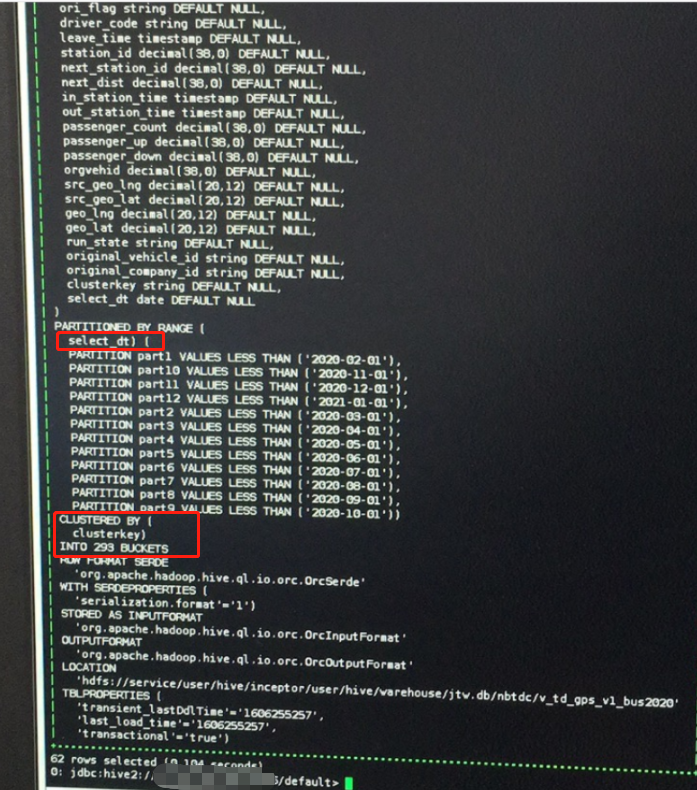
1. 检查DDL
DDL如下,范围分区分桶ORC事务表,select_dt就是它的分区键,每个分区下293个buckets。
SQL2能够正常查询到结果表示part10分区内确实存在数据,故SQL1应该是可以做到PartitionPruner的,猜测分区下推出现异常。
2. 排查hive-server2.log日志的task数
由于4040页面job信息刷新过快,已无法查看job details页面的task数目信息,故通过hive-server2.log日志进行排查。
排查发现map阶段起了多达2342个task,远远大于一个分区内的分桶数293。故证实未能实现分区下推。
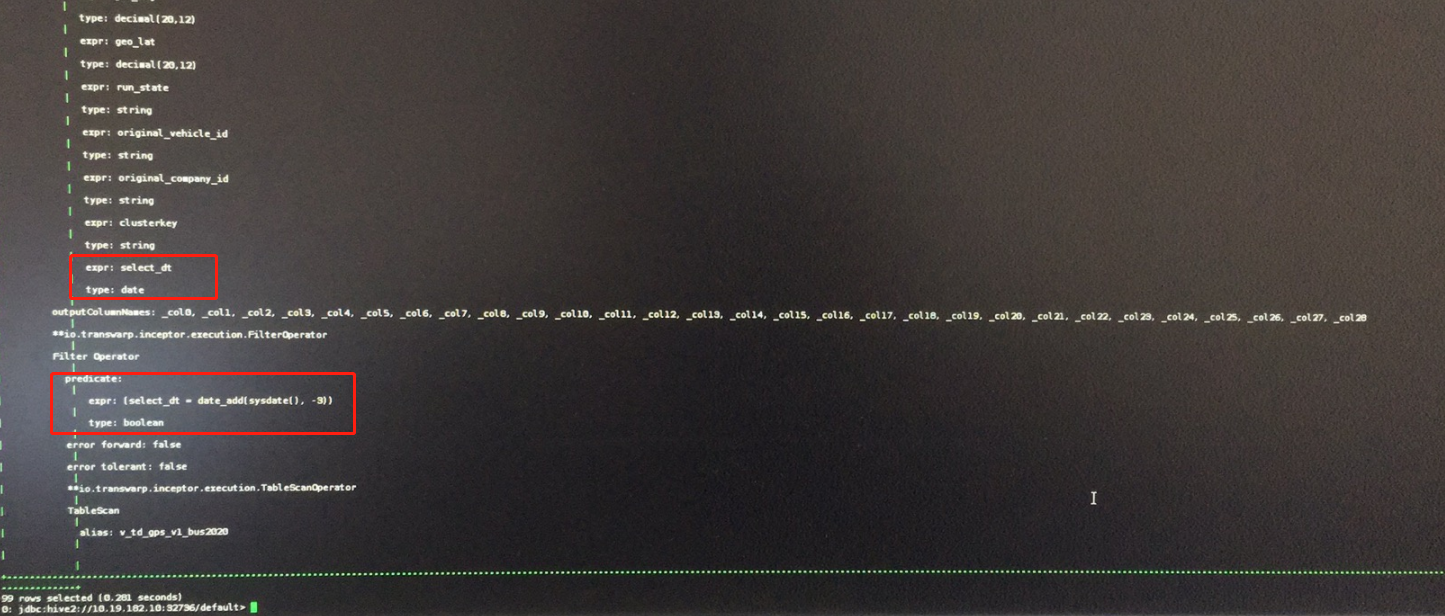
注:
通过explain执行计划,可以简单的定位到在SelectOperator的expr中确实没能获取到实际的value,同样能够证实未能分区下推。
解决办法
自定义UDF,使用UDF函数替代sysdate
step0:获取依赖包
需要jar包hive-exec-0.12.0-transwarp-6.0.2.jar、hadoop-common-2.7.2-transwarp-6.0.2.jar,可以到inceptor容器的/usr/lib/inceptor/lib下获取
step1:自定义currentdate
import org.apache.hadoop.hive.common.type.HiveDate;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.hive.ql.udf.UDFType;
import org.apache.hadoop.hive.serde2.io.DateWritable;
@Description(name = "currentdate",
value = "FUNC -Return the current date",
extended = "Return the current date as format yyyy-MM-dd as default\n" +
"Example:\n" +
" > SELECT FUNC FROM src limit 1;\n" +
"2012-12-12"
)
@UDFType(deterministic = true)
public class UDFCurrentdate extends UDF {
DateWritable result = new DateWritable();
public UDFCurrentdate()
{ result.set(new HiveDate()); }
public DateWritable evaluate()
{ return result; }
}step3:创建永久函数
1) udf.jar放到/usr/lib/inceptor/lib中,做镜像持久化(参考KB TDH安装Hotfix(换包)方法)
2) beeline模式下,create permanent function currentdate as 'UDFCurrentdate';
step4: 使用语句进行测试,检查执行计划或者task数目是否降低
EXPLAIN
SELECT * FROM people_range_partition WHERE BORNDATE = date_add(sysdate,-5809);修改为:
EXPLAIN
SELECT * FROM people_range_partition WHERE BORNDATE = date_add(currentdate(),-5809);通过explain执行计划或者4040页面的task数目信息可以验证,分区下推成功!