内容纲要
概要描述
当服务出现某些特殊问题时,需要保留当时的环境,来排查问题的根本原因;
可以先收集一些当时的奔溃信息,然后再重启服务,及时解决实际问题;
详细说明
按照信息来源和保留方式,可以将服务相关的信息分为三种:
- 日志信息:服务重启后,日志信息依然保留;
- 运行时状态或者指标信息:服务重启后,故障时的运行信息或者指标会变化
- jvm 信息:服务重启后,jvm 信息会重新初始化,所以需要及时保留奔溃时刻的 jvm 信息
1、日志信息的收集
TDH 集群中,日志信息一般保留在 /var/log/ 下,不同组件有自己不同的路径;
比如 Inceptor 的,在 /var/log/Inceptor1/ 下,一般收集 hive-server2.log、hive-metastore.log、hive-server2.audit;
可以先 cp 到其他路径作为备份,避免被滚动覆盖。
[root@tdh6-161/var/log/inceptor1]# ls -lt
总用量 2045796
-rw-r--r-- 1 1005 1006 5266159 6月 30 15:35 inceptor-executor.log
-rw-r--r-- 1 1005 1006 37599988 6月 30 15:35 hive-metastore.log
-rw-r--r-- 1 1005 1006 16261820 6月 30 15:35 hive-server2.log
-rw-r--r--. 1 1005 1006 4904608 6月 30 15:30 hive-server2.audit
-rw-r--r--. 1 1005 1006 1152 6月 30 13:40 inceptor-executor.gc.log比如 HDFS 的日志信息,在 /var/log/hdfs1/ 下;
[root@tdh6-161/var/log/hdfs1]# ls -lt
总用量 1334956
