概要描述
我们知道传统的DBMS系统一般都具有表分区的功能,通过表分区能够在特定的区域检索数据,减少扫描成本,在一定程度上提高查询效率,当然我们还可以通过进一步在分区上建立索引进一步提升查询效率。在此就不赘述了。
在Hive数仓中也有分区分桶的概念,在逻辑上分区表与未分区表没有区别,在物理上分区表会将数据按照分区键的列值存储在表目录的子目录中,目录名=“分区键=键值”。其中需要注意的是分区键的值不一定要基于表的某一列(字段),它可以指定任意值,只要查询的时候指定相应的分区键来查询即可。我们可以对分区进行添加、删除、重命名、清空等操作。因为分区在特定的区域(子目录)下检索数据,它作用同DNMS分区一样,都是为了减少扫描成本。
分桶则是指定分桶表的某一列,让该列数据按照哈希取模的方式随机、均匀地分发到各个桶文件中。因为分桶操作需要根据某一列具体数据来进行哈希取模操作,故指定的分桶列必须基于表中的某一列(字段)。因为分桶改变了数据的存储方式,它会把哈希取模相同或者在某一区间的数据行放在同一个桶文件中。如此一来便可提高查询效率。
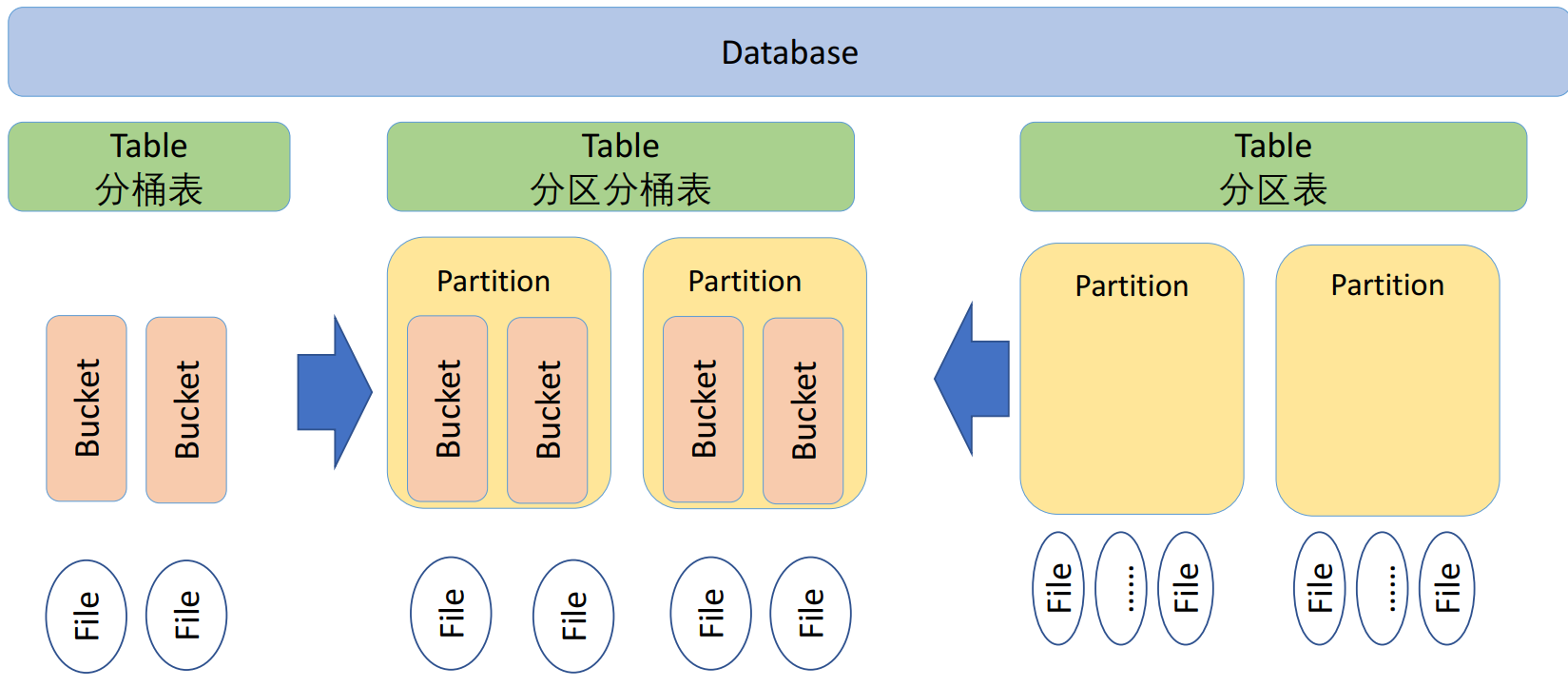
详细说明
分桶
i 含义
通过分桶键哈希取模(key hashcode %N)的方式,将表或分区中的数据随机、均匀地分发到N个桶中,桶数N一般为质数,桶编号为0, 1, …, N-1
ii 注意点
- a) 事务表必须分桶,非事务表可以不分桶;
- b) 分桶数:最好是质数,当然合数也可以,分桶数避开31的倍数;
- c) 分桶大小:分桶后的orc表,100M-200M每桶。相对于外表,orc表的压缩率为3~5,假设外表的大小为10G,导入orc表后,大小约为2G,可以分23个桶;
- d) 对于普通ORC表,单分桶大小建议在200M以内;
- e) 对于ORC事务表,标准适当降低,文件大小限制在100M以内,记录条数限制在几百万条左右;
- f) 分桶字段选择:只能用一列进行分桶,选择过滤率高的列,如果列的重复值太多,可能会导致数据倾斜。分桶字段不能是null值;
- 例如,假如需要将50个记录1,1,2,2,4,…,4按照哈希规则分给两个Bucket,那么有48个记录都会分配给标号为0的Bucket,而标号为1的Bucket的数据量仅为2,没有很好实现分散数据的目的,因此不建议采用该列为分桶字段;
- g) ORC表建完后,分桶字段和桶数不能修改,所以,对于数据量增长较快的表,分桶数的选择要结合未来几年后的数据量进行评估;
- h) 如果是分区表,分桶数是针对每个分区的。例如,如果创建分区分桶表时指定的分桶数是11,那么每个分区中的数据都会再分成11个桶;
- i) 每个分桶对应的是HDFS上的一个文件;
- j) 分桶字段类型:建议用string,不建议使用decimal类型;
- k) 如果表中没有合适的字段进行分桶,需要考虑额外增加一列。假设表中有联合主键a、b,可以使用md5(a||b);
iii 分桶的好处
- a) 条件过滤时,如果过滤字段和分桶字段一致,可根据哈希结果直接知道该记录所在的分桶编号,只在这些分桶查找满足条件的记录,而不用搜索所有的文件,有很高的查询效率。所以分桶字段可以适当提高查询速度;
