概要描述
注意:argodb高版本支持skewjoin,可以通过skewjoin解决部分jonkey倾斜的问题。
数据倾斜发生的现象:
- 绝大多数task执行得都非常快,但个别task执行极慢。比如,总共有1000个task,997个task都在1分钟之内执行完了,但是剩余两三个task却要一两个小时。这种情况很常见。
- 原本能够正常执行的Spark作业,某天突然报出OOM(内存溢出)异常,观察异常栈,是我们写的业务代码造成的。这种情况比较少见。
数据倾斜发生的原理:
数据倾斜的原理很简单:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作。
此时如果某个key对应的数据量特别大的话,就会发生数据倾斜。比如大部分key对应10条数据,但是个别key却对应了100万条数据,那么大部分task可能就只会分配到10条数据,然后1秒钟就运行完了;
但是个别task可能分配到了100万数据,要运行一两个小时。因此,整个Spark作业的运行进度是由运行时间最长的那个task决定的。
因此出现数据倾斜的时候,Spark作业看起来会运行得非常缓慢,甚至可能因为某个task处理的数据量过大导致内存溢出。
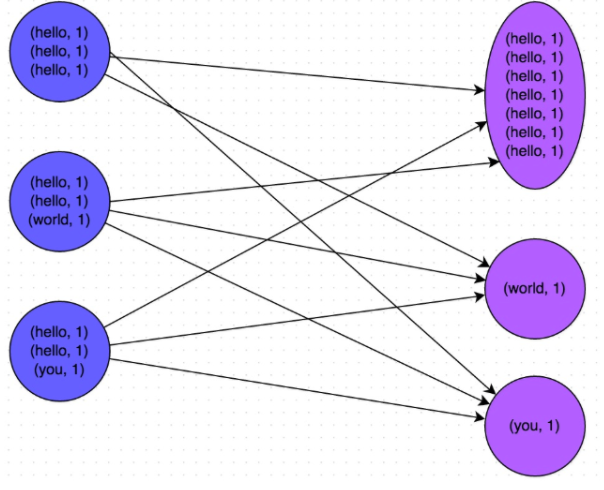
下图就是一个很清晰的例子:hello这个key,在三个节点上对应了总共7条数据,这些数据都会被拉取到同一个task中进行处理;而world和you这两个key分别才对应1条数据,所以另外两个task只要分别处理1条数据即可。此时第一个task的运行时间可能是另外两个task的7倍,而整个stage的运行速度也由运行最慢的那个task所决定。
详细说明
问题现象
--执行卡死的sql语句
SELECT
a.cust_id AS apptid --投保人ID
, h.GENDERCODE_N AS GENDERCODE_N1
, to_char(a.CVALIDATE, 'YYYY')
- to_char(h.BIRTHDAY, 'YYYY') AS age1
, CASE WHEN a.PERSONTYPE_ID = '0' THEN
a.cust_id
WHEN a.PERSONTYPE_ID = '1' THEN
b.cust_id
END AS insur_id ---被保人ID
, i.GENDERCODE_N AS GENDERCODE_N2
, to_char(a.CVALIDATE, 'YYYY')
- to_char(i.BIRTHDAY, 'YYYY') AS age2
, a.polno --保单号
, a.CVALIDATE --生效时间
, c.applydate
, CASE WHEN c.REALPAY1 IS NULL THEN
'否'
ELSE
'是'
END AS givetype
, c.REALPAY1
, c.result
, i.CONTACTADD
, e.CORRECT_REL_NAME
, CASE WHEN a.SALECHNL = 'n2' AND a.agentcode LIKE '00%' THEN
'代理人微信'
ELSE
f.channel_name
END AS salechnl
, CASE WHEN a.agentcode LIKE 'WX%' THEN
g.wx_name
END AS third
, a.RISKCODE_N --主险名称
, to_char(a.PAYENDDATE, 'YYYY')
- to_char(a.CVALIDATE, 'YYYY') AS jiaofei
, a.YEARS
, a.STATETYPE
FROM
SUM_CU_RISK_DTL a
LEFT JOIN SUM_CU_RISK_DTL b
ON a.polno = b.polno AND b.PERSONTYPE_ID IN ('2')
LEFT JOIN pro_claim c
ON trim(c.contno) = a.polno
LEFT JOIN ITG_IP_FAML_ALL_D d
