内容纲要
概要描述
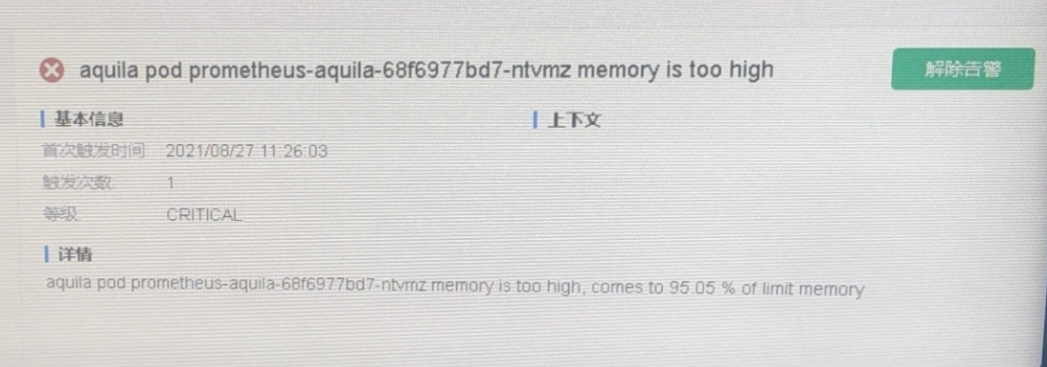
在安装了 Aquila 的集群中,可能会经常遇到 aquila pod ${pod name} memory is too high, comes to {value} % of limit memory 的告警,本文针对该告警提出几种解决方式。
详细说明
-
修改告警指标
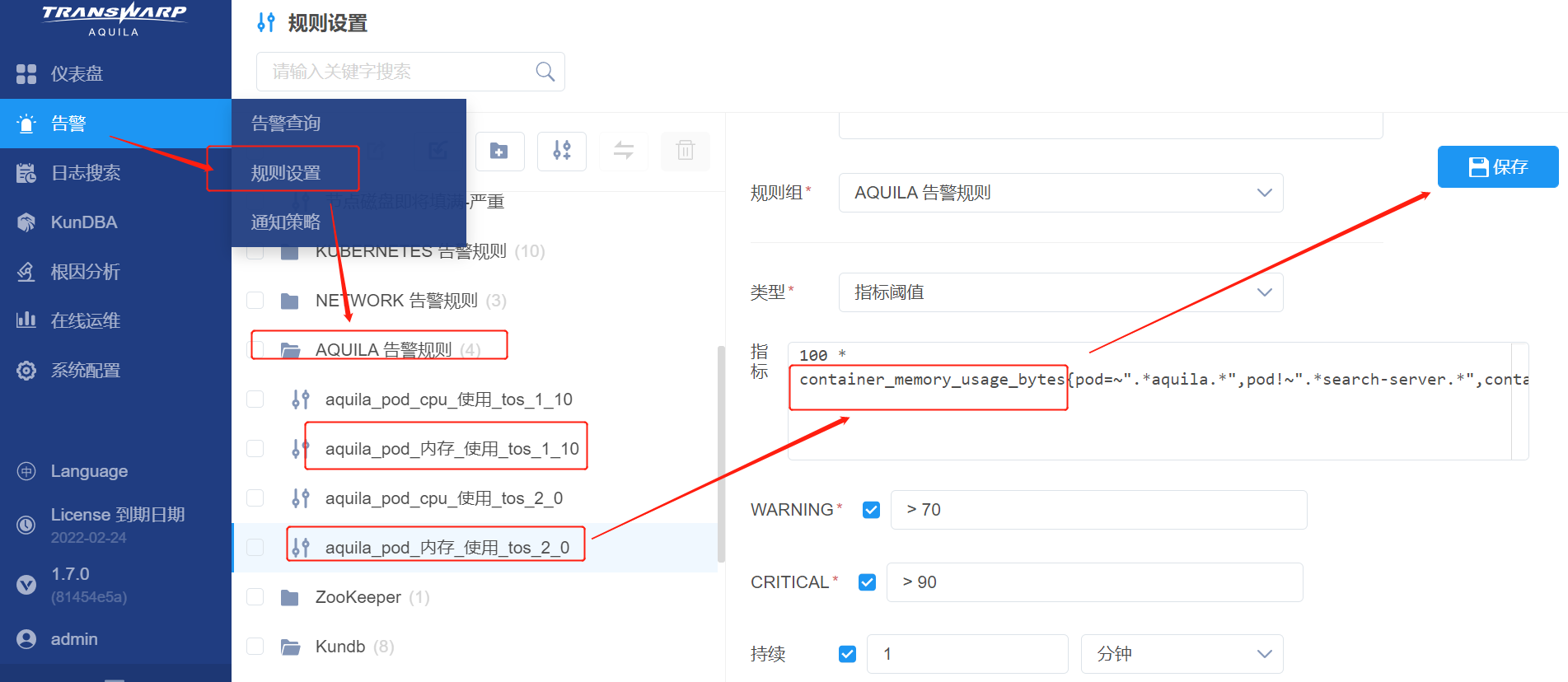
目前 Aquila 用的container_memory_usage_bytes这个指标还包含了 cache 使用量,会有虚高的现象。可以将相关服务的内存告警指标修改为container_memory_working_set_bytes,然后查看告警是否还有。
