内容纲要
概要描述
表现为TOS Master起不来,即使在后台重启还是前台重启,etcd的container依旧没有正常。
详细说明
问题原因:etcd集群目前在高io的情况下或网络较差情况下会出现通信超时导致频繁切主出现has no leader的问题。
解决方案:
- 调整网络
若有下列信息,代表网络阻塞,需要做调整
dropped MsgProp to 247ae21ff9436b2d since streamMsg's sending buffer is full
dropped MsgAppResp to 247ae21ff9436b2d since streamMsg's sending buffer is full执行以下命令,提高etcd的网络通信优先级
tc qdisc add dev eno16780032 root handle 1: prio bands 3
tc filter add dev eno16780032 parent 1: protocol ip prio 1 u32 match ip sport 2380 0xffff flowid 1:1
tc filter add dev eno16780032 parent 1: protocol ip prio 1 u32 match ip dport 2380 0xffff flowid 1:1
tc filter add dev eno16780032 parent 1: protocol ip prio 2 u32 match ip sport 2379 0xffff flowid 1:1
tc filter add dev eno16780032 parent 1: protocol ip prio 2 u32 match ip dport 2379 0xffff flowid 1:1说明eno16780032 是当前节点的网卡名,2380是etcd集群相互通信的端口,2379是etcd对外提供服务的端口。
-
调整磁盘
-
调整etcd集群进程的ionice:
ionice -c1 -n0 -p \pgrep etcd\ -
有条件的话可以把etcd数据放在ssd盘下
数据存储在/opt/kubernetes/etcd下,即将ssd挂载到/opt/kubernetes/etcd下
-
-
调整时间参数
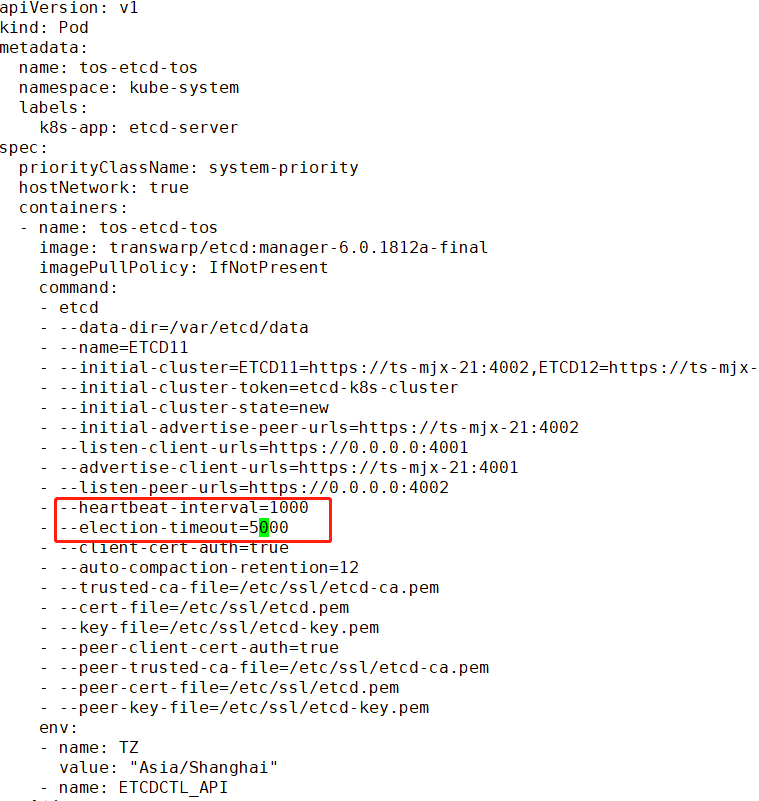
修改/opt/kubernetes/manifests-multi/tos-etcd.manifest文件
将heartbeat-interval修改为1000
将election-timeout修改为5000
这两个参数是调整etcd集群的心跳间隔和选举超时的时间,从而降低切换master的频率
见下图
-
重启etcd
# mv /opt/kubernetes/manifests-multi/tos-etcd.manifest ./等待30s
# mv ./tos-etcd.manifest /opt/kubernetes/manifests-multi/
etcd即可正常使用
其他信息
本文章只适用于节点高IO情况,且只能用来暂时缓解etcd的压力,让etcd可以正常启动,根本办法只有降低IO负载