概要描述
客户反馈,inceptor中用update语句更新的行数,比在oracle中更新的行数要少。
语法结构为:UPDATE table_name SET col1 = (SELECT select_statement WHERE join_statement and filter_statement1) WHERE filter_statement2,与oracle的行为不一致。
参见 JIRA: WARP-29387, WARP-30041
详细说明
1、oracle数据库的sql结果
/* ORACLE */
DROP TABLE t_tmp_test1;
DROP TABLE t_tmp_test2;
create table t_tmp_test1(id int,cur_bal decimal(24,6),mask varchar2(100));
create table t_tmp_test2(id int,mask varchar2(100));
insert into t_tmp_test1 values(1,100,'333');
insert into t_tmp_test1 values(2,200,'444');
insert into t_tmp_test1 values(3,300,'555');
insert into t_tmp_test1 values(4,400,'666');
insert into t_tmp_test1 values(5,500,'777');
insert into t_tmp_test2 values(1,'100');
insert into t_tmp_test2 values(2,'200');
insert into t_tmp_test2 values(3,'300');
insert into t_tmp_test2 values(7,'700');
update t_tmp_test1 a
set a.mask=(select mask from t_tmp_test2 b where a.id=b.id)
where 1=1;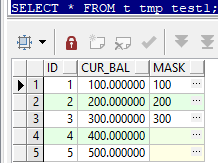
从结果可以看到,Oracle中,因为sql语句的最后面的filter_statement2为true(1=1),所以a表中的所有的行都会更新,没有匹配上的数据字段也会被更新为空。
注意:where 1=1 不写的话,语义也是一致的,全表更新。
2、inceptor数据库的sql结果
/* INCEPTOR */
DROP TABLE IF EXISTS t_tmp_test1;
DROP TABLE IF EXISTS t_tmp_test2;
create table t_tmp_test1(id int,cur_bal decimal(24,6),mask varchar2(100)) clustered by (id) into 3 buckets stored as orc_transaction;
create table t_tmp_test2(id int,mask varchar2(100)) stored as orc;
insert into t_tmp_test1 select 1,100,'333' from system.dual;
insert into t_tmp_test1 select 2,200,'444' from system.dual;
insert into t_tmp_test1 select 3,300,'555' from system.dual;
insert into t_tmp_test1 select 4,400,'666' from system.dual;
insert into t_tmp_test1 select 5,500,'777' from system.dual;
insert into t_tmp_test2 select 1,'100' from system.dual;
insert into t_tmp_test2 select 2,'200' from system.dual;
insert into t_tmp_test2 select 3,'300' from system.dual;
insert into t_tmp_test2 select 7,'700' from system.dual;
update t_tmp_test1 a
set a.mask=(select mask from t_tmp_test2 b where a.id=b.id)
where 1=1;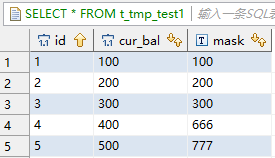
从结果可以看到,inceptor中,只更新目标表中未被filter_statement1 和 filter_statement2 过滤的且在原表有相应的行可以join上的那些行,所以没有匹配上的数据字段保持不变。
解决方案
为了兼容之前的逻辑,增设了一个开关hive.update.subquery.left.join.enabled,默认为false。
- 若不打开此开关,走以前旧的逻辑不受影响。
- 若打开此开关,则走新的逻辑,且
updateSuQ类型的sql在tableScan的时候不会加上过滤 null key 的 filter_statement。(即使INCEPTOR_DISCARD_NULL_BEFORE_MERGE此开关为true也不会过滤)
--设置参数为true,再去执行update语句,结果和oracle一致。
set hive.update.subquery.left.join.enabled = true;
update t_tmp_test1 a
set a.mask=(select mask from t_tmp_test2 b where a.id=b.id)
where 1=1;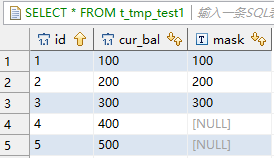
FAQ
1、oracle的这种update语法书写时要尤其注意
如果update set后面没有加任何的 filter_statement2 条件或者加上where 1=1,默认会将全表进行更新。所以要和客户确认清楚是否真的需要这样去做。
一般来说,如果想在oracle中实现只修改符合子查询匹配规则的数据,需要在set语句后面再加上where exists,参考语法如下:
/* ORACLE */
update t_tmp_test1 a
set a.mask=(select mask from t_tmp_test2 b where a.id=b.id)
--额外添加下面这行
where exists (select 1 from t_tmp_test2 b where a.id=b.id);where exists 中写法相对固定,select 1 后面直接复制set语句里面的from ... 部分,就能达到只修改符合匹配规则的数据的目的。
最终结果:
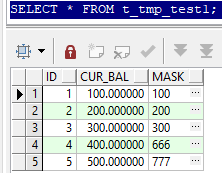
2、附上mysql端关于update join的差异测试:
DROP TABLE t_tmp_test1;
DROP TABLE t_tmp_test2;
create table t_tmp_test1(id integer,cur_bal varchar(20),mask varchar(20));
create table t_tmp_test2(id integer,mask varchar(20));
insert into t_tmp_test1 values(1,100,'333');
insert into t_tmp_test1 values(2,200,'444');
insert into t_tmp_test1 values(3,300,'555');
insert into t_tmp_test1 values(4,400,'666');
insert into t_tmp_test1 values(5,500,'777');
insert into t_tmp_test2 values(1,'100');
insert into t_tmp_test2 values(2,'200');
insert into t_tmp_test2 values(3,'300');
insert into t_tmp_test2 values(7,'700');mysql update的语法略有差异,注意执行的结果
update t_tmp_test1 t1 inner join t_tmp_test2 t2 on t1.id=t2.id set t1.mask=t2.mask;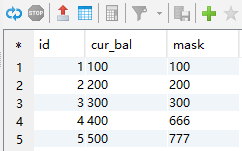
如果用下面的语法,同样会有和oracle一样的问题
update t_tmp_test1 a
set a.mask=(select mask from t_tmp_test2 b where a.id=b.id)
where 1=1;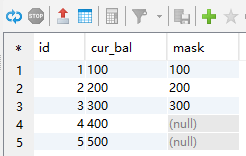
再修改成下面这样的着实没太大必要,建议用前面的 update ... join ... on ... set ...的语法
update t_tmp_test1 a
set a.mask=(select mask from t_tmp_test2 b where a.id=b.id)
where exists (select 1 from t_tmp_test2 b where a.id=b.id);