- b) 方便数据抽样sampling;
- 有助于快速取样 取样是从所有数据随机抽取一部分样本。表若被分桶,每个bucket的内容是对数据离散后的结果,满足样本的要求,所以取样时可以直接抽取任意一桶的全部数据作为样本
- c) join时可以提高MR程序效率;
- 获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量
iiii 分桶过多的弊端
- a) 如果表有很多桶,则每个桶会用一个map任务来完成,而一个map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费。而且,同时可执行的map数是受最大task并发数限制的。
分区
i 含义
通过特定条件(相等或大于小于)将表的数据分发到分区目录中,或者将分区中的数据分发到子分区目录中。
ii 注意点
- a) 分区数太多会降低计算和存储的性能;
- b) 如果按时间分区,建议按月或年进行分区(否则会导致分区数过多);
- 日期或时间,比如year、month、day或者hour,当表中存在时间或者日期字段时,可以使用些字段;
- 地理位置,比如国家、省份、城市等;
- 业务逻辑,比如部门、销售区域、客户等等;
- c) 不推荐使用多级分区;
- d) 每个分区对应的是HDFS上的一个文件夹;
- e) 分区数*分桶数,不建议超过10000;
iii 分区的好处
- a) 条件过滤时, 如果过滤字段和分区字段一致,可实现PartitionPruner也就是分区裁剪,而不用搜索所有的分区文件夹,有很高的查询效率。所以分区字段可以适当提高查询速度。
iiii 分区过多的弊端
-
a) 大量分区会创建大量的非必须的hdfs文件和文件夹,一个分区就对应着包含有多个文件的文件夹。如果指定的表存在数百个分区,那么可能每天都会创建好几万个文件。如果保持这样的表很多年,那么最终就会超出Namenode对系统元数据信息的处理能力。因为Namenode必须要将所有的系统文件的元数据信息保存在内存内。虽然每个文件只需要少量字节大小的元数据(大约是150字节/文件),但是这样也会限制一个HDFS实例所能管理的文件总数的上限;
-
b) MapReduce会将一个任务(job)转换成多个任务(task)。默认情况下,每个task都是一个新的JVM实例,都需要开启和销毁的开销。对于小文件,每个文件都会对应一个task,JVM开启和销毁的时间中销毁可能会比实际处理数据的时间消耗要长!
因此,一个理想的分区方案不应该导致产生太多的分区和文件夹目录,并且每个目录下的文件应该足够得大,应该是文件系统中块大小的若干倍。
按照时间范围进行分区的一个好的策略就是按照不同的时间粒度来确定合适大小的数据积累量,而且按照这个时间粒度,随着时间的推移,分区数量的增长是“均匀的”,而且每个分区下包含的文件大小至少是文件系统中块的大小或者块大小的数倍,这个平衡可以保持使分区足够大,从而优化一般情况下查询的数据吞吐量。同事有必要考虑这种粒度级别在未来是否适用,特别是查询中where子句选择较小粒度的情况