概要描述
目前 TDH 暂时不支持在界面直接更改集群 IP,若有更改 IP 需求,需要手动操作。
以下步骤在操作过程中任何一步遇到问题,请联系星环科技售后服务:service@transwarp.io
修改 IP 前须知:
-
请仔细阅读文档!相关命令按需更改,特别是很多步骤中涉及的 pod 名字,IP 地址,数据库密码等。不要一昧的复制!
-
TDH 只允许修改 IP,不能修改 hostname;
-
检查集群内 所有节点是否有 transwarp/gencerts 镜像,没有该镜像的节点执行以下命令获取:
docker load -i /etc/tos/conf/tos.tar.gz
-
修改集群 IP 期间暂停对 TDH 的所有操作;
-
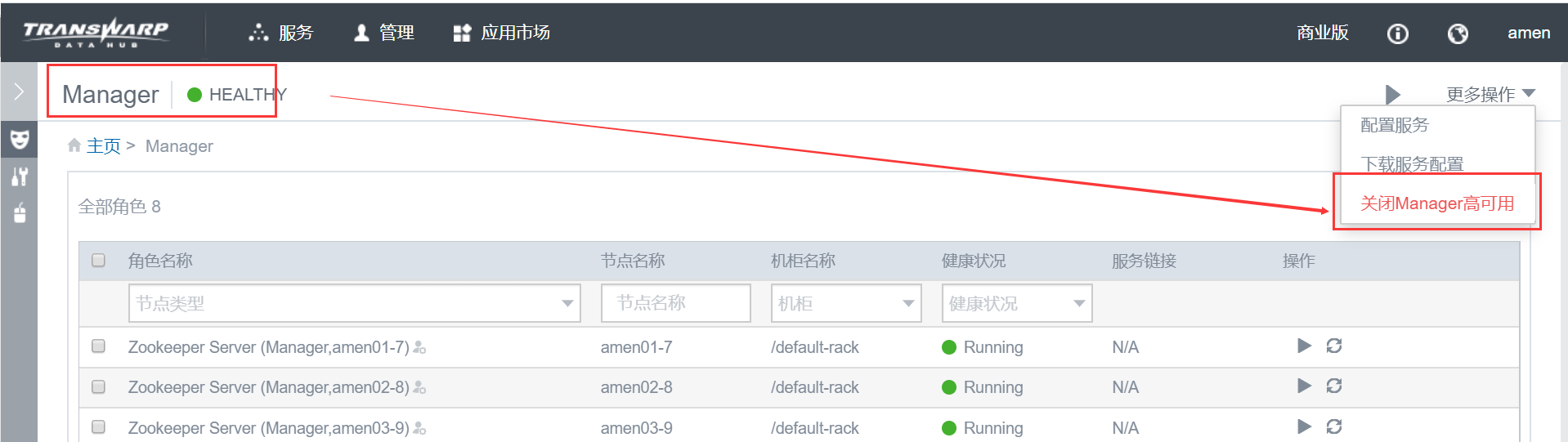
若 Manager 开启了高可用(HA),需要 先关闭 Manager HA;
-
TDH 5.0 及以上版本 的 txsql 不支持更换 IP,需要先导出 txsql 的元数据,更改 IP 后重新初始化 txsql,再把备份的元数据导入;
-
TDH 5.2 以上版本需要先导出 guardian txsql 的元数据,更改 IP 后重新初始化 guardian txsql,再把备份的元数据导入,TDH 5.1 版本没有 guardian txsql 角色,不需要该操作。
本次实验IP映射关系:
| 旧IP | 新IP |
|---|---|
| 172.22.33.1 | 172.22.33.33 |
| 172.22.33.2 | 172.22.33.34 |
| 172.22.33.3 | 172.22.33.35 |
详细说明
一、备份 TxSQL 元数据
参照 TxSQL元数据备份与恢复 详细说明的 步骤一、二、三 备份 txsql 元数据。
二、备份 guardian txsql 元数据
注意:
- 如果是 TDH 5.1 版本 或者 没有安装 guardian 服务,此步骤略过;
- 该步骤登录 guardian txsql 时使用的端口默认是 8323,密码是 pod 内文件 /etc/guardian/conf/db.properties 变量 db.password 的值,本实验中该值是 -726701776 ;
-
确定 guardian txsql 的 master 节点
进入任一 guardian txsql 的 pod 内,执行以下命令获取 master 节点,以下示例中获得 master 节点是 172.22.33.3:# 获取 guardian txsq l的 pod 信息 [root@mll01 ~]# kubectl get pod -owide | grep txsql-server-guardian txsql-server-guardian-58cbd775bf-8grdp 1/1 Running 0 23h 172.22.33.2 mll02 txsql-server-guardian-58cbd775bf-j5fxt 1/1 Running 0 23h 172.22.33.1 mll01 txsql-server-guardian-58cbd775bf-wvcpw 1/1 Running 0 23h 172.22.33.3 mll03# 进入任一 guardian txsql 的 pod [root@mll01 ~]# kubectl