概要描述
补数的定义:根据当前工作流的调度周期,在指定时间段内,重新调度执行一遍。
比如,工作流A的调度周期是每天早上1点钟调度。我们选择A在时间段2019/01/01~2019/12/31上进行补数,那么workflow就会立马把A调度起来365条执行记录,调度时间是2019/01/01-01:00:00,2019/01/02-01:00:00 … 2019/12/31-01:00:00。
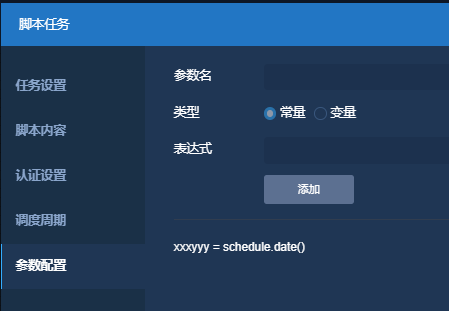
某种场景下,客户在sql语句中使用了sysdate函数,而补数过程中无法通过sysdate获取调度日期,只能够通过workflow调度时间函数schedule.date()来获取当天日期(yyyy-MM-dd格式)。
下面的内容,主要介绍,一个每天根据sysdate增量从oracle抽取数据的sql算子工作流,如何改造并支持workflow的补数功能,可供参考。
支持版本:>=studio 1.4
详细说明
Step1: 实验准备
ORACLE侧,构建样例表,插入样例数据
create table EMP
(
empno INTEGER,
ename VARCHAR2(255),
job VARCHAR2(255),
mgr INTEGER,
hiredate DATE,
sal INTEGER,
comm INTEGER,
deptno INTEGER
);insert into emp (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values ('8001', 'SMITH', 'CLERK', '7902', to_date('12-05-2021 12:07:05', 'dd-mm-yyyy hh24:mi:ss'), '800', null, '20');
