概要描述
UDAF是用户自定义聚合函数。Hive支持其用户自行开发聚合函数完成业务逻辑。
通俗点说,就是你可能需要做一些特殊的甚至是非常扭曲的逻辑聚合,但是Hive自带的聚合函数不够玩,同时也还找不到高效的等价玩法,那么,这时候就该自己写一个UDAF了。
本篇文章主要围绕UADF函数进行介绍,所谓的UDAF函数,简言而之就是有聚合功能的函数。常见的内置函数,比如count、sum、max、min、avg等等。
详细说明
在实现inceptor自定UDAF时,需要继承org.apache.hadoop.hive.ql.exec.UDAF类,并在派生类中以静态内部类的方式实现org.apache.hadoop.hive.ql.exec.UDAFEvaluator接口。这种方式简单直接,但是在使用过程中需要依赖JAVA反射机制,因此性能相对较低。在Hive源码包org.apache.hadoop.hive.contrib.udaf.example中包含几个示例。可以直接参阅。但是这些接口已经被注解为Deprecated,建议不要使用这种方式开发新的UDAF函数。
有兴趣的同学可以参考Hive社区推荐的新的写法,抽象类代替原有的接口。
- 新的抽象类org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver替代老的UDAF接口;
- 新的抽象类org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator替代老的UDAFEvaluator接口;
- **本文不对该方法做描述**标准UDAF的实现步骤如下:
- 1.Iterate函数用于聚合。当每一个新的值被聚合时,此函数被调用。
- 2.TerminatePartial函数在部分聚合完成后被调用。当hive希望得到部分记录的聚合结果时,此函数被调用。
- 3.Merge函数用于合并先前得到的部分聚合结果(也可以理解为分块记录的聚合结果)。
- 4.Terminate返回最终的聚合结果。下面我们开始编写自己的UDAF函数。该函数的功能描述:
- 功能1.保存字段1的第一次出现的任何值
- 功能2.保存字段2最后一个值
- 功能3.保存字段3最后一个非空非null的有效值
- 功能4.将字段4所有非空非null的有效值使用分隔符连接起来实现步骤
了解Hadoop MapReduce的同学应该知道,一个MapReduce job 分为map、combine、reduce三个阶段,map阶段是把函数应用于输入数据的每一条,构建key-value供后续聚合;combine阶段是在mapper端局部进行聚合,聚合后的中间结果传给reduce函数,输入和reduce函数是一致的,被称为mapper端的reduce。了解了这个过程后,我们来看evaluator的几个方法,基本上是对应这几个阶段。
| 方法 | 作用 |
|---|---|
| inite | 初始化函数 |
| iterate | 一条一条处理数据,将结果存入缓存 |
| terminatePartial | 这个方法意味着map阶段结束,将缓存中的数据持久化存储。这里返回的数据类型仅支持java基本类型、基本类型包装类、数组以及Hadoop的Writables, Lists和Map,不要使用自定义类型 |
| merge | 接收terminatePartial返回的结果,合并局部聚合结果 |
| terminate | 返回最终结果,可以在这里实现最后的求值 |
1. 代码实现
org.apache.hadoop.hive.ql.exec.UDAF和org.apache.hadoop.hive.ql.exec.UDAFEvaluator这两个类,可以到inceptor容器内/usr/lib/inceptor/lib/路径下获取
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
public class InceptorUDAF extends UDAF {
/**
* 在实现inceptor自定UDAF时,必须要继承UDAF类,还有在这个类的内部实现一个内部类实现接口UDAFEvaluator
* 并重写里面的四个主要的方法
*
* 1. Iterate函数用于聚合。当每一个新的值被聚合时,此函数被调用。
* 2. TerminatePartial函数在部分聚合完成后被调用。当hive希望得到部分记录的聚合结果时,此函数被调用。
* 3. Merge函数用于合并先前得到的部分聚合结果(也可以理解为分块记录的聚合结果)。
* 4. Terminate返回最终的聚合结果。
*
* 下面代码的逻辑要实现的是:
* 1.保存fields3的第一次出现的任何值
* 2.保存fields4的最后一个值
* 3.保存fields5的最后一个非空非null的有效值
* 4.将fields6的所有非空非null的有效值使用分隔符连接起来
* 返回结果是“第一次出现的fields3,最后一次出现的fields4,fields5的最后一个非空非null的有效值,fields6所有的非空非null的有效值使用分隔符连接起来的字符串”
*/
public static class GroupByUDAFEvaluator implements UDAFEvaluator{
// 一个bean类记录字段和分隔符信息
public static class PartialResult{
String filed3;
String filed4;
String filed5;
String filed6;
String delimiter;
}
private PartialResult partial;
public void init() {
partial = null;
}
/**
* 需要实现的第一个方法
* 每个需要处理的处理都要经过的处理
*/
public boolean iterate(String filed3,String filed4,String filed5 ,String filed6){
if(filed3 == null && filed4 == null && filed5 == null && filed6 == null){
return true;
}
if(partial == null ){
partial = new PartialResult();
