内容纲要
概要描述
Sophon组件的一些角色pod运行不正常。
表现如下:
1.kubectl get pod -owide|grep apimanager发现pod状态是0/1或者1/1,pod处于crashloopbackoff或者running状态,并且一直在不断重启。
apimanager-sophon1-3790167053-rqq1b 1/1 Running 154 18h2.pod日志如下:
[root@node23 ~]# kubectl logs -f apimanager-sophon1-3790167053-rqq1b
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v1.5.16.RELEASE)
Jul 12, 2019 4:27:27 AM org.apache.catalina.core.StandardService startInternal
INFO: Starting service [Tomcat]
Jul 12, 2019 4:27:27 AM org.apache.catalina.core.StandardEngine startInternal
INFO: Starting Servlet Engine: Apache Tomcat/8.5.34
Jul 12, 2019 4:27:27 AM org.apache.catalina.core.ApplicationContext log
INFO: Initializing Spring embedded WebApplicationContext
Jul 12, 2019 4:32:45 AM org.apache.catalina.core.StandardService stopInternal- 后台查看对应不正常的角色(在apimanager、sharesever、base、resource都有发生),在角色对应节点的/var/log/sophonX/下 的日志报错如下,查看 pod日志也有可能直接看到这个报错。
ERROR boot.SpringApplication (SpringApplication.java:reportFailure(771)) - Application startup failed org.springframework.beans.factory.BeanCreationException:
Error creating bean with name 'liquibase' defined in class path resource [org/springframework/boot/autoconfigure/liquibase/LiquibaseAutoConfiguration$LiquibaseConfiguration.class]:
