问题描述
客户反馈,在对列数据做concat_ws时,子查询中order by排序好的顺序会发生错乱的问题。本文会对该问题进行场景复现,并予以解决方案。
问题现象
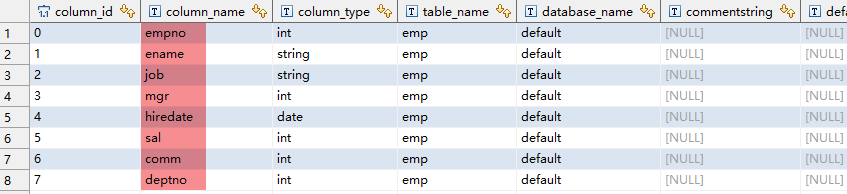
下面构造一个简单的场景复现客户的问题,需要参照system.columns_v数据字典表构造一个文本表。在插入时结合mapred.reduce.tasks这个reduce参数 + DISTRIBUTE BY来构造map数不为1。
--构造样例表
> DROP TABLE IF EXISTS tbcolumns;
> CREATE TABLE tbcolumns AS
SELECT
column_id,
column_name,
column_type,
table_name,
database_name,
commentstring,
default_value,
nullable,
unique_constraint,
column_length,
column_scale
FROM system.columns_v WHERE 1=2;
> SET mapred.reduce.tasks=3;
> INSERT INTO tbcolumns SELECT * FROM system.columns_v DISTRIBUTE BY column_id;--测试语句
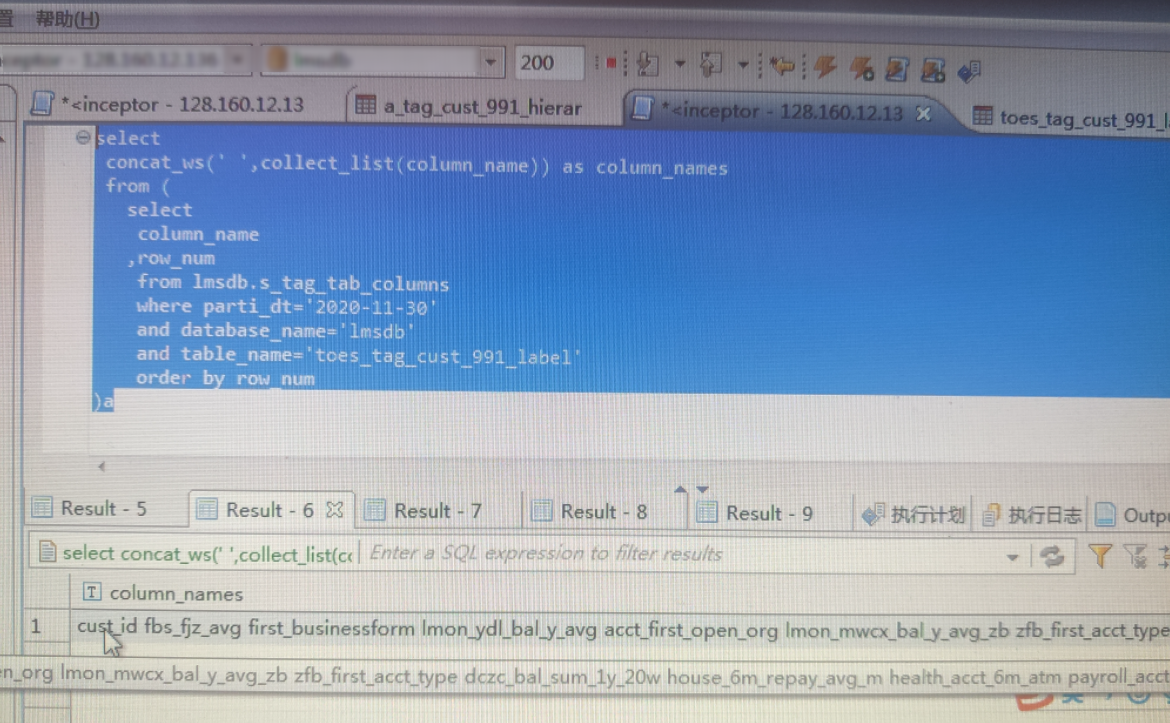
> SELECT
concat_ws(',',collect_list(column_name ))
FROM
(SELECT * FROM tbcolumns WHERE table_name='emp' ORDER BY column_id ASC);上面这个sql,期望的结果是,对SELECT column_name FROM tbcolumns WHERE table_name='emp' ORDER BY column_id asc的结果做拼接,顺序不能错乱,为empno,ename,job,mgr,hiredate,sal,comm,deptno 。
而实际的结果,顺序发生了错乱,并且每次执行的结果都不一致:

解决方法
方案1:
SELECT
concat_ws(',',collect_list(column_name ))
FROM
(
select column_name,row_number() over (order by column_id) from tbcolumns WHERE table_name='emp'
);
方案2:
产生这个问题的根本原因自然在MapReduce,如果启动了多于一个mapper/reducer来处理数据,select出来的数据顺序就几乎肯定与原始顺序不同了。考虑把mapper数固定成1比较麻烦,也不现实,只使用sort_array如果不对列lpad补0的话容易出现排序混乱,所以要迂回地解决问题:把rank列加进来再进行一次排序,拼接完之后把rank列去掉。如下:
select
regexp_replace(
concat_ws(',',sort_array(collect_list(concat_ws(':',lpad(cast(column_id as string),5,'0'),column_name)))),
'\\d+\:','')
from tbcolumns WHERE table_name='emp';
这里将rank列也就是column_id放在了column_name之前,用冒号分隔,然后用sort_array函数对collect_list之后的结果进行排序(只支持升序)。
特别注意,rank列必须要在高位补足够的0对齐(这里使用lpad追加0字符的方式),因为排序的是字符串而不是数字,如果不补0的话,按字典序排序就会变成1, 10, 11, 12, 13, 2, 3, 4…,就不对了。
将排序的结果拼起来之后,用regexp_replace函数替换掉冒号及其前面的数字,大功告成。
FAQ:
group_concat函数也同理
DROP TABLE IF EXISTS test9911;
CREATE TABLE test9911(deptno INT,name STRING ) CLUSTERED BY (deptno) INTO 3 BUCKETS STORED AS ORC_TRANSACTION;
INSERT INTO test9911 select 1,'zhangsan' from system.dual;
INSERT INTO test9911 select 2,'wangwu' from system.dual;
--此时下面的查询结果是随机的,有时候zhangsan,wangwu,是有时候是wangwu,zhangsan
SELECT
group_concat(name,',')
FROM
(SELECT * FROM test9911 ORDER BY deptno ASC);
--解决方案:
SELECT
group_concat(name,',')
FROM
(select NAME,row_number() over (order by DEPTNO) from test9911);