概要描述
Transporter(TDT)是一个数据ETL工具,支持从不同数据源获取数据。
Transporter基本配置:
- 左侧连接数据源,如关系型数据库Oracle
- 右侧连接目标数据库系统,如Inceptor
- 数据输入选择JDBCReader
- 数据输出选择JDBCBunchWriter
本案例介绍 TDT 如何从Oracle导出数据,导入到Inceptor.
详细说明
一、准备工作,复制JDBC驱动到HDFS & Transporter容器
将JDBC驱动(ojdbc6.jar)复制到如下两处:
- HDFS /tmp目录
- Transporter容器的/tmp目录
JDBC驱动为通用驱动文件,使用者可以从Oracle官网下载:
https://www.oracle.com/database/technologies/jdbcdriver-ucp-downloads.html
-
将 ojdbc6.jar 驱动文件复制到Transporter对应的节点服务器 /tmp 目录,并确认驱动文件正确无误;
可以参照KB:如何进入某一组件的Docker容器 确定Transporter对应的节点服务器。本例中Transporter安装在bryan3节点上:
[root@bryan3 ~]# ll /tmp/ojdbc6.jar -rw-r--r-- 1 root root 2739670 Oct 12 23:54 /tmp/ojdbc6.jar [root@bryan3 ~]# md5sum /tmp/ojdbc6.jar 76852c42c44401f44d26319a74e55f5b /tmp/ojdbc6.jar [root@bryan3 ~]# sha1sum /tmp/ojdbc6.jar a483a046eee2f404d864a6ff5b09dc0e1be3fe6c /tmp/ojdbc6.jar -
将 ojdbc6.jar 驱动文件复制到HDFS的/tmp目录,命令:hdfs dfs -put /tmp/ojdbc6.jar /tmp/
注:需要准备TDH客户端环境,可以参照KB:准备TDH客户端环境[root@bryan3 ~]# hdfs dfs -put /tmp/ojdbc6.jar /tmp/ -
获取Transporter组件对应的容器ID (Contrainer ID)
[root@bryan3 ~]# docker ps |grep tdt 4c006d32a482 bryan1:5000/transwarp/tdt "boot.sh TDT_SERVER" 6 hours ago Up 6 hours k8s_transporter-server-transporter1_transporter-server-transporter1-65756bbb4-kzgts_default_f69a219c-ecd1-11e9-988b-000c29bc09c8_0 //4c006d32a482即为Transporter的Container ID -