insert into emp (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values ('8002', 'SMITH', 'CLERK', '7902', to_date('13-05-2021 12:07:05', 'dd-mm-yyyy hh24:mi:ss'), '800', null, '20');
insert into emp (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values ('8003', 'SMITH', 'CLERK', '7902', to_date('14-05-2021 12:07:05', 'dd-mm-yyyy hh24:mi:ss'), '800', null, '20');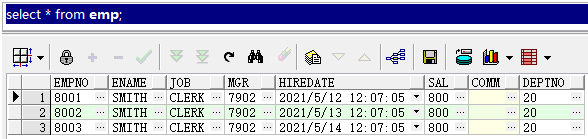
INCEPTOR侧,构建样例表
CREATE TABLE emp_sp(
empno int DEFAULT NULL,
ename string DEFAULT NULL,
job string DEFAULT NULL,
mgr int DEFAULT NULL,
hiredate date DEFAULT NULL,
sal int DEFAULT NULL,
comm int DEFAULT NULL,
deptno int DEFAULT NULL
)
CLUSTERED BY (
empno)
INTO 3 BUCKETS
STORED AS ORC_TRANSACTION;Step2:workflow工作流配置
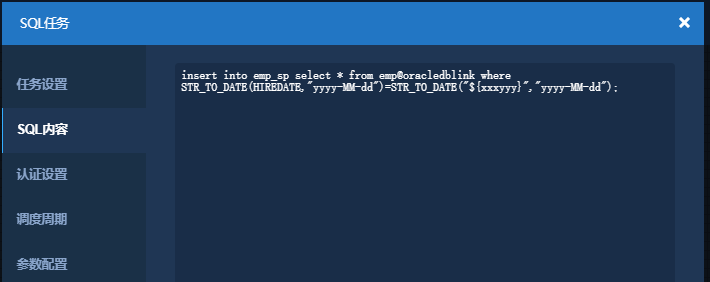
使用SQL算子