exec -it txsql-server-guardian-58cbd775bf-8grdp bash# 执行命令获取 master 节点,由下可知 172.22.33.3 是 master 节点 [root@mll02 /]# /usr/bin/txsql/tools/txsql.sh list get master 172.22.33.3 expire time 1583065627 Sun Mar 1 20:27:07 2020 ip 172.22.33.1 port 8324 ip 172.22.33.2 port 8324 ip 172.22.33.3 port 8324 -
修改数据库中 IP 地址
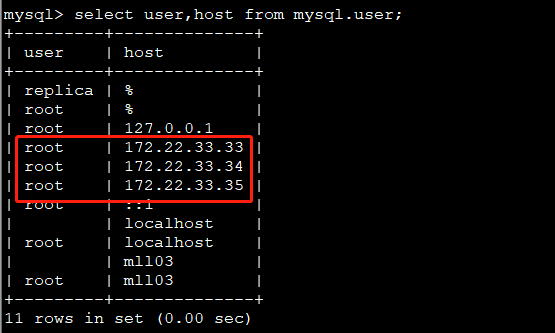
在 master 节点(172.22.33.3)进入 mysql,修改mysql.user表中host列的 IP 地址,将旧的 IP 地址更改为新的 IP 地址# 进入 172.22.33.3 节点 guardian txsql 的 pod [root@mll01 ~]# kubectl exec -it txsql-server-guardian-58cbd775bf-wvcpw bash# 执行命令进入该节点的 txsql [root@mll03 /]# /usr/bin/txsql/tools/txsql.sh localshell// 进入数据库执行执行下面命令修改数据库中的 IP 地址 mysql> set global super_read_only=0; mysql> set global read_only=0; mysql> set sql_log_bin=0; // 修改 IP:update mysql.user set host = 'new_ip' where host = 'old_ip'; mysql> update mysql.user set host = '172.22.33.33' where host = '172.22.33.1'; mysql> update mysql.user set host = '172.22.33.34' where host = '172.22.33.2'; mysql> update mysql.user set host = '172.22.33.35' where host = '172.22.33.3';数据库中修改 IP 之后,可以在数据库中执行命令:
select user,host from mysql.user;查看是否修改成功
-
备份 master 节点的元数据
进入 172.22.33.3 节点 guardian txsql 的 pod,可以在 pod 内默认的持久化路径/var/log/guardian/下执行 mysqldump 命令进行备份,省去 pod 内外传输文件。
备份命令:/usr/bin/txsql/percona.src/bin/mysqldump -h172.22.33.3 -P8323 -uroot -p'-726701776' --set-gtid-purged=off --triggers --routines --events --all-databases > /var/log/guardian/guardian-alldata.sql
根据实际情况修改上述命令中的 IP 和密码,不要复制!
