概要说明
在create 一个 hyperbase 表时如果不指定预分配 region,则默认会先分配一个 region,这样在大数据并行载入时性能比较低,因为所有的数据都往一个 region 灌入,容易引起单节点负载升高,从而影响入库性能,一个好的方法时在建立表时预先分配数个region。
本文介绍一下 TDH 平台上如何在建表的时候预分 region。
详细说明
不预分region的问题
- 在生成Hifle的时候,所有的数据会进同一个 reducer
- Hyperbase 自动 split 的机制,非常耗时耗资源
hyperdrive 表以 SQL 的方式预分 region 的方法
- hyperdrive 表使用临时表存储 splitkey
- hyperdrive 表使用 hyperdrive.table.splitkey 配置项指定 split key
具体操作
1、hyperdrive 表使用临时表存储 splitkey
该方法适用于splitkey 有不可见字符情况,具体操作参考该文档:Hyperdrive 的 SQL Bulkload
2、hyperdrive 表使用 hyperdrive.table.splitkey 配置项指定 split key
该方法适用于对表的 rowkey 很了解时,可以使用该方法直接指定。
创建 hyperdrive 表的时候在 tblproperties 属性中使用 hyperdrive.table.splitkey 配置项指定 split key。
- 原始数据类型的rowkey使用说明
-
每个split key需要使用双引号,在值中的 " 符号是需要转义的,多个split key使用逗号相隔
-
建表语句
create table splitkey_test (
key string,
sk1 string
)
stored by 'io.transwarp.hyperdrive.HyperdriveStorageHandler'
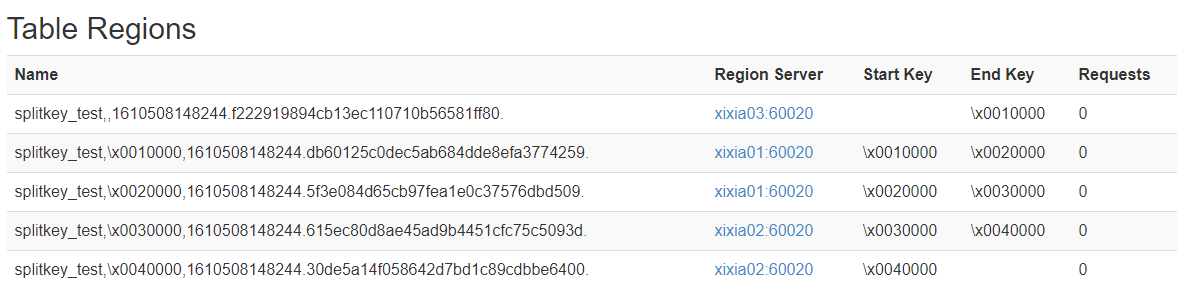
tblproperties('hyperdrive.table.splitkey'='"10000","20000","30000","40000"');在active master页面查看表信息
- struct数据类型的rowkey使用说明
-
struct类型值中的每个字段顺序都是需要和表中schema的顺序对齐;
-
struct类型的值可以指定前缀, 后缀可以省略。 例如: {"name":"张三","age":5,"birth": null} 等价于 {"name":"张三","age":51};
-
每个split key都是一个Row key对应的一个JSON格式的值,在值中的{}和 " 符号是需要转义。
-
建表语句
create table splitkey_test( key struct -
在active master页面查看表信息

hbase表以SQL的方式预分region
参考该文档:hbase的SQL bulkload
hbase 表以命令行的方式预分 region
通过 org.apache.hadoop.hbase.util.RegionSplitter 类来创建表
使用该方法建表,可以传入不同的 拆分点算法 就可以在建表的同时定义拆分点算法;
-
HexStringSplit拆分算法
HexStringSplit把数据从“00000000”到“FFFFFFFF”之间的数据 长度按照n等分之后算出每一段的起始rowkey和结束rowkey,以此作为 拆分点。 -
UniformSplit拆分算法
UniformSplit有点像HexStringSplit的byte版,不管传参还是n, 唯一不一样的是起始和结束不是String,而是byte[]。
起始rowkey是ArrayUtils.EMPTY_BYTE_ARRAY;
结束rowkey是new byte[] {xFF, xFF, xFF, xFF, xFF, xFF, xFF, xFF};
最后调用Bytes.split方法把起始rowkey到结束rowkey之间的长度n 等分,然后取每一段的起始和结束作为拆分点。 -
自定义
默认的拆分点算法就这两个,还可以通过实现SplitAlgorithm接口实现自己的拆分算法。
- 使用说明
下面这条命令的意思就是新建一个叫 my_split_table 的表,并根据 HexStringSplit 拆分点算法预拆分为5个 Region,同时建立两个列族 cf1 和 cf2 。
hbase org.apache.hadoop.hbase.util.RegionSplitter my_split_table HexStringSplit -c 5 -f cf1:cf2my_split_table: 我们指定要新建的表名;HexStringSplit: 指定的拆分点算法为HexStringSplit;-c: 要拆分的Region数量;-f: 要建立的列族名称,多个列族用冒号分隔;

建完后用 hbase shell 看一下结果,执行以下命令查出所有5个 Region的信息。
scan 'hbase:meta',{STARTROW=>'my_split_table',LIMIT=>5}
STARTKEY => '', ENDKEY => '33333333'
STARTKEY => '33333333', ENDKEY => '66666666'
STARTKEY => '66666666', ENDKEY => '99999999'
STARTKEY => '99999999', ENDKEY => 'cccccccc'
STARTKEY => 'cccccccc', ENDKEY => ''通过 SPLITS 参数手动指定切分点
手动指定拆分点的方法就是在建表的时候跟上 SPLITS 参数。
create 'test_split_table','cf1',SPLITS=>['aaa','bbb','ccc']
建完后用 hbase shell 看一下结果,执行以下命令查出所有 4 个 Region 信息。
scan 'hbase:meta',{STARTROW=>'test_split_table',LIMIT=>4}
STARTKEY => '', ENDKEY => 'aaa'
STARTKEY => 'aaa', ENDKEY => 'bbb'
STARTKEY => 'bbb', ENDKEY => 'ccc'
STARTKEY => 'ccc', ENDKEY => ''