ON d.polno = a.polno AND stat_day = '20210202'
LEFT JOIN D_CORRECT_REL e
ON d.CORRECT_REL = e.CORRECT_REL
LEFT JOIN D_SALECHNL f
ON f.salechnl_id = a.SALECHNL
LEFT JOIN d_agent_wx g
ON g.wx_id = a.agentcode
LEFT JOIN sum_cu_per h
ON h.cust_id = a.cust_id
LEFT JOIN sum_cu_per i
ON i.cust_id
= (CASE
WHEN a.PERSONTYPE_ID = '0' THEN a.cust_id
WHEN a.PERSONTYPE_ID = '1' THEN b.cust_id
END)
WHERE
a.polno
IN (SELECT
DISTINCT polno
FROM
SUM_CU_RISK_DTL
WHERE
riskcode IN ('5310063', '5310040', '5310122', '5310265'))
AND a.RISKSUBTYPE = 'M'
AND a.PERSONTYPE_ID IN ('0', '1')
AND a.STATETYPE IN ('1', '4');排查思路
上述是一段取自客户的数据倾斜的语句,通过DAG图可以看到在执行和h表的common join过程中,该stage的一个task有明显的拖尾现象。所以基本可以断定是这两侧的joinkey数据过于集中导致的。
可以通过下面的语句,对两侧的joinkey做聚合查询,确认一下是否joinkey 过于集中
--h表,joinkey分布均匀且该表数据量较大(无法走mapjoin)
SELECT cust_id,count(*) FROM sum_cu_per h GROUP BY cust_id ORDER BY 2 DESC LIMIT 10;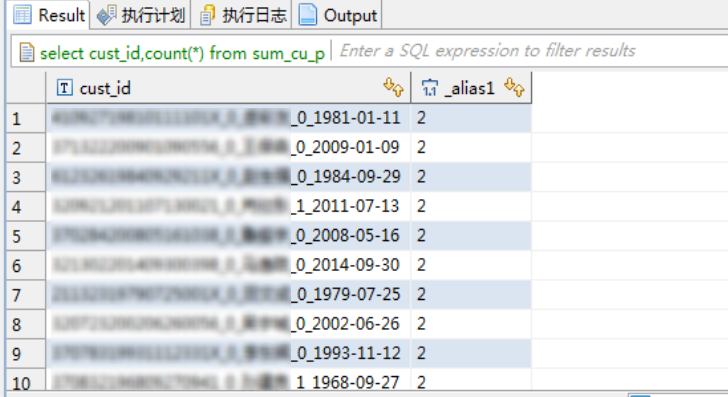
--前置表
SELECT a.cust_id, count(*)
FROM SUM_CU_RISK_DTL a
LEFT JOIN SUM_CU_RISK_DTL b
ON a.polno = b.polno
AND b.PERSONTYPE_ID IN ('2')
LEFT JOIN pro_claim c
ON trim(c.contno) = a.polno
LEFT JOIN ITG_IP_FAML_ALL_D d
ON d.polno = a.polno
AND stat_day = '20210202'
LEFT JOIN D_CORRECT_REL e
ON d.CORRECT_REL = e.CORRECT_REL
LEFT JOIN D_SALECHNL f
ON f.salechnl_id = a.SALECHNL
LEFT JOIN d_agent_wx g
ON g.wx_id = a.agentcode
WHERE a.RISKSUBTYPE = 'M'
AND a.PERSONTYPE_ID IN ('0', '1')
AND a.STATETYPE IN ('1', '4')
GROUP BY a.cust_id
ORDER BY 2 DESC
LIMIT 10;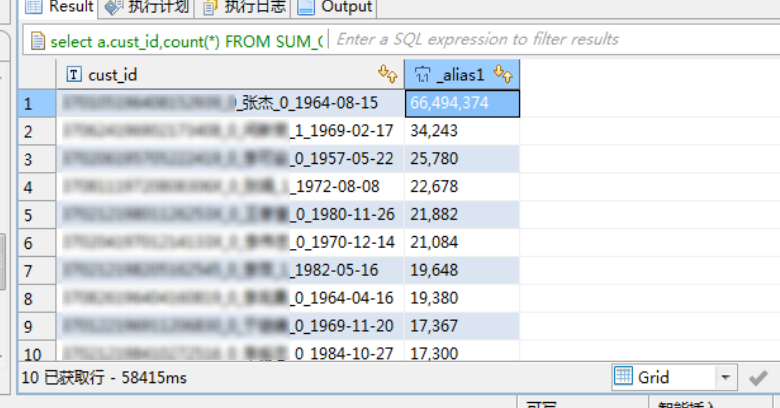
可以看到,在前置表出现了关于cust_id过于集中的现象,XXXX_张杰_0_1964-08-15的这条数据达到了6649w条,其他的只有2-3w条,相差几个数量级;
解决方案
- 从业务上来说,如果该条数据对作业的执行和计算结果不是特别重要的话,那么干脆就直接过滤掉这个key;
–当前问题,客户不同意剔除该key. - 如果是维度表重复数据过多,可以考虑对维度表distinct去重;
–当前问题,h表重复数据最多2条所以并不适用. - 改写sql,将这个倾斜的key值单独拎出来走mapjoin,不走shuffle,然后与其他key 值的结果集做union all;
–如下.
