内容纲要
概要描述
TDH大数据平台集群内偶尔会出现服务器异常(某个节点因硬件故障或其他原因导致该节点系统异常、无法正常访问等)导致服务器不可用,进而导致服务角色不可用,并且该节点影响到了整个集群的正常运行,此时需要把该节点从集群中剔除,以恢复整个集群的正常运行,如resource manager角色,可以按照以下步骤进行处理。
详细说明
manager 页面展示的数据一般是来自数据库的(4.x 的数据来源是json文件),将resource manager角色从异常服务器迁移到正常服务器,大致的步骤分为以下:
- 备份数据
- 迁移角色到正常服务器,删除异常服务器上的角色
- 后台yum安装resource manager以及从正常resource manager角色获取启动文件
- 重新配置服务,重启yarn组件,并进行resource manager相互切换验证
- 重启依赖于yarn的组件,如inceptor、stream组件,hyperbase组件可以不重启
操作步骤
为方便表述,假设一下情景:
现在有node1,node2,node3,node4四个节点,yarn1组件部署在这4个节点上,原来ResourceManager安装在node1上,由于种种原因node1节点起不来了,现在需要将ResourceManager迁移到node2上。
1. 备份数据
- ssh登陆管理节点(TranswarpManager节点,登陆TDH大数据平台ip所在节点),进入
/var/lib/transwarp-manager/master/data/data目录,备份文件 -
备份相关文件
- TDH 4.x 的manager 数据是由json 文件管理的,所以只需要备份json 文件即可;涉及到的文件以及路径主要有以下4个 :
/var/lib/transwarp-manager/master/data/data/Node.json
/var/lib/transwarp-manager/master/data/data/Role.json
/var/lib/transwarp-manager/master/data/data/ServiceConfigNodeEntry.json
