概要说明
Manager进行healthcheck时候的报错,有时候会出现服务角色明明是健康的,healthcheck却提示down,给出的错误是:com.google.common.util.concurrent.UncheckedTimeoutException: java.util.concurrent.TimeoutException 的错误,类似: 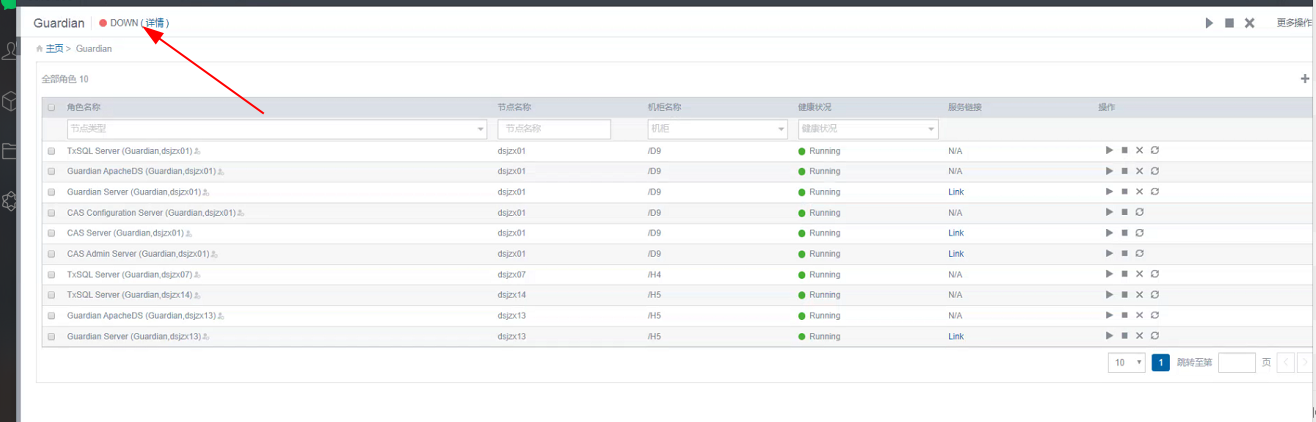
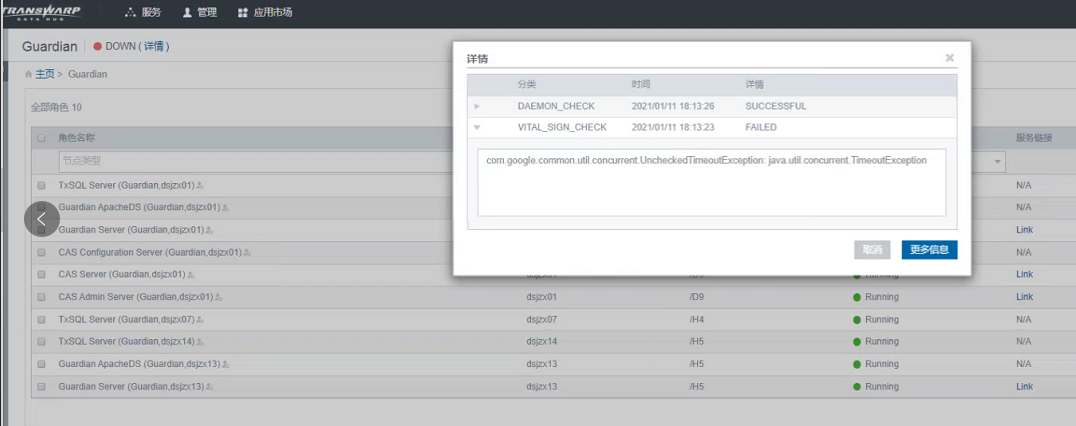
详细说明
不同版本集群的healthcheck原理不尽相同,但是会导致com.google.common.util.concurrent.UncheckedTimeoutException: java.util.concurrent.TimeoutException 这个报错跟集群版本没有关联,其大致的原因有以下几个
1、防火墙、网络
首先确定集群中防火墙关闭,manager节点跟其他所有节点的agent通信没有问题。
2、配置了nameserver
根据TDH安装手册要求,配置文件/etc/resolv.conf中不能配置任何namesever,一切域名解析都用/etc/hosts来实现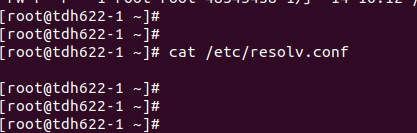
3、manager自身故障
manager进程启动过程中部分功能未完成也有可能导致该问题,可以尝试重启manager ,然后检查/var/log/transwarp-manager/master/transwarp-manager.log中是否有报错。
比如,这里的结果如果显示是“unknown”,那么一定是manager本身出问题了
4、Manager高可用
Manager HA开启时,有时也会出现该问题,此时关掉所有manager节点的进程,之后只启动初始的 manager节点(一般就是 TOS registry节点)上进程,之后即可恢复
5、服务进程残留
服务进程非正常退出,有时会有进程残留,这会影响到healthcheck,因为healthcheck一般都是去检查对应的端口,如果残留进程此时仍在监听端口,就会影响到healthcheck的。
解决方法是先在页面上把服务停掉,然后后台去检查对应的端口是否还在监听。
举个例子:
gaurdian的健康检查原理是检查8380跟8393端口上的api,现场排查发现8393也就是cas server页面无法打开,后台查看端口确实是监听的。
于是在页面上停掉了cas server,却发现8393还在被监听,ps -ef发现也是一个 cas server进程,但是启动时间对不上,应该是非正常退出的残留,kill掉这个进程,保证端口没有被监听,然后启动 cas server 成功后guardian状态恢复正常。
TDH各个服务的healthcheck原理参考: http://172.16.1.168:8090/display/TDHMAN/2.+metainfo.yaml