改写sql 的逻辑,就是把cust_id='XXXX_0_张杰_0_1964-08-15'的这条记录单独拿出来,和h表的这条记录走mapjoin(只有2条),规避掉shuffle过程;结果集再union all,改写后如下
SELECT
--Select expressions部分省略
FROM SUM_CU_RISK_DTL a
LEFT JOIN SUM_CU_RISK_DTL b
ON a.polno = b.polno
AND b.PERSONTYPE_ID IN ('2')
LEFT JOIN pro_claim c
ON trim(c.contno) = a.polno
LEFT JOIN ITG_IP_FAML_ALL_D d
ON d.polno = a.polno
AND stat_day = '20210202'
LEFT JOIN D_CORRECT_REL e
ON d.CORRECT_REL = e.CORRECT_REL
LEFT JOIN D_SALECHNL f
ON f.salechnl_id = a.SALECHNL
LEFT JOIN d_agent_wx g
ON g.wx_id = a.agentcode
LEFT JOIN sum_cu_per h
ON h.cust_id = a.cust_id
LEFT JOIN sum_cu_per i
ON i.cust_id = (CASE
WHEN a.PERSONTYPE_ID = '0' THEN
a.cust_id
WHEN a.PERSONTYPE_ID = '1' THEN
b.cust_id
END)
WHERE a.polno IN
(SELECT DISTINCT polno
from SUM_CU_RISK_DTL
where riskcode in ('5310063', '5310040', '5310122', '5310265'))
AND a.RISKSUBTYPE = 'M'
AND a.PERSONTYPE_ID IN ('0', '1')
AND a.STATETYPE IN ('1', '4')
--ppd优化器,在这里对a表做FilterOperator等同于放在TableScanOperator里面
AND a.cust_id != 'XXXX__张杰_0_1964-08-15'
UNION ALL
SELECT
--为了防止h不走小表广播,可以强制hint
/*+ MAPJOIN(h)*/
--Select expressions部分省略
FROM SUM_CU_RISK_DTL a
LEFT JOIN SUM_CU_RISK_DTL b
ON a.polno = b.polno
AND b.PERSONTYPE_ID IN ('2')
LEFT JOIN pro_claim c
ON trim(c.contno) = a.polno
LEFT JOIN ITG_IP_FAML_ALL_D d
ON d.polno = a.polno
AND stat_day = '20210202'
LEFT JOIN D_CORRECT_REL e
ON d.CORRECT_REL = e.CORRECT_REL
LEFT JOIN D_SALECHNL f
ON f.salechnl_id = a.SALECHNL
LEFT JOIN d_agent_wx g
ON g.wx_id = a.agentcode
--重点关注下面这部分
LEFT JOIN (select GENDERCODE_N, BIRTHDAY, cust_id
from sum_cu_per
where cust_id = 'XXXX_0_张杰_0_1964-08-15') h
ON h.cust_id = a.cust_id
LEFT JOIN sum_cu_per i
ON i.cust_id = (CASE
WHEN a.PERSONTYPE_ID = '0' THEN
a.cust_id
WHEN a.PERSONTYPE_ID = '1' THEN
b.cust_id
END)
WHERE a.polno IN
(SELECT DISTINCT polno
from SUM_CU_RISK_DTL
where riskcode in ('5310063', '5310040', '5310122', '5310265'))
AND a.RISKSUBTYPE = 'M'
AND a.PERSONTYPE_ID IN ('0', '1')
AND a.STATETYPE IN ('1', '4')
--ppd优化器,在这里对a表做FilterOperator等同于放在TableScanOperator里面
AND a.cust_id = 'XXXX_0_张杰_0_1964-08-15';FAQ
查找集中的joinkey的方法:
这个是原始的报错语句:
SELECT
...
FROM ods.ods_hisdb_DrugPC a
INNER JOIN ods.ods_hisdb_vdrugwastebook_df b
ON a.kcid = b.serialno AND b.ds='20240107'
WHERE a.status IN (2) and a.tabletype='mid';我们通过如下sql排查joinkey的集中情况:
方法一:分别聚合查询统计
SELECT a.kcid, count(*) AS cnt1
FROM ods.ods_hisdb_DrugPC a WHERE a.status IN (2) and a.tabletype='mid' GROUP BY a.kcid ORDER BY cnt1 desc limit 10;
SELECT b.serialno, count(*) AS cnt2
FROM ods.ods_hisdb_vdrugwastebook_df b GROUP BY b.serialno ORDER BY cnt2 desc limit 10;方法二:如果倾斜不是太严重,能join出结果,可以用下面的方式继续判断:
SELECT t1.empno,count(*) AS cnt
FROM emp t1
JOIN emp_orc t2
ON t1.empno=t2.empno
WHERE a.status IN (2) and a.tabletype='mid'
GROUP BY t1.empno ORDER BY cnt DESC LIMIT 10;方法三:如果倾斜非常严重,join不出结果,可以用下面的方式继续判断(会展示出左右joinkey的数量):
注意:下面的语句会把null的场景忽略掉
WITH
tb1 AS
(SELECT a.kcid, count(*) AS cnt1 FROM ods.ods_hisdb_DrugPC a WHERE a.status IN (2) and a.tabletype='mid' GROUP BY a.kcid ),
tb2 AS
(SELECT b.serialno, count(*) AS cnt2 FROM ods.ods_hisdb_vdrugwastebook_df b GROUP BY b.serialno )
SELECT tb1.kcid,tb1.cnt1,tb2.cnt2,tb1.cnt1*tb2.cnt2 AS totalcnt
FROM tb1
JOIN tb2
ON tb1.kcid=tb2.serialno
ORDER BY totalcnt DESC
LIMIT 10;