概要说明
本文介绍一种通过后台命令,退役 HDFS DataNode 角色的方法。
同时提供一种加快 Under replicated block 的方法。
详细说明
- 退役 DataNode
-
配置参数,加快补全 Under replicated block
1、退役 DataNode
节点退役操作是在 NameNode 所在节点的 /etc/hdfs1/conf/exclude-list.txt 加上需要退役的节点;
然后执行 hdfs dfsadmin -refreshNodes
查看退役进度,通过以下2种方式查看 Decommission 的状态:
hadoop dfsadmin -report正在执行Decommission,会显示:Decommission Status : Decommission in progress
执行完毕后,会显示:Decommission Status : Decommissioned
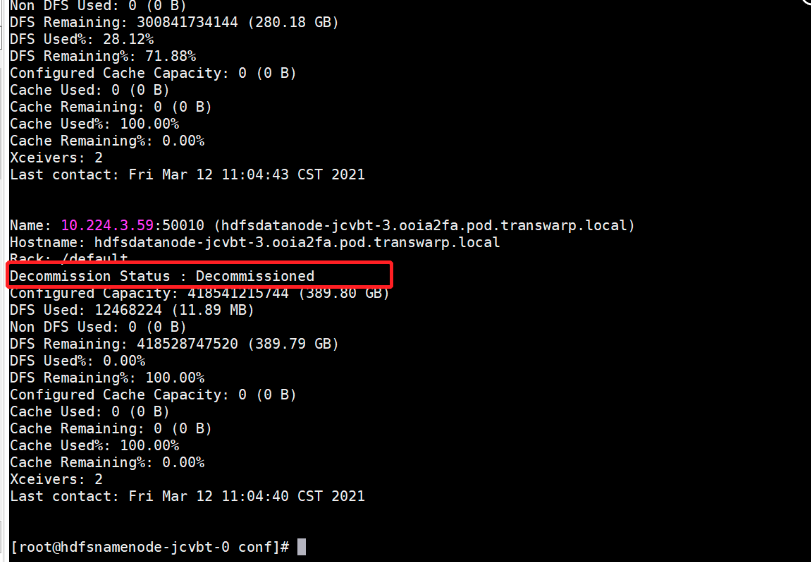
当节点状态变为 decommissioned 状态,表明数据转移工作已经完成。
然后在 manager 节点停止这个 DataNode;
最后执行 hdfs dfsadmin -refreshNodes 刷新节点信息;
此时 50070 webui 看不到该节点,即为退役成功。
2、加快副本的补充
如果 DataNode 数据量已经比较大了,此时退役处于 decommisstion in progress 状态的时间会比较久,可以再退役开始之前,设置以下参数,来加快副本的补充。
界面添加自定义参数,然后配置服务,重启 NameNode;
如果无法整体重启 NameNode,可以采用滚动重启的方式(先重启 standby的,然后切主,再重启另一个 NameNode);
dfs.namenode.replication.max-streams
dfs.namenode.replication.work.multiplier.per.iteration
dfs.namenode.replication.max-streams-hard-limit

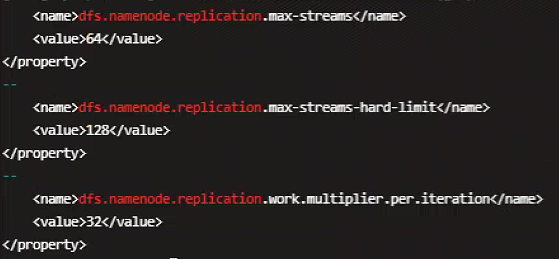
设置为以上参数之后,Under replicated block 补全效率可以提升 30 倍左右。
性能参考:
SSD 磁盘的,500万 Blocks,需要24小时。
HDD 磁盘,500万Blocks,需要144小时。