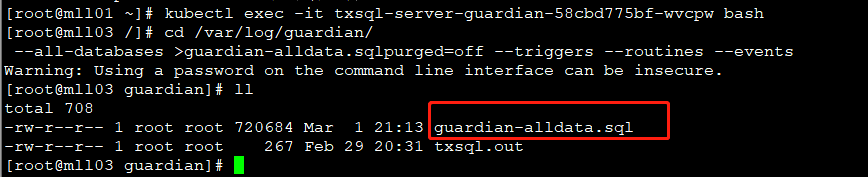
此步骤操作完之后,一定要登录到 172.22.33.3 这台服务器上,确认宿主机 /var/log/guardian/ 该路径下已经有上一步生成的备份文件 guardian-alldata.sql。
三、停止所有服务
-
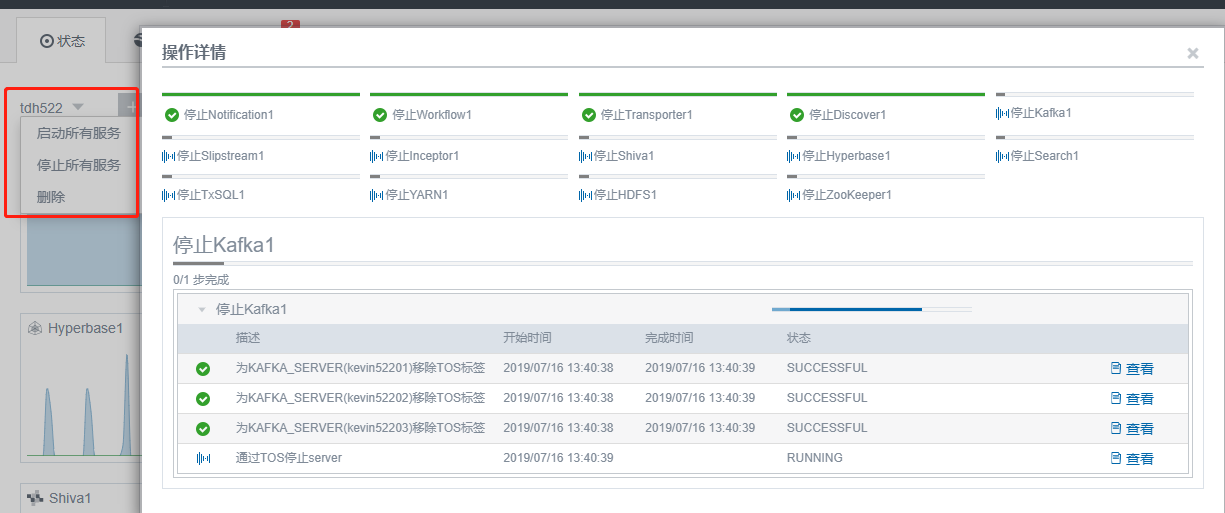
停止所有服务
登录 Manager 页面 (http://manager_ip:8180),点击 状态 > 集群名称 > 停止所有服务:
manager web 页面 – 状态 – 集群名称 – 停止所有服务
-
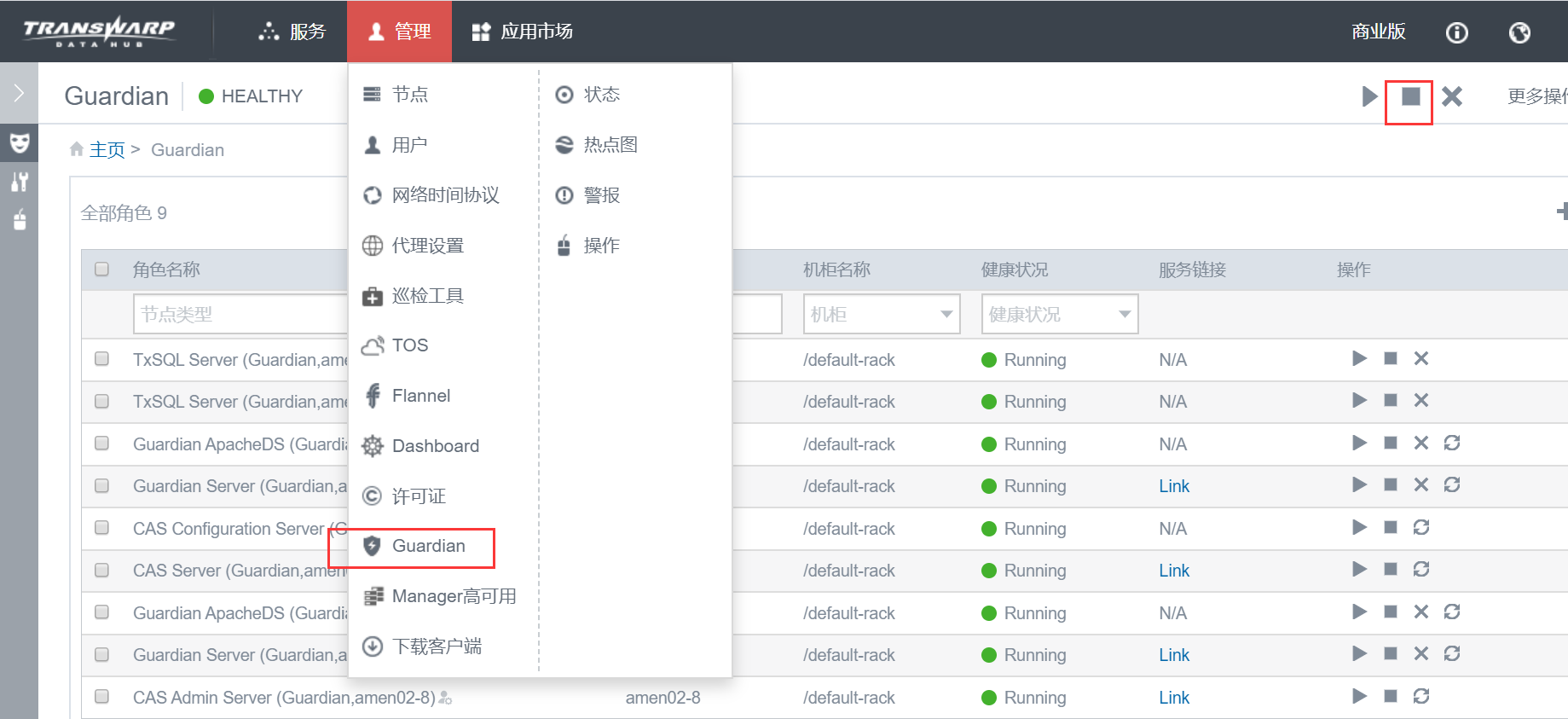
停止 Guardian
注意:没有安装 guardian 则跳过此步骤
在 Manager 页面,点击 管理 > Guardian,点击正方形按钮停止
-
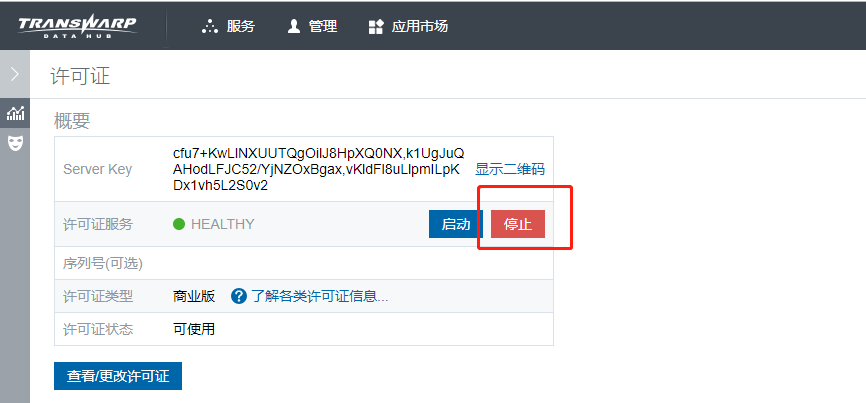
停止 License 服务
在 Manager 页面,点击 管理 > 许可证 > 停止 按钮
-
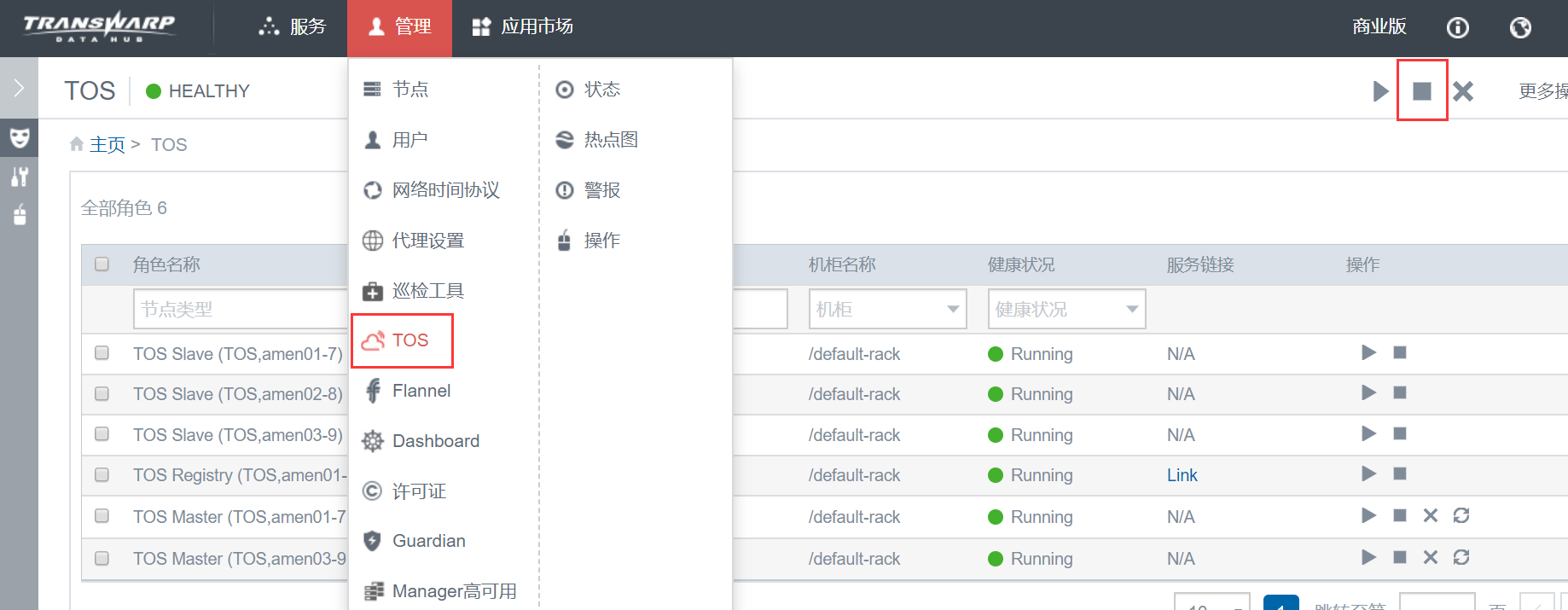
停止 TOS
在 Manager 页面,点击 管理 > TOS,点击正方形按钮停止
-
在 TDH 集群 每一个节点服务器上 ,查看确认 TOS 相关 container 已经停止。若有尚未停止的 container,手动停止。命令参考:
# docker ps //查看container # docker stop CONTAINER ID //手动停止container
四、修改各节点 Linux 系统 IP
