概要描述
在HDFS集群运维过程中,常会碰到因为实际业务增长低于集群创建时的预估规模;集群数据迁出,数据节点冗余较多;费用控制等原因,需要对集群进行缩容操作。Decommission DataNode是该过程中关键的一步,就是把DataNode从集群中移除掉。那问题来了,HDFS在设计时就把诸如机器故障考虑进去了,能否直接把某台运行Datanode的机器关掉然后拔走呢?理论上可行的,不过在实际的集群中,如果某份数据只有一份副本而且它就在这个机器上,那么直接关掉并拔走机器就会造成数据丢失。
本文主要围绕客户遇到的退役卡死的问题进行解释说明,希望大家在遇到该类问题时有一个排查的思路。
详细说明
问题现象
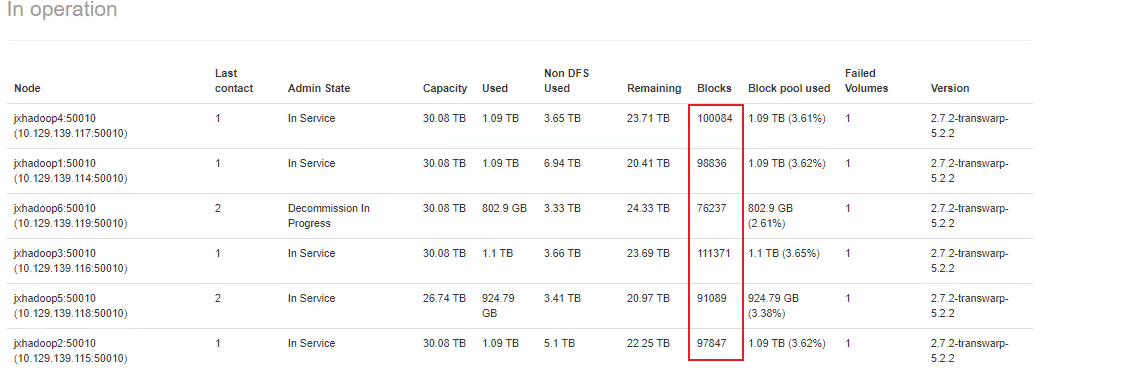
客户在manager页面操作一个datanode节点退役时,发现该dn在Decommision in Progress状态十几个小时一直卡着不动,其他datanode的日志里面也没有再刷Receiving和Received的日志。这代表着退役的操作出现了问题,需要进行排查。

思路
ANN日志中一直在刷Failed to place enough replicas的报错:

1、hdfs不在safe-mode;
2、dn全部正常;
3、磁盘空间剩余量充足,没到reserved的阈值;
4、dfs.datanode.handler.count为100,dn日志也没有报错;
5、提高退役速度的参数设置
dfs.namenode.replication.max-streams
dfs.namenode.replication.max-streams-hard-limit
dfs.namenode.replication.work.multiplier.per.iteration上述检查都解决不了问题。
然后执行hdfs fsck / > fsck.log命令输出fsck日志发现,日志中全是Replica placement policy is violated for BP-239243576-10.129.139.120-1576050513780:blk_1088800851_15060386. Block should be additionally replicated on 1 more rack(s). 的报错,大概知道了问题所在:
如果在停用之前DataNodes驻留在一个以上的机架中,但之后仅剩一个机架,则停用失败,因为无法将副本迁移到相同的机架。
当前退役的DN确实是单独在rack2机架上的一个节点,
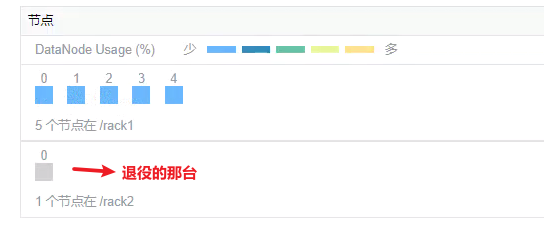
解决方案
TDH中hdfs的机架感知是通过如下的两个参数配置决定的,
net.topology.node.switch.mapping.impl
org.apache.hadoop.net.ScriptBasedMapping
net.topology.script.file.name
/usr/lib/transwarp/scripts/rack_map.sh
将/usr/lib/transwarp/scripts/rack_map.sh修改其中的result,写死这个rack名称,无论哪个 hostname 都反回这个 rack
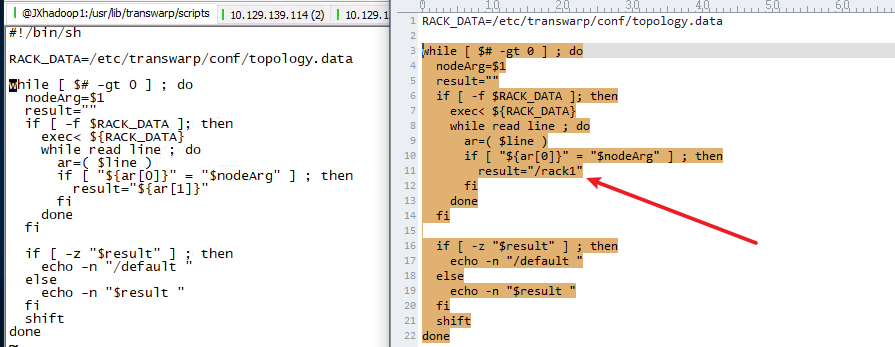
该脚本的原理是:
接受一个参数,输出一个值。接受的参数通常为某台datanode机器的ip地址,而输出的值通常为该ip地址对应的datanode所在的rack,例如”/rack1”。Namenode启动时,会判断该配置选项是否为空,如果非空,则表示已经启用机架感知的配置,此时namenode会根据配置寻找该脚本,并在接收到每一个datanode的heartbeat时,将该datanode的ip地址作为参数传给该脚本运行,并将得到的输出作为该datanode所属的机架ID,保存到内存的一个map中.
下面是具体的解决步骤:
1、容器内操作,先备份这个脚本/usr/lib/transwarp/scripts/rack_map.sh,比如 rack_map.sh.tmp;
2、修改该脚本,写死rack名称,全部返回rack1, 然后做镜像持久化;
3、重启 namenode 触发 nn 机架感知 (2 中只返回你要的机架, 不包含不需要的机架),重启的时候要保证没有业务进来;
4、等重启完成了, 这时候 nn 是不知道 rack2 存在的,过一段时间 nn 就会重新 copy 副本,保证 rack1 的 dn 节点之间副本 copy。等副本都同步完了, 就可以下掉 rack2 了;
5、把这个脚本修改回去,然后镜像持久化。