Invocation of init method failed; nested exception is liquibase.exception.LockException: Could not acquire change log lock. Currently locked by zzd170000dsj30 (10.192.67.30) since 5/10/20 8:35 PM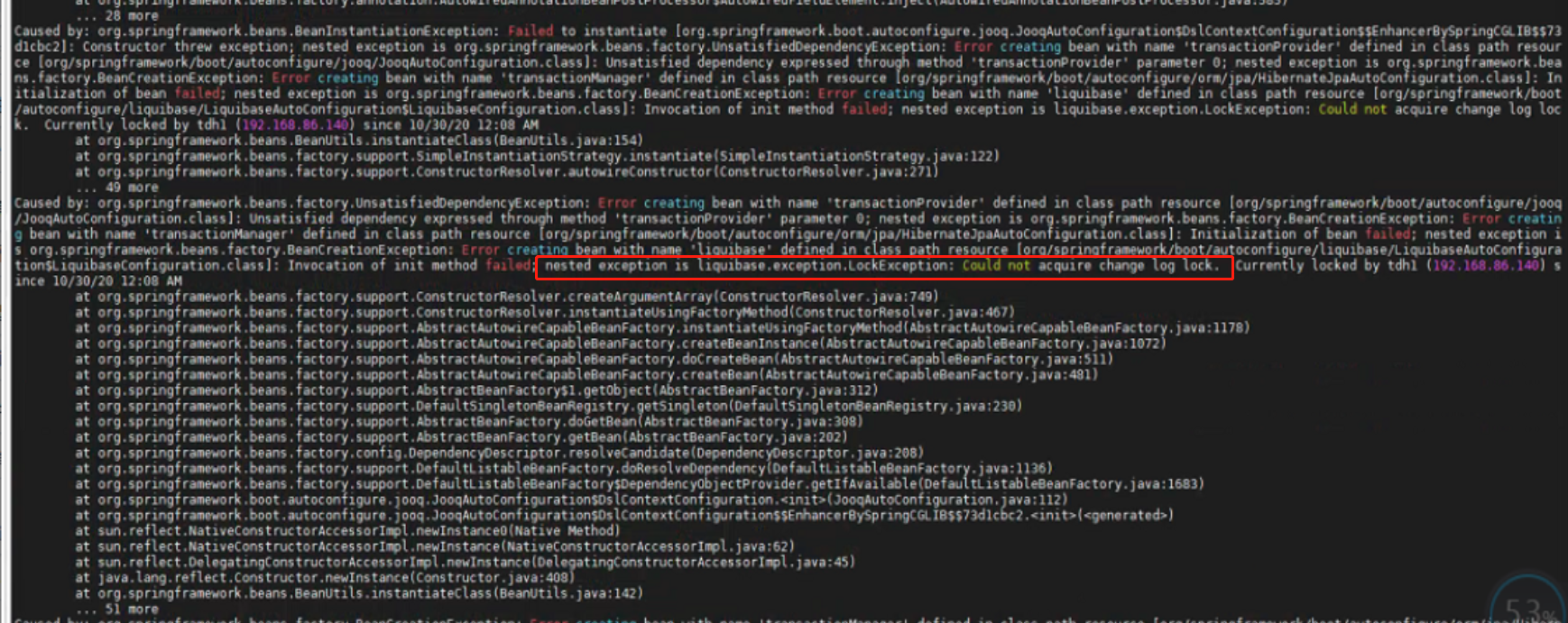
详细说明
问题原因:
pod启动时创建db table被中断, change log lock没有释放。由于每次重启都会继续创建之前没有执行完的db操作,这样就会因为log没释放而不能执行,使得每次重启都失败。但deployment的存在,使其一直重启,直到启动成功。
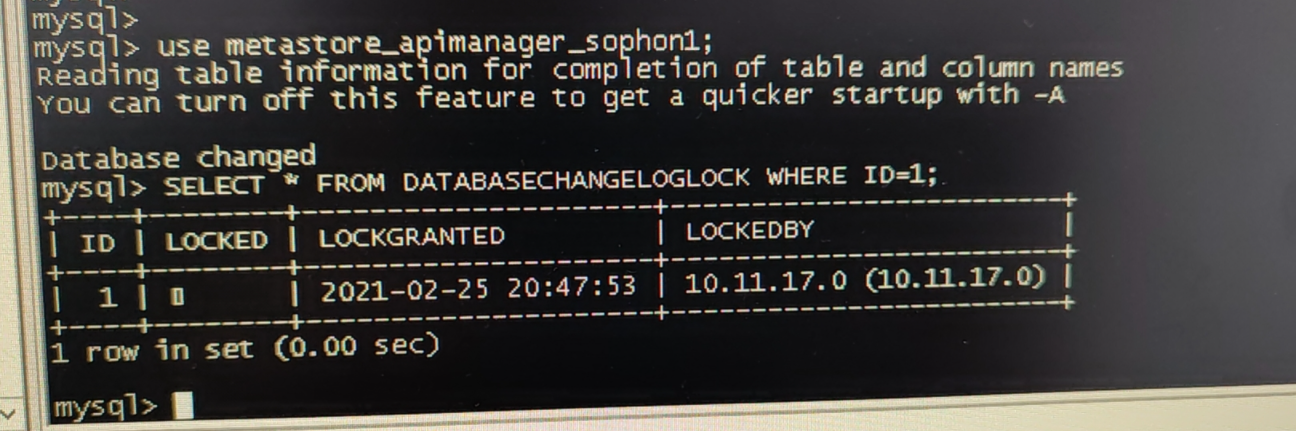
进入txsql元数据库,执行
use metastore_《异常角色》_sophonX;
SELECT * FROM DATABASECHANGELOGLOCK WHERE ID=1;时,发现LOCKED为true
解决办法
- 使用下面命令进入txsql数据库
[root@jiujiu-tdh-70 ~]# txsql_masterIp=kubectl exec -it $(kubectl get po -o wide | grep -i txsql-server-txsql | grep -i running | grep -E "1\/1" | awk '{print $1}' | head -1) -- /usr/bin/txsql/tools/txsql.sh list master | grep -iE "get.*master" | grep -Eo "([0-9]+\.){3}[0-9]+"[root@jiujiu-tdh-70 ~]# [root@jiujiu-tdh-70 ~]# kubectl exec -it $(kubectl get po -o wide | grep -i txsql-server-txsql | grep -w $txsql_masterIp | awk '{print $1}') -- /usr/bin/txsql/tools/txsql.sh shell -
进入异常角色的库,执行下面的SQL来取消锁。
UPDATE DATABASECHANGELOGLOCK SET LOCKED=FALSE, LOCKGRANTED=null, LOCKEDBY=null where ID=1;以apimanager为例,其他角色异常则进入对应的库中。
mysql> use metastore_apimanager_sophon1; Database changed mysql> UPDATE DATABASECHANGELOGLOCK SET LOCKED=FALSE, LOCKGRANTED=null, LOCKEDBY=null where ID=1;3.重启故障的角色。
页面上先停止再启动角色,或者命令执行kubectl delete po <对应角色的podname>也可以。