注意:服务器修改 IP 请联系运维人员修改
修改集群所有节点服务器 Linux 系统的 IP 为希望的新 IP,( TDH集群不能修改 hostname ),修改 IP 之后重启 network 服务使改动生效。
五、修改 TDH 配置文件
-
在安装了 Manager 的节点服务器上,修改
/etc/transwarp-manager/master/application.conf,将 hostname 参数后面的当前 IP 改为新的 IP.
注意: 本实验中 manager 节点是 172.22.33.1,此步骤在 172.22.33.1 节点操作。netty.tcp { hostname=新的manager节点的IP (注意是IP) .... }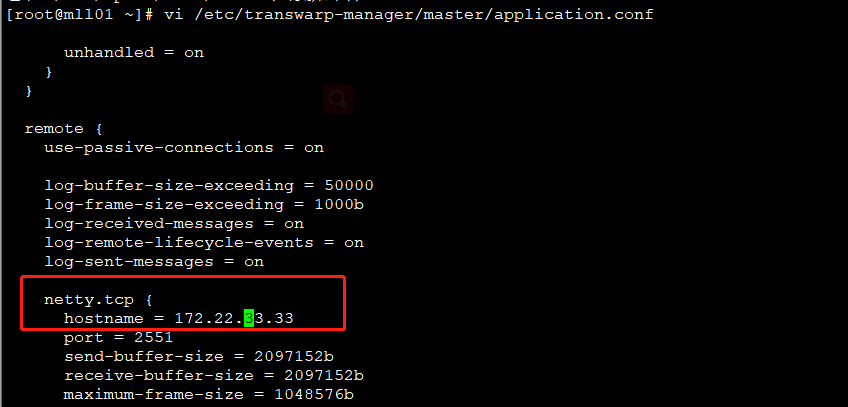
-
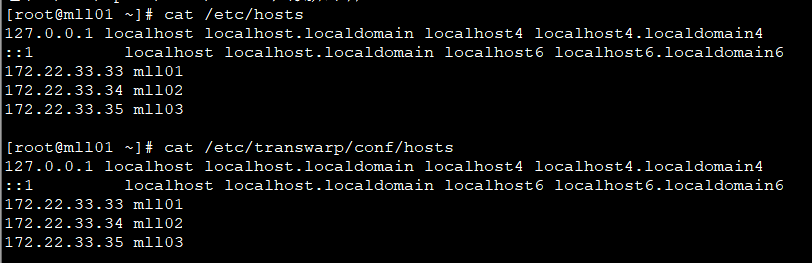
修改所有节点的 /etc/hosts 以及 /etc/transwarp/conf/hosts 文件,更新为新的 IP 地址(两个文件内容保持一致即可)
-
修改所有节点的 repo 源的地址,将旧的 IP 更改为新的 IP. 涉及文件:
- /etc/yum.repos.d/os.repo
- /etc/yum.repos.d/transwarp.repo
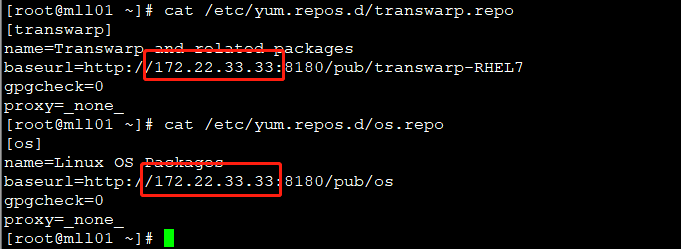
注意:如果上述文件中修改处的值是主机名,则不需要修改。
-
修改 Manager 后台数据