partial.filed3 = "";
partial.filed4 = "";
partial.filed5 = "";
partial.filed6 = "";
partial.delimiter = "-";
//filed3 logical
partial.filed3 = filed3;
}
//filed4 logical
partial.filed4 = filed4;
//filed5 logical
if(filed5 != null && !filed5.trim().equals("")) {
partial.filed5 = filed5;
}
//filed6 logical
if(filed6 != null && !filed6.trim().equals("")) {
if(partial.filed6.length() > 0 ){
partial.filed6 = partial.filed6.concat(partial.delimiter);
}
partial.filed6 = partial.filed6.concat(filed6);
}
return true;
}
/**
* 需要实现的第二个方法
* 返回部分结果
*/
public PartialResult terminatePartial(){
return partial;
}
/**
* 需要实现的第三个方法
* 将两个部分结果合并
*/
public boolean merge(PartialResult othe){
if (othe == null){
return true;
}
if(partial == null ){
partial = new PartialResult();
partial.filed3 = othe.filed3;
partial.filed4 = othe.filed4;
partial.filed5 = othe.filed5;
partial.filed6 = othe.filed6;
partial.delimiter = othe.delimiter;
} else {
//filed4 logical
partial.filed4 = othe.filed4;
//filed5 logical
if(othe.filed5 != null && !othe.filed5.trim().equals("")) {
partial.filed5 = othe.filed5;
}
//filed6 logical
if(othe.filed6 != null && !othe.filed6.trim().equals("")) {
if (partial.filed6.length() >0){
partial.filed6 = partial.filed6.concat(othe.delimiter);
}
partial.filed6 = partial.filed6.concat(othe.filed6);
}
}
return true;
}
/**
* 需要实现的第四个方法
* 构造返回值类型,返回结果
*/
public String terminate(){
return "filed3:"+partial.filed3+" filed4:" +partial.filed4+" filed5 :"+partial.filed5+" filed6: "+partial.filed6;
}
}
}2. 打包成jar包
此处忽略,可自行百度不同命令或IDE工具的打包方式。
注意:打包时,jdk版本要和inceptor内的jdk版本保持一致,否则会报java.lang.UnsupportedClassVersionError: InceptorUDAF : Unsupported major.minor version 52.0的问题
3. UDF持久化
**4.X版本:**
1) udf.jar放到/usr/lib/hive/lib中(每个executor节点);
2) add jar /usr/lib/hive/lib/udf.jar;
3) create permanent function func_name as 'package.classname';
**5.X版本以上**
1) 把udf.jar放到/usr/lib/inceptor/lib目录下,push到镜像仓库;
2) 重启inceptor来获取最新镜像;
3) create permanent function func_name as 'package.classname';
注意:
1) udf无论是临时还是永久,如果要删除并重新创建使用相同类或者jar的话,都要重启inceptor server;
2) 官方不推荐使用using jar的方式是因为此方法存在异常隐患,会报找不到jar包的错误。这里以TDH6.0.2版本环境为例:
首先将InceptorUDAF.jar放到/usr/lib/inceptor/lib目录下,push到镜像仓库中,重启inceptor来拉取最新镜像;
--创建永久函数
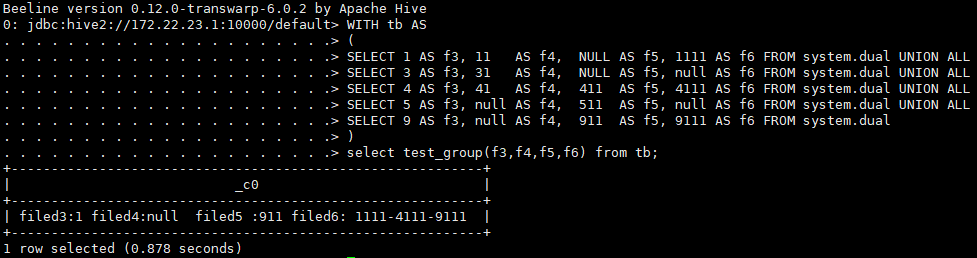
> CREATE PERMANENT FUNCTION test_group AS 'InceptorUDAF';--测试UDAF函数
> WITH tb AS
(
SELECT 1 AS f3, 11 AS f4, NULL AS f5, 1111 AS f6 FROM system.dual UNION ALL
SELECT 3 AS f3, 31 AS f4, NULL AS f5, null AS f6 FROM system.dual UNION ALL
SELECT 4 AS f3, 41 AS f4, 411 AS f5, 4111 AS f6 FROM system.dual UNION ALL
SELECT 5 AS f3, null AS f4, 511 AS f5, null AS f6 FROM system.dual UNION ALL
SELECT 9 AS f3, null AS f4, 911 AS f5, 9111 AS f6 FROM system.dual
)
select test_group(f3,f4,f5,f6) from tb;