比如本例中是 Prometheus 的 pod 告警,那么就修改 AQUILA 告警规则 里的 aquila_pod_内存_使用里的指标。
-
增大 Prometheus 采集抓取间隔
Manager 页面搜索 Aquila 的参数配置关键字 ‘scrape_interval’,调大相应的值,比如 15–>30, 30 –>45
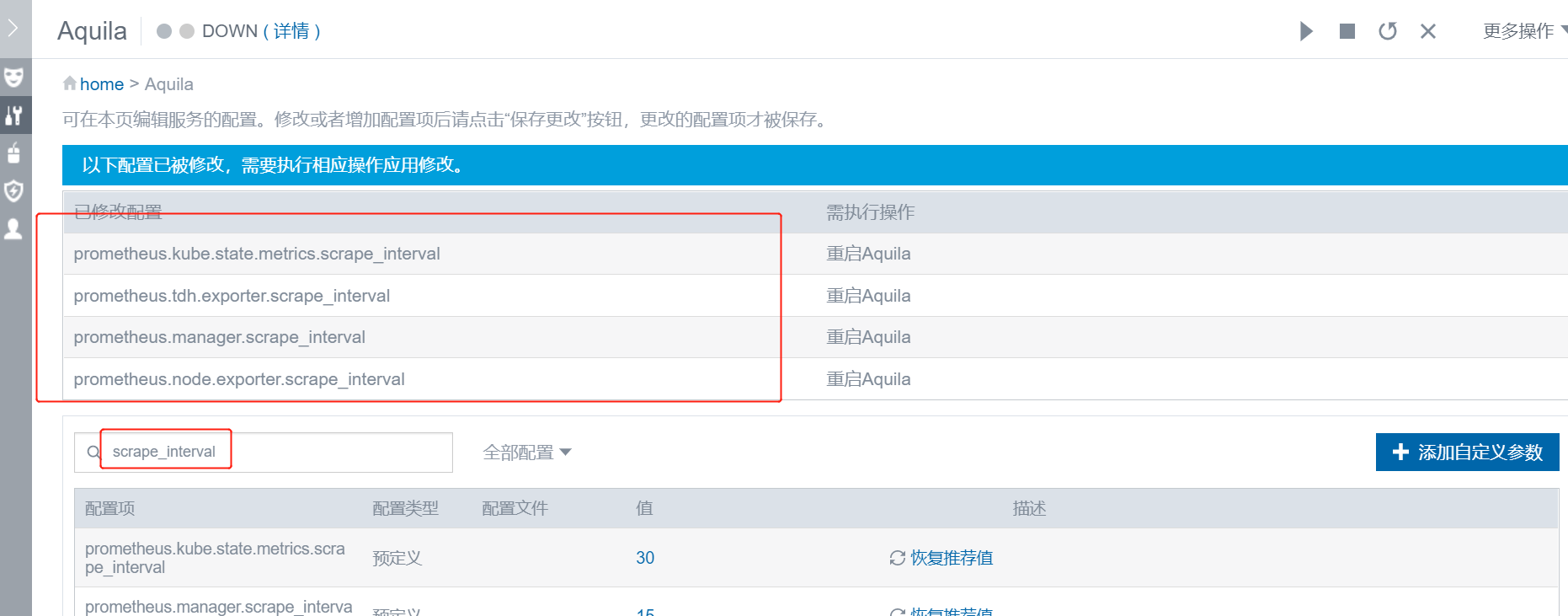
然后页面右上角配置服务,重启 Prometheus 角色。 -
增大相关组件角色的 container.limits.memory 限制
比如本例中是 Prometheus 的 pod 告警,那就调大 prometheus.container.limits.memory.