/var/lib/transwarp-manager/master/data/data/Service.json- 建议直接备份data文件夹下面的所有文件
2. 迁移角色到正常服务器,删除异常服务器上的角色
- 使用迁移功能,选择正常目的节点 node2,迁移角色到正常服务器 node2,根据提示操作

- 如图所示,不勾选立刻重启受到影响的服务,点击完成
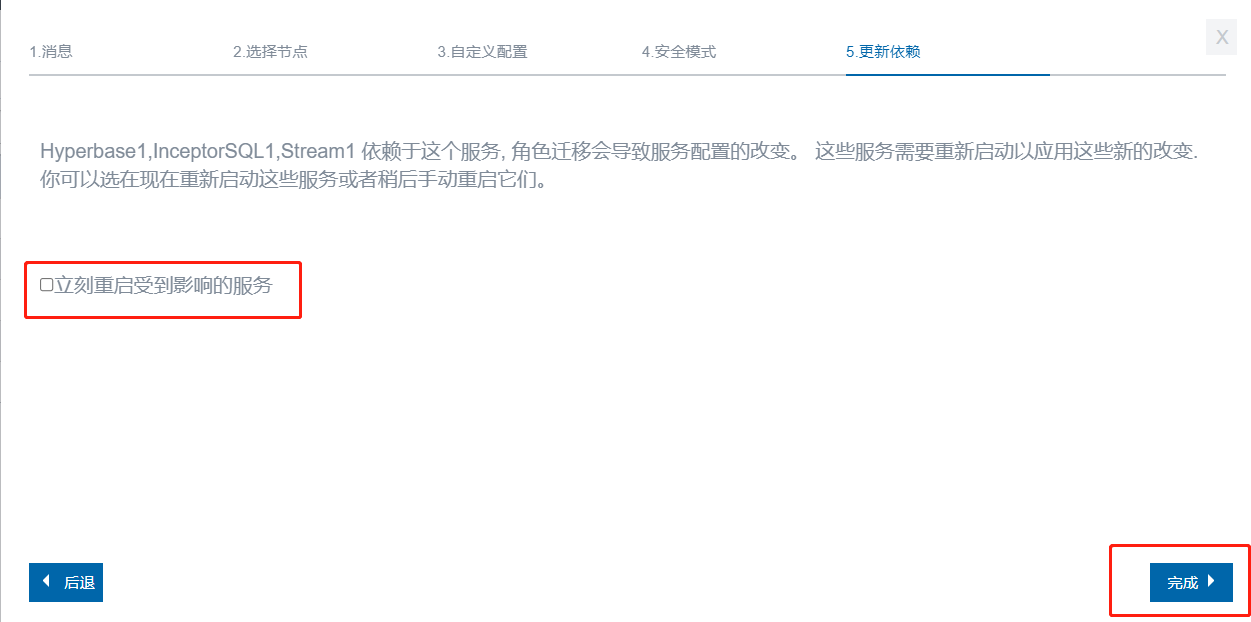
-
完成后会有未知服务器异常的错误,忽略即可,完成后resource manager角色已经在目的节点 node2显示出来了
-
删除异常的 node1 节点 resource manager角色
- 以上步骤完成后manager节点
/var/lib/transwarp-manager/master/data/data里面相关元数据已经更改
- 以上步骤完成后manager节点
3. 后台yum安装resource manager以及从正常resource manager角色获取启动文件
- 在迁移后正常节点 node2 yum安装 resource manager
yum install hadoop-yarn-resourcemanager - 从所属组件yarn1另一个正常resource manager通过scp等方式获取启动文件
/etc/init.d/hadoop-yarn-resourcemanager-yarn1
4. 重新配置服务,重启yarn1组件,并进行resource manager相互切换验证
- 重新配置服务,并整体重启yarn组件
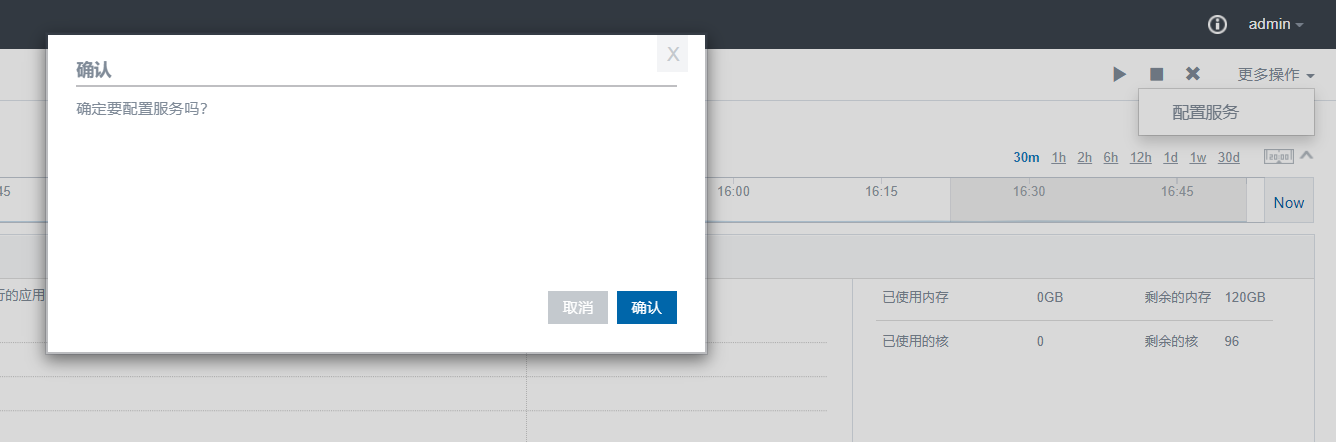
- 如果重启不正常,可以尝试进入服务器后台停止一个resource manager进程,开始几次重启yarn组件会出现两个 resource manager都standby情况,多重启几次
- 进行resource manager相互切换验证
- 手动停止 active resource manager,使状态发生切换,并多次进行手动停止 active resource manager,验证resource manager相互切换正常