将驱动文件 ojdbc6.jar 复制到Transporter容器/tmp目录下,命令:docker cp /tmp/ojdbc6.jar Contrainer_ID:/tmp
[root@bryan3 ~]# docker cp /tmp/ojdbc6.jar 4c006d32a482:/tmp -
进入容器,确认驱动文件复制无误,命令:docker exec -it Container_ID bash
[root@bryan3 ~]# docker exec -it 4c006d32a482 bash [root@bryan3 ~]# ll /tmp/ojdbc6.jar -rw-r--r-- 1 root root 2739670 Oct 12 23:54 /tmp/ojdbc6.jar [root@bryan3 ~]# md5sum /tmp/ojdbc6.jar 76852c42c44401f44d26319a74e55f5b /tmp/ojdbc6.jar [root@bryan3 ~]# sha1sum /tmp/ojdbc6.jar a483a046eee2f404d864a6ff5b09dc0e1be3fe6c /tmp/ojdbc6.jar
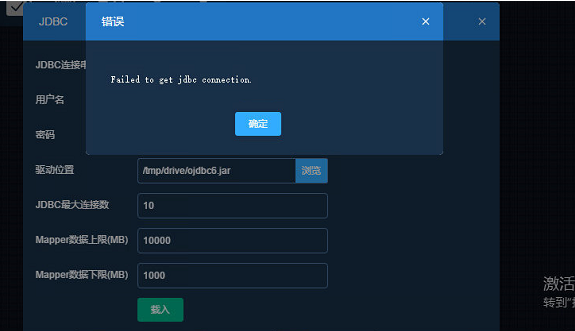
备注:如果遗漏准备工作会触发该报错:Failed to get jdbc connection
JDBCReader通过JDBC连接数据库,以Oracle数据库作为输入源。调试的时候,报错:Failed to get jdbc connection。如下图:
二、定义数据输入
- 打开Transporter页面 http://transport_node:8100 本示例中,为http://bryan3:8100
- 定义数据流,拖拽 JDBCReader 到dataflow编辑界面,点击编辑,进入编辑页面:
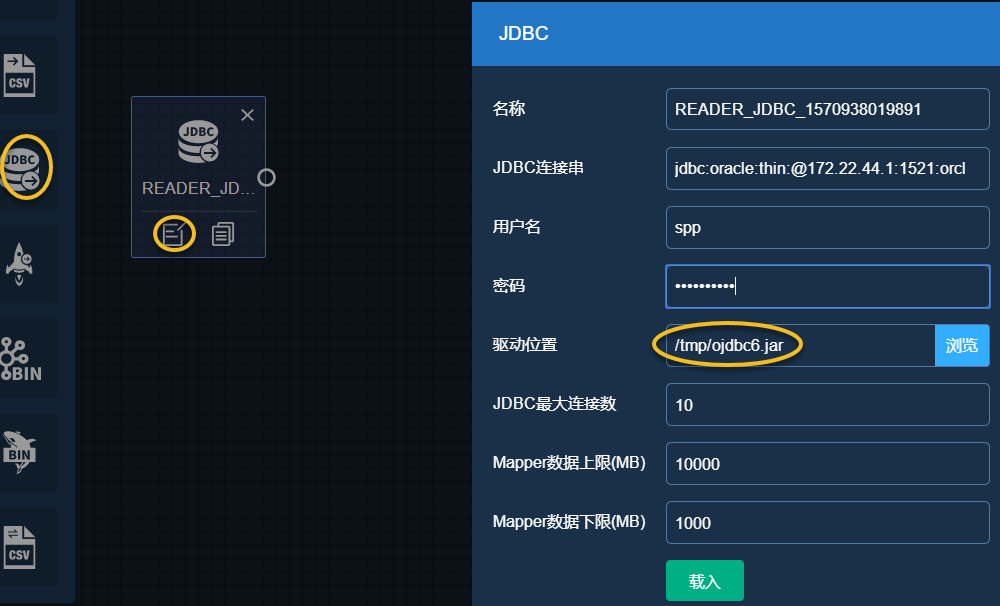
- 名称:任意填写即可;
- Oracle JDBC连接串格式:jdbc:oracle:thin:@{ip_address}:{port}:{service}
- 用户名、密码依据实际情况填写。
- 驱动位置为HDFS中JDBC驱动文件位置,为步骤(一.2)中复制到HDFS的位置,本案例为/tmp/ojdbc6.jar
- JDBC最大连接数,默认为10
- Mapper数据上限、Mapper数据下限,单个连接一次处理的数据大小,上限默认10000, 下限默认1000
注:添加驱动时,目录为hdfs目录,非宿主机的。而是为步骤(一.2)中复制到HDFS的位置,本案例为/tmp/ojdbc6.jar
三、定义数据输出
拖拽 JDBCBunchWriter 到dataflow编辑界面,点击编辑,进入编辑页面:
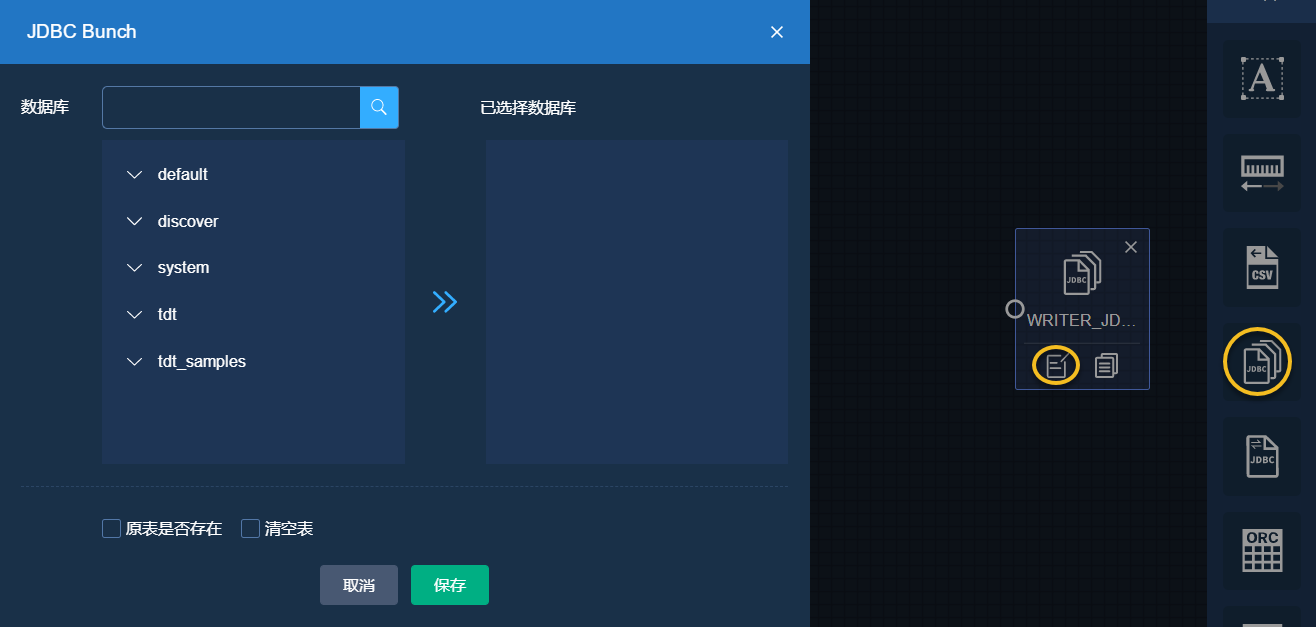
- 数据库:在滚动列表框中选择输出表目标到数据库
- 原表是否存在:目标表是否已经存在,由于JDBCReader输出多张表,勾选后要求目标数据库里存在和JDBCReader输出表相同的表
- 清空表:执行数据同步之前,如果目标表存在,是否清空目标表原有数据;