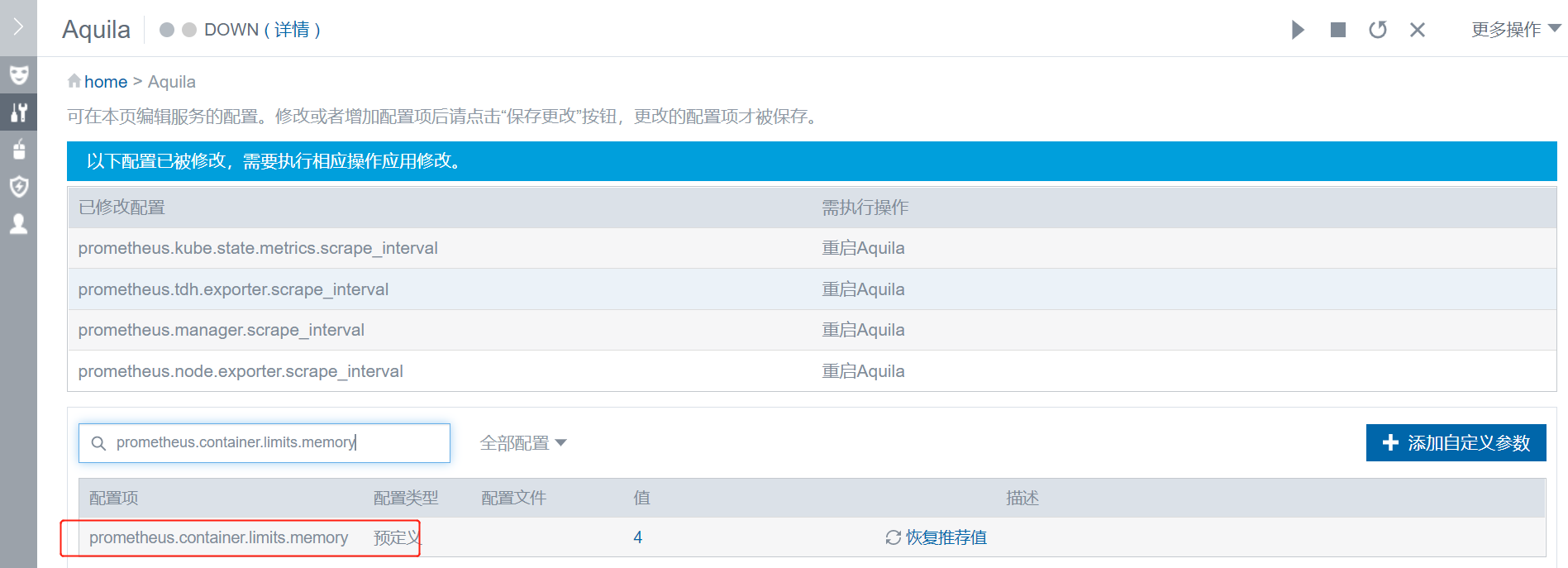
然后页面右上角配置服务,重启对应的角色。