内容纲要
概要描述
本文介绍如何使用 python 实现 inceptor udf 函数,仅供参考。
详细说明
1. 编写python脚本
功能是实现使用空格做字符串拆分
#!/usr/bin/python
import sys
for line in sys.stdin:
line = line.strip()
fname , lname = line.split(' ')
l_name = lname.lower()
print '\t'.join([fname, str(l_name)])2. 将.py文件上传到容器的/usr/lib/inceptor/lib目录,做镜像持久化
3. 构建测试表及测试数据
CREATE TABLE test01(id varchar2(255) ) CLUSTERED by(id) INTO 1 BUCKETS STORED AS ORC_TRANSACTION;
INSERT INTO test01 VALUES('liu kaiwen');
INSERT INTO test01 VALUES('zhang sanfeng');4. 执行transform语句
SELECT transform(id) USING 'python /usr/lib/inceptor/lib/split.py' AS thing1, thing2 FROM test01;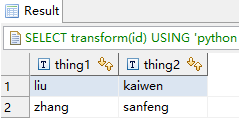
FAQ:开启kerberos情况下报错问题
开启kerberos情况下会报如下错误:
SQL 错误 [12] [08S01]: FAILED: Hive Internal Error: org.apache.hadoop.hive.ql.security.authorization.plugin.HiveAccessControlException(Query with transform clause is disallowed in current configuration. )
该问题,是因为transform是hive的一个安全漏洞,参考: https://issues.apache.org/jira/browse/RANGER-738
The TRANSFORM statement in Hive is a big security hole with Hive run without impersonation, so when SQL Standard Authorization is enabled, the feature id completely disabled which is a bit of a sledgehammer approach to securing this statement.
argodb 6.0 及以上版本,可以通过参数 set quark.python.transform.enabled=true 解决。