-rwxr-xr-x 1 1001 1002 46043926 6月 30 15:36 hadoop-hdfs-namenode-tdh6-161.log
-rwxr-xr-x 1 1001 1002 7785293 6月 30 15:36 hadoop-hdfs-journalnode-tdh6-161.log
-rwxr-xr-x 1 1001 1002 3823783 6月 30 15:36 SecurityAuth-hdfs.audit
-rwxr-xr-x 1 1001 1002 59254429 6月 30 15:31 hadoop-hdfs-datanode-tdh6-161.log
-rwxr-xr-x. 1 1001 1002 65772346 6月 30 14:54 hadoop-hdfs-zkfc-tdh6-161.log2、运行时状态信息
服务端口连接数
netstat -antp |grep 10000
netstat -antp |grep 9083
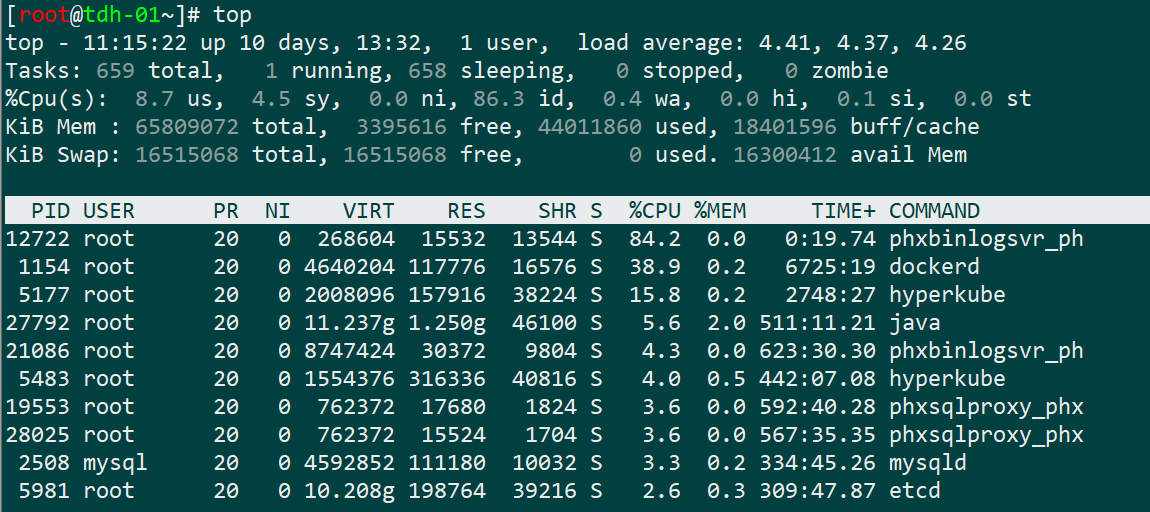
netstat -antp |grep 2181服务器的 top 信息
截图即可,如下图所示:
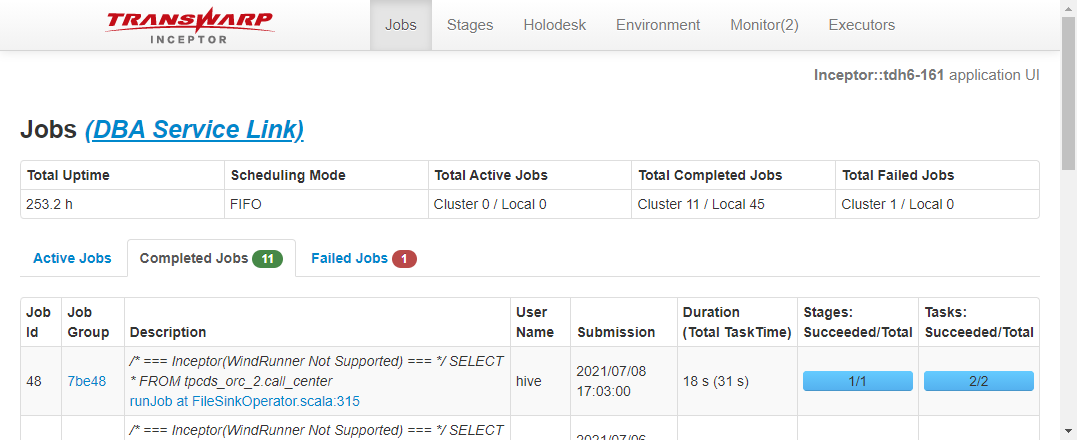
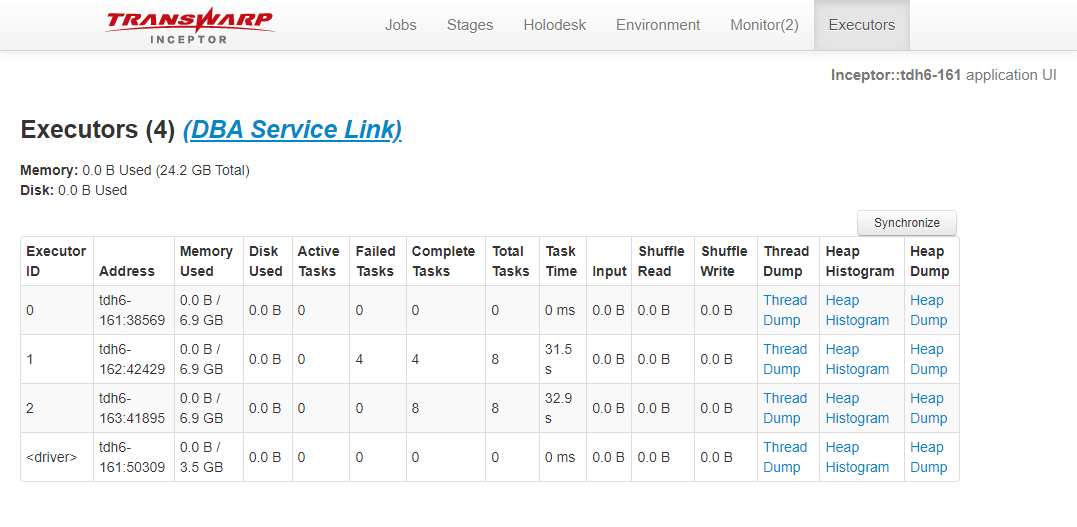
4040 信息,如果已经升级至 dbaservice ,可以跳过
job 标签页,以及 executor 标签页,如下图所示:
jmx 信息(仅限hdfs、yarn、hyperbase)
开启jmx 的可以提供,如下图所示:

ganglia 信息或者 aquila 信息
开启 ganglia 或者 aquila 的可以提供
3、jvm 信息(并非所有组件都有)
jvm 信息一般只有在 GC 或者任务卡住时才会收集;
参见连接: jmap、jstack、jstat、jinfo 等 jvm 信息收集方式
同时提供了一个收集 jvm 信息的脚本;具体可以参见这个链接:TDH以及TDC收集 Inceptor jvm 的脚本