insert into emp_sp select * from emp@oracledblink where STR_TO_DATE(HIREDATE,"yyyy-MM-dd")=STR_TO_DATE("${xxxyyy}","yyyy-MM-dd");
参数配置,选择变量类型添加
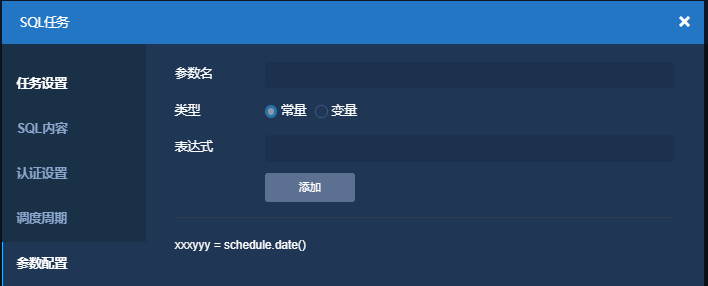
Step3: 验证3天的补数
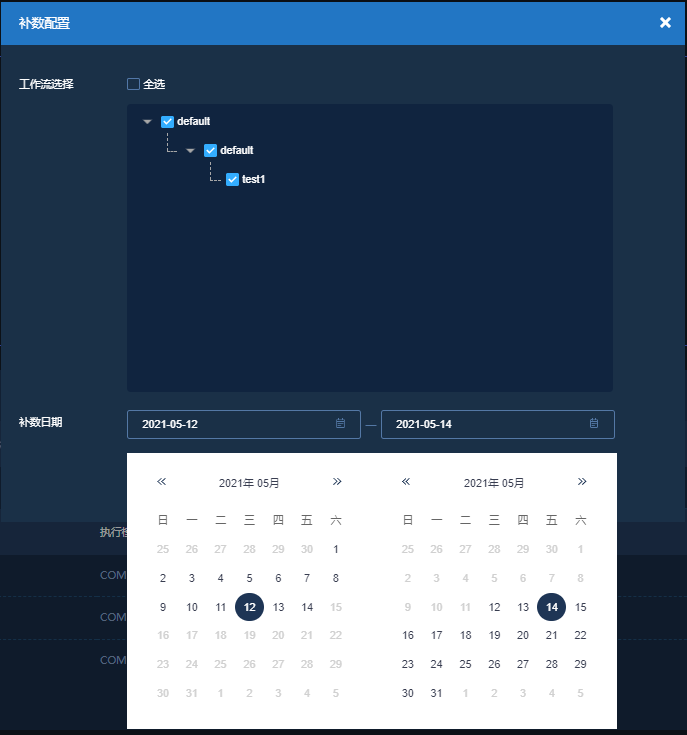
点击workflow页面右上角的补数按钮

勾选对应的工作流,选择需要补数的时间范围
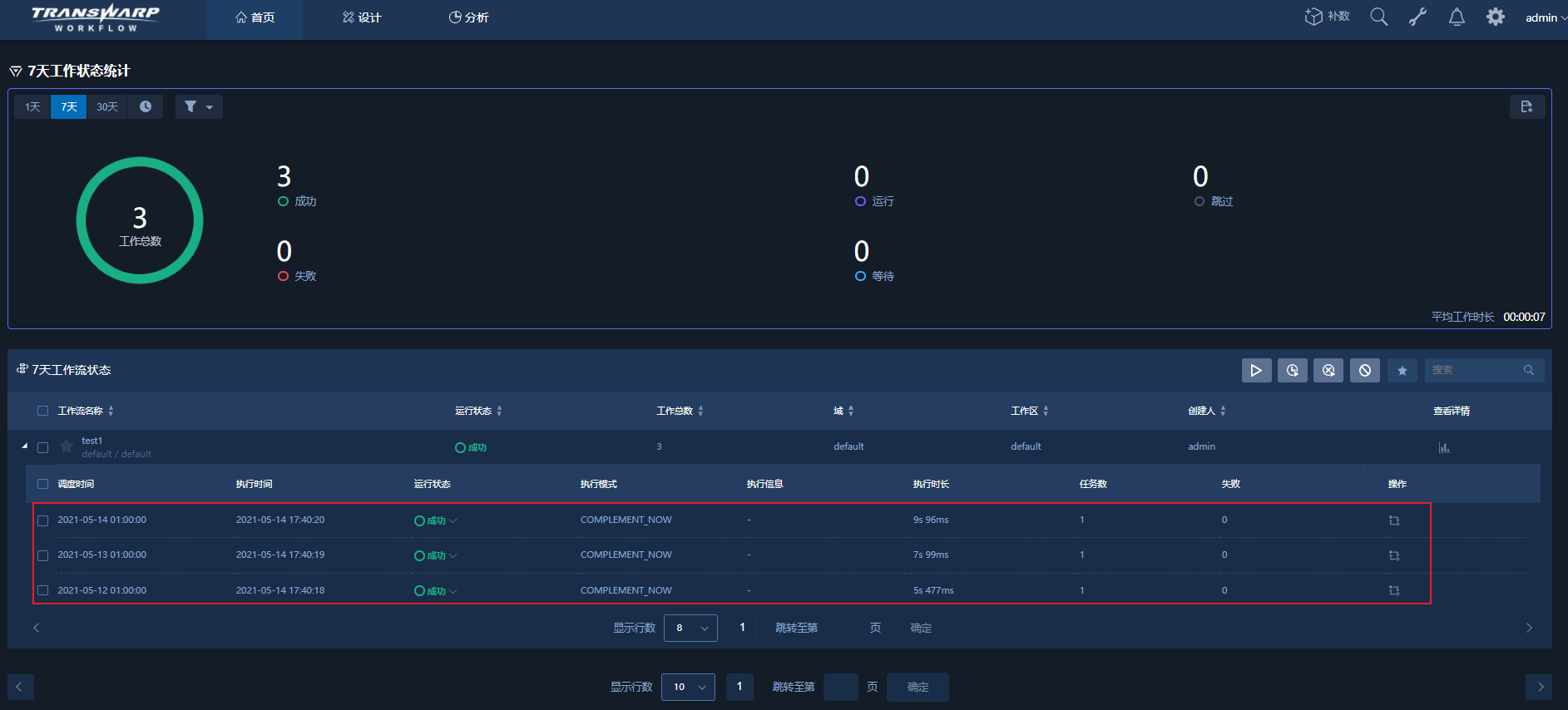
在主页面,选择时间跨度,观察补数生成的工作任务是否执行成功
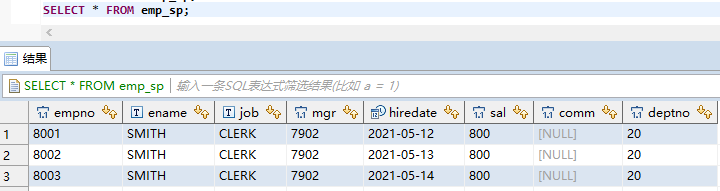
最终inceptor结果:
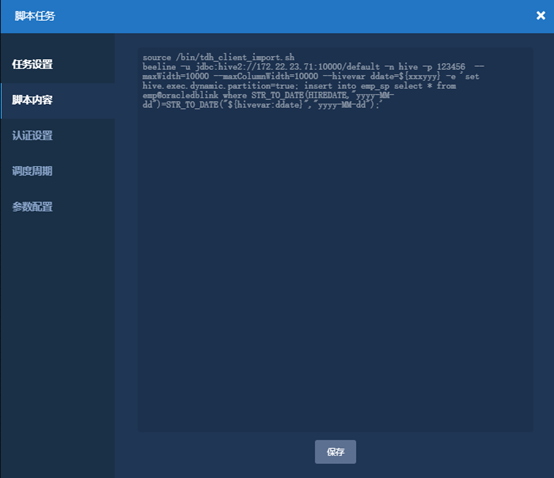
附beeline脚本算子补数方式:
使用脚本算子
source /bin/tdh_client_import.sh
beeline -u jdbc:hive2://172.22.23.71:10000/default -n hive -p 123456 --maxWidth=10000 --maxColumnWidth=10000 --hivevar ddate=${xxxyyy} -e 'set hive.exec.dynamic.partition=true; insert into emp_sp select * from emp@oracledblink where STR_TO_DATE(HIREDATE,"yyyy-MM-dd")=STR_TO_DATE("${hivevar:ddate}","yyyy-MM-dd");'