概要描述
在TDT批量数据流中,有3种同步方式可选,包括通过日志,通过时间戳和标识列,通过新增与更新时间戳。本文主要介绍通过新增与更新时间戳在包含逻辑删除的场景下是如何实现同步的,希望能够方便大家理解并熟悉该功能点。
功能适用场景:
- 适合表中有记录插入时间和更新时间的列,且源表数据没有物理删除的情况
- 如果需要同步存在物理删除的数据,需要的条件:源表中有记录插入时间和更新时间的列,并且存在一张删除记录表,记录被删除的数据(必需有被删除数据的主键)
- 目前只支持单一主键源表
举例说明:
数据表table_data,有插入时间列create_time和更新时间列update_time,且没有物理删除,只有逻辑删除(is_delete标识是否删除),符合条件
| id | username | create_time | update_time | is_delete |
|---|---|---|---|---|
| 1 | a | 2020-09-23 12:25:24 | 2020-09-23 12:30:24 | 0 |
| 2 | b | 2020-09-23 12:26:24 | 2020-09-23 12:35:24 | 1 |
大致的测试步骤如下:
- 新增测试数据
INSERT INTO test_time(username,create_time,is_delete)VALUES('zhangsan',NOW(),0); INSERT INTO test_time(username,create_time)VALUES('lisi',NOW()); INSERT INTO test_time(username,create_time)VALUES('wangwu',NOW()); - update一条数据
UPDATE test_time set username='new_lisi' where id=2; - 逻辑删除的方式,标记一条数据为删除状态
update test_time set is_delete=1 where id=3;
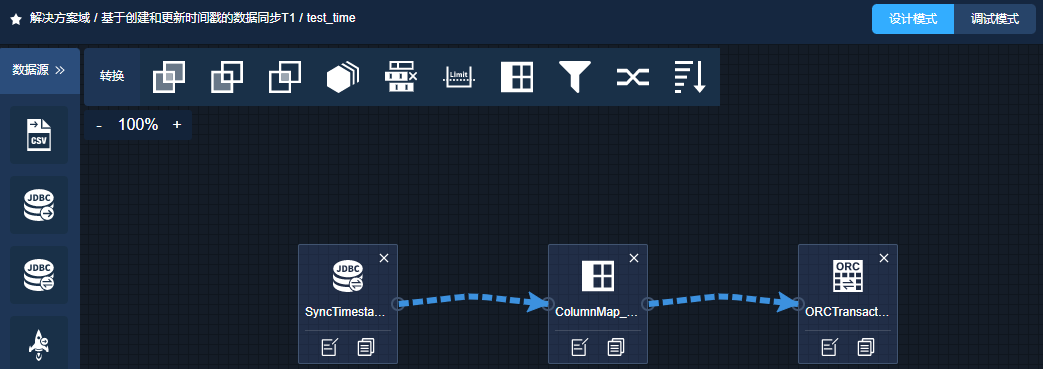
生成的数据流结构如下:
SyncTimestamp_Reader –> ColumnMap_Transformer –> ORCTransactionSync_Writer
示例
step1:源端创建测试表
--mysql
DROP TABLE test_time;
CREATE TABLE test_time (
id int(11) NOT NULL AUTO_INCREMENT,