登录 manager 节点(172.22.33.1)的 mysql,将node表里面节点相应的 IP 更新成修改后的 IP# mysql -h localhost -u transwarp -p$(cat /etc/transwarp-manager/master/db.properties | grep io.transwarp.manager.db.password | awk -F = '{print $2}') -S /var/run/mariadb/transwarp-manager-db.sock -D transwarp_manager // 连接 transwarp_manager 数据库MariaDB [transwarp_manager]> select * from node; //查看 node 表数据值,从里面可以看到旧的 IP 地址以及对应的 hostname 信息. MariaDB [transwarp_manager]> update node set ipWhenCreate='172.22.33.33' where hostname='mll01'; //将表内IP地址逐条更改为新的IP,上述更改语句仅供参考. MariaDB [transwarp_manager]> select * from node; //全部改好后,再次确认修改无误.
-
修改 TOS 后台数据
1) 在 TDH 集群的所有节点上执行下面两个命令
//下述命令中 transwarp/gencerts:transwarp-5.2.2-final 对应当前版本的 image,可以通过 docker images |grep gencerts 命令查看当前版本的 image:

# rm -rf /srv/kubernetes/ca.crt /srv/kubernetes/kubecfg.* /srv/kubernetes/server.* # docker run --volume /srv/kubernetes/:/srv/kubernetes/ --net=host transwarp/gencerts:transwarp-5.2.2-final /usr/bin/entry.sh //此示例中,image为transwarp-5.2.2-final2) 执行完上述命令之后,进到 /srv/kubernetes/ 目录,检查下 kubecfg.pem 是否存在,如果没有生成则需要手动根据如下命令生成
# cd /srv/kubernetes/ # cat kubecfg.crt kubecfg.key > kubecfg.pem
六、检查操作
- 在所有节点上检查 IP 是否更新
# cat /srv/kubernetes/server.cert | grep IP
- 在所有节点上检查 hosts 文件
再次确认 /etc/hosts 和 /etc/transwarp/conf/hosts 内容一致,且为最新的 IP.
七、后台重启 manager 服务和 agent 服务
- 重启 Manager
只在 manager 节点执行:# /etc/init.d/transwarp-manager restart - 重启所有 Agent
所有节点都执行:# /etc/init.d/transwarp-manager-agent restart
八、启动所有服务
-
用新的 IP 登录 manager web 页面
-
配置 TOS 服务 (不可少!!!)
【更多操作 > 配置服务】

-
启动 TOS
-
启动许可证
-
启动 Guardian
注意: 没有安装 guardian 服务,此步骤略过。-
配置 guardian 服务 (不可少!!!)
