概要描述
inceptor中,经常遇到需要将inceptor表卸数到hdfs,供下游应用读数的情况。而null在inceptor中默认是\N的形式存在的,直接通过insert overwrite directory的方式卸数到hdfs,null会变成\N。本文主要针对该问题提供解决方案,仅供参考。
先说结论:
方案1: NULL DEFINED AS '' 方式 =>推荐
方案2: INSERT OVERWRITE DIRECTORY + WITH SERDEPROPERTIES方式
方案3: INSERT OVERWRITE DIRECTORY + SED替换方式
方案4: CTAS 中间表过渡方式
拓展1:如何导出多字段分隔符的数据文件
问题现象
构建原始数据
DROP TABLE IF EXISTS org_torc;
CREATE TABLE org_torc (id int,name STRING,age int) CLUSTERED BY (id) INTO 3 BUCKETS STORED AS ORC_TRANSACTION;
INSERT INTO org_torc VALUES (1,'zhangsan',15);
INSERT INTO org_torc VALUES (2,null,16);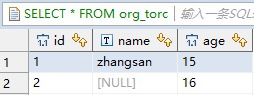
卸数到hdfs:
INSERT OVERWRITE DIRECTORY '/tmp/staging_text'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
SELECT id,name,age FROM org_torc;
可以看到,源数据中为NULL的数据,在hdfs中变成了\N。
解决方案
方案1.(推荐) NULL DEFINED AS ”方式
–该方案仅适用于单字段分隔符
INSERT OVERWRITE DIRECTORY '/tmp/staging_text'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
NULL DEFINED AS ''
SELECT id,name,age FROM org_torc;
方案2. INSERT OVERWRITE DIRECTORY + WITH SERDEPROPERTIES方式
–该方案适用于多字段分隔符
--不在SERDEPROPERTIES中指定分隔符,而是通过多字段拼接的方式(亦或者concat)
insert overwrite directory '/tmp/targetDir'
select id||'|'||name||'|'||age FROM org_torc;
方案3. INSERT OVERWRITE DIRECTORY + SED替换方式
获取insert overwrite directory的结果数据,通过sed命令把\N替换成空的方式。
sed 's/\\N//g' orgFile > targetFilei.e.
当然也可以使用nvl函数将null替换成其他字符,再sed替换成空的方式,比如:
INSERT OVERWRITE DIRECTORY '/tmp/staging_text'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
SELECT
nvl(id,'ThisFiledIsNull'),
nvl(name,'ThisFiledIsNull'),
nvl(age,'ThisFiledIsNull')
FROM org_torc;
sed 's/ThisFiledIsNull//g' orgFile > targetFile方案4. CTAS TEXTFILE内表过渡方式
DROP TABLE IF EXISTS staging_text;
CREATE TABLE staging_text
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES
('field.delim' = '|', 'serialization.null.format' = '')
STORED AS TEXTFILE
LOCATION '/tmp/staging_text'
AS SELECT * FROM org_torc;
后面再每次做同样的卸数操作时,需要先DROP掉该内表,再执行操作。
i.e.
同样的,您也可以通过textfile外表的方式,多了一个insert的步骤:
--external外表不支持CTAS,且必须声明列名
DROP TABLE IF EXISTS staging_external_text;
CREATE EXTERNAL TABLE staging_external_text (id INT,name STRING,age INT )
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES
('field.delim' = '|', 'serialization.null.format' = '')
STORED AS TEXTFILE
LOCATION '/tmp/staging_external_text';INSERT OVERWRITE TABLE staging_external_text SELECT * FROM org_torc;
拓展1:如何导出多字段分隔符的数据文件
可以通过多字段分隔符表的方式实现(这里可以在SERDEPROPERTIES中,自定义编码格式、null的format、任意多字段分隔符):
DROP TABLE IF EXISTS emp_external_text;
CREATE EXTERNAL TABLE emp_external_text (
empno int DEFAULT NULL,
ename string DEFAULT NULL,
job string DEFAULT NULL,
mgr int DEFAULT NULL,
hiredate date DEFAULT NULL,
sal int DEFAULT NULL,
comm int DEFAULT NULL,
deptno int DEFAULT NULL
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.MultiDelimitSerDe'
WITH SERDEPROPERTIES
('input.delimited'='@_@',
'serialization.encoding'='GBK',
'serialization.null.format' = '')
STORED AS TEXTFILE
LOCATION '/tmp/emp_external_text';创建好中间文本表之后,我们把源表的数据写入这个中间表中。 如果下游对数据文件的个数有要求,可以设置reduce数目 + distribute by 的方式写出固定个数的数据文件。
set mapred.reduce.tasks=10;
INSERT OVERWRITE TABLE emp_external_text SELECT * FROM emp_holo distribute by empno;执行完导出语句之后,在中间文本表的hdfs目录下就会生成10个数据文件,通过hdfs get到本地即可。
hadoop fs -get /tmp/emp_external_text/* ./