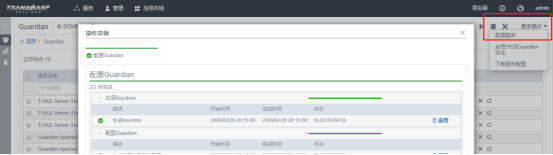
-
点击启动 guardian 服务
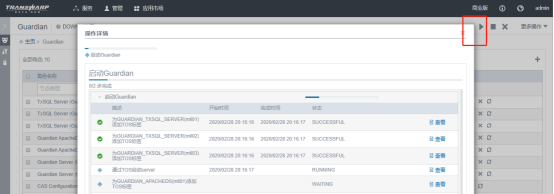
注意:如果是TDH5.1版本,不需要检查配置文件及恢复数据,直接启动即可。
配置完服务,点击启动之后,检查 guardian txsql 的所有 pod (此时 guardian txsql 的 pod 状态是0/1 running)中,确认以下文件中的 IP 是否已是修改后的 IP,如果不是请手动修改成新的 IP:/etc/guardian/conf/install_conf.sh /etc/guardian/conf/phxbinlogsvr.conf /etc/guardian/conf/phxsqlproxy.conf -
guardian txsql 重新初始化,每个 guardian txsql 角色所在节点都要操作,清空数据目录,目录不能删除( 危险动作,操作前再次确认第 二 节 guardian txsql 的备份文件已在宿主机)
查看数据目录:pod 内的文件
/etc/guardian/conf/install_conf.sh中的变量DATA_DIR值,本实验中该值为 /vdir/guardian/txsql/data/;
将该目录下所有文件移动到备份目录下, pod 内执行:cd /vdir/guardian/txsql/data/ mkdir -pv /var/log/guardian/guardian_data_bak && mv * /var/log/guardian/guardian_data_bak -
后台删除
所有guardian txsql 的 pod,delete 之后会自动重启kubectl delete pod txsql-server-guardian-XXX -
等待 manager 页面 guardian 启动成功
注意:如果上述操作超过 10 分钟,manager 页面会提示启动失败,点击 “重试” 即可。 -
恢复 guardian txsql 的数据
参考之前步骤 (第 二 节 1 部分) 再次获取 guardian txsql 的 master 节点,本实验是 172.22.33.35 节点;
确认之前备份文件 guardian-alldata.sql 在持久化路径 /var/log/guardian/ 下,如果 master 节点变化了,请将之前备份的 guardian-alldata.sql 文件上传至当前 master 的对应路径下;
进入 guardian txsql 的 master 节点的 pod,恢复数据:cd /var/log/guardian/ /usr/bin/txsql/tools/txsql.sh shell注意: 要 source 两次,第一次 source 之后执行 flush privileges; flush privileges 前必须要先 set sql_log_bin=0,否则会引起严重的错误,然后再 source 一次
mysql> source guardian-alldata.sql mysql> set sql_log_bin=0; mysql> flush privileges; mysql> source guardian-alldata.sql -
检查各个节点的流水是否一致,参考 TxSQL元数据备份与恢复 文档查看
-
-
启动 txsql
-
配置 txsql 服务 (不可少!!!)
-
点击启动 txsql 服务
配置完服务,点击启动之后,检查 txsql 的所有 pod 中,确认以下文件中的 IP 是否已是修改后的 IP:/usr/bin/txsql/etc/install_conf.sh /usr/bin/txsql/etc/txsql-env.sh -
txsql 重新初始化,清空数据目录,目录不能删除(危险动作,操作前再次确认 txsql 的备份文件已在宿主机)
查看数据目录:pod 内的文件 /etc/txsql1/conf/install_conf.sh 中的变量 DATA_DIR 值,本实验中该值为 /vdir/hadoop/txsql
将该目录下所有文件移动到备份目录下,pod 内执行:cd /vdir/hadoop/txsql mkdir -pv /var/log/txsql1/txsql_data_bak && mv * /var/log/txsql1/txsql_data_bak -
后台删除
所有txsql 的 pod,delete 之后会自动重启kubectl delete pod txsql-server-txsqlXXX -
等待 manager 页面 txsql 启动成功
-
恢复 txsql 的数据
将之前备份的 txsql 的元数据(alldata.sql)上传到 master 节点的持久化路径(/var/log/txsql1/)下,进入 master 节点的 txsql 的 pod 内,执行下面命令恢复:cd /var/log/txsql1/ /usr/bin/txsql/tools/txsql.sh localshell注意: 要 source 两次,第一次 source 之后执行 flush privileges; flush privileges 前必须要先 set sql_log_bin=0,否则会引起严重的错误,然后再 source 一次
mysql> source alldata.sql mysql> set sql_log_bin=0; mysql> flush privileges; mysql> source alldata.sql -
检查各个节点的流水是否一致,参考 TxSQL元数据备份与恢复 文档查看
-
-
在 Manager 页面,启动其他所有服务
- 检查 Kafka 的配置项 advertised.listeners 和 listeners 配置的值,如果配置的为旧 IP,请先修改为新 IP。配置的是 hostname 则不用改动;
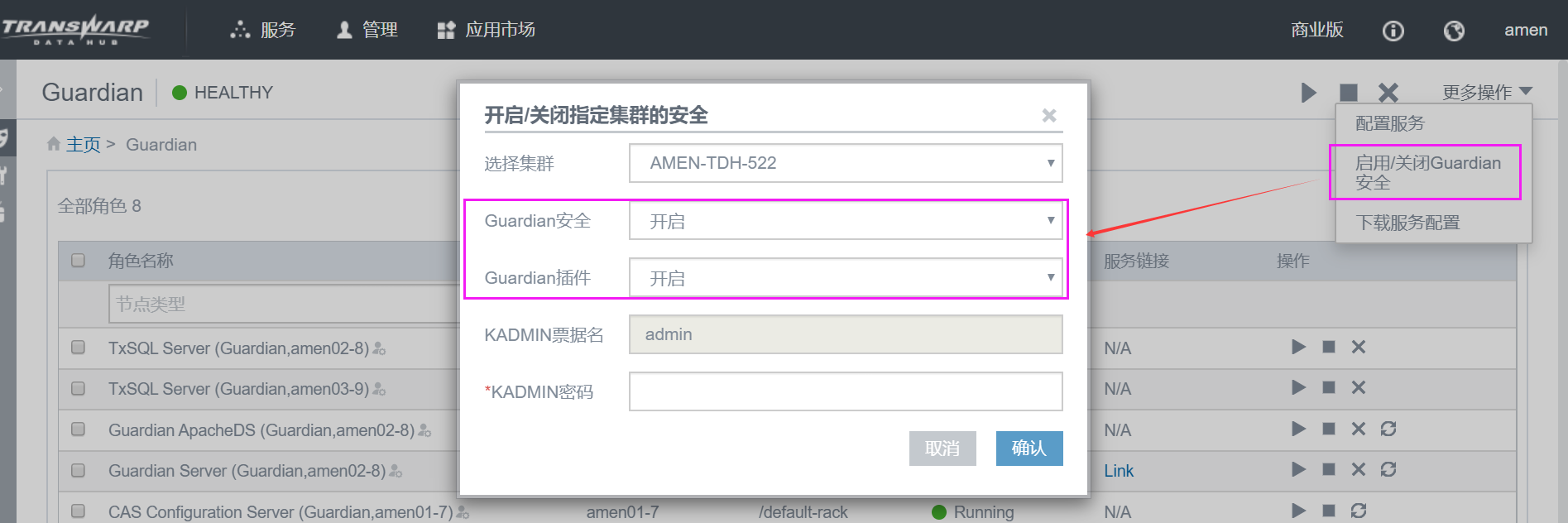
- ***** 如果集群是开启 Guardian 的 安全认证 和 插件 的,请通过统一启用 Guardian 安全的方式来启动所有服务。
FAQ
-
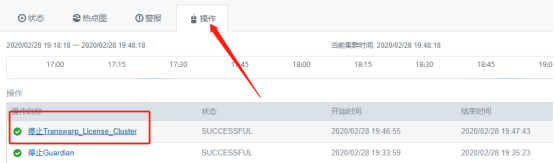
停止许可证时卡住,最后会提示失败,但后台查看 license 相关的pod(kubectl get pod | grep license)已经删了
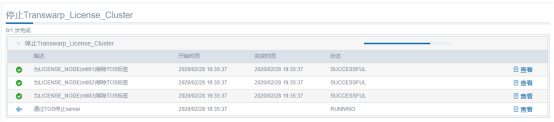

重启 manager 和所有 agent,然后重新登录 manager,在操作中查看已经停止成功。
-
启动 inceptor 时 metastore 角色启动失败,查看 metastore pod 日志报错:ERROR 1045 (28000): Access denied for user ‘inceptoruser’@’172.22.33.2’ (using password: YES)
该报错是 txsql 启动成功之后数据还没有恢复,就开始启动 inceptor 服务了,参考8.6章节先恢复 txsql 数据后再启动 inceptor 服务。