username varchar(20) DEFAULT NULL,
create_time datetime DEFAULT NULL,
update_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
is_delete int(10) DEFAULT 0,
PRIMARY KEY (id)
) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;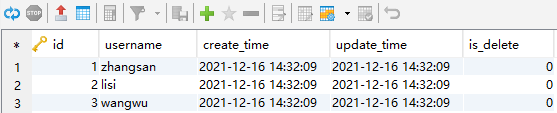
step2:创建TDT批量同步数据流
源端选择:
新建批量数据流,选择同步
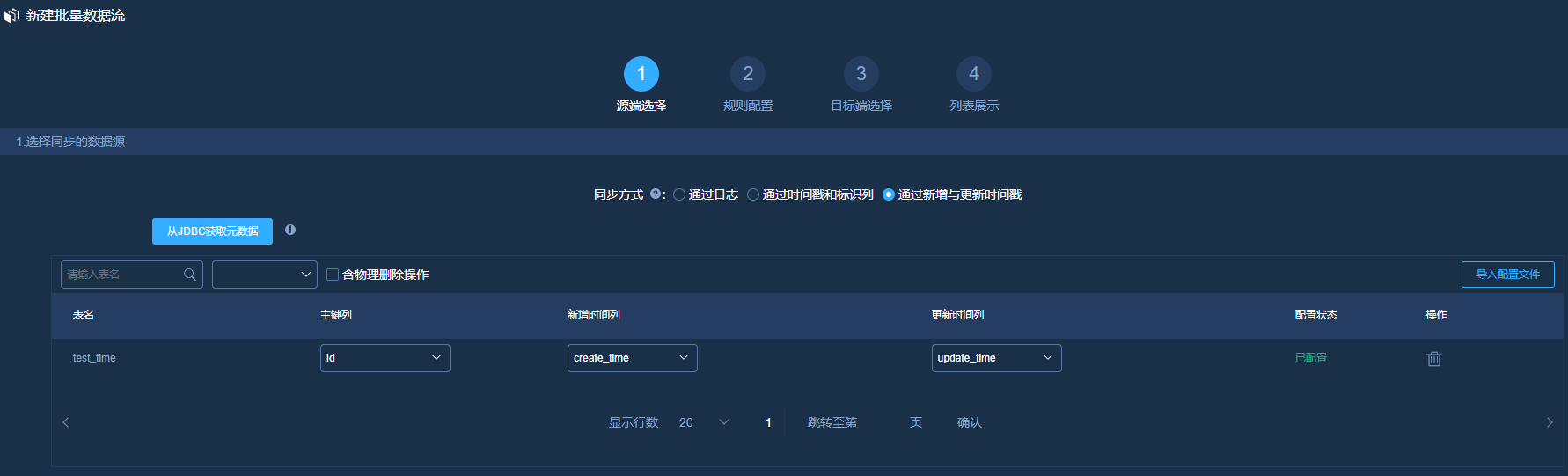
# 填写规范如下:
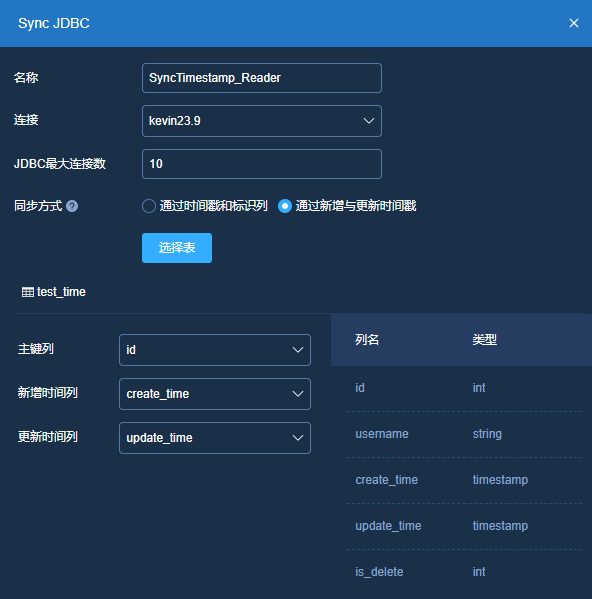
主键列:这里选取源表中的PK列ID
新增时间列:这里选取源表中的create_time字段
更新时间列:这里选取源表中的update_time字段规则配置: 这里不做配置介绍
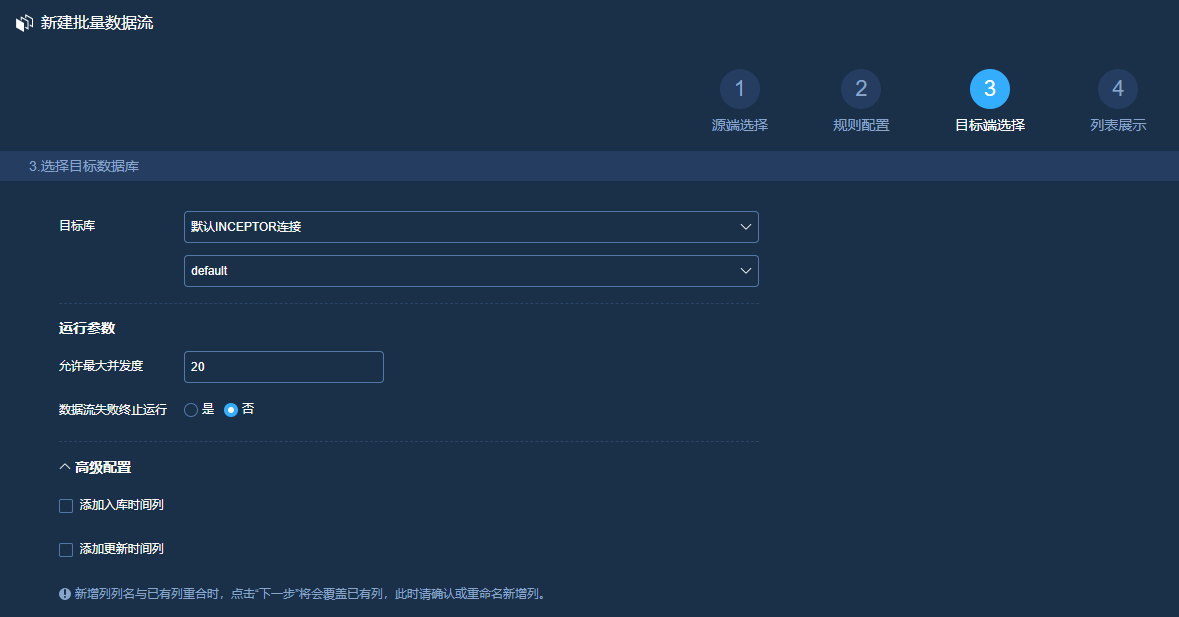
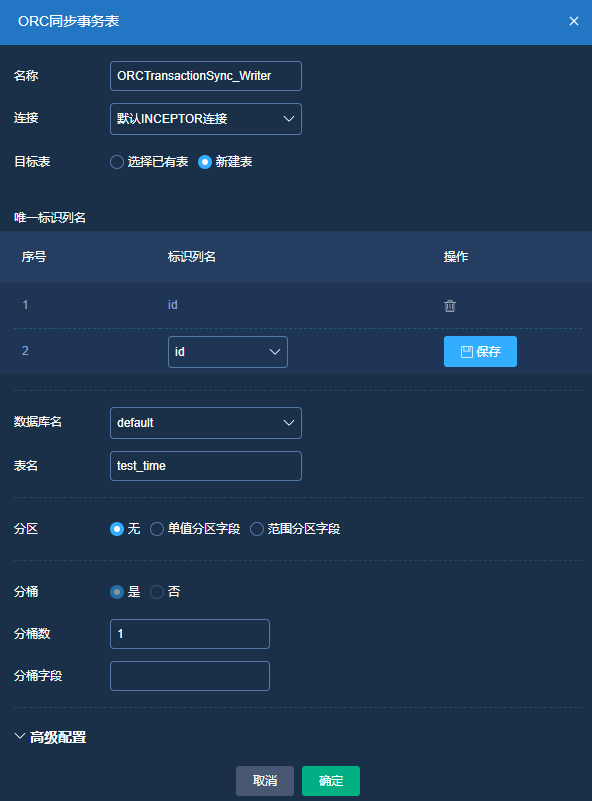
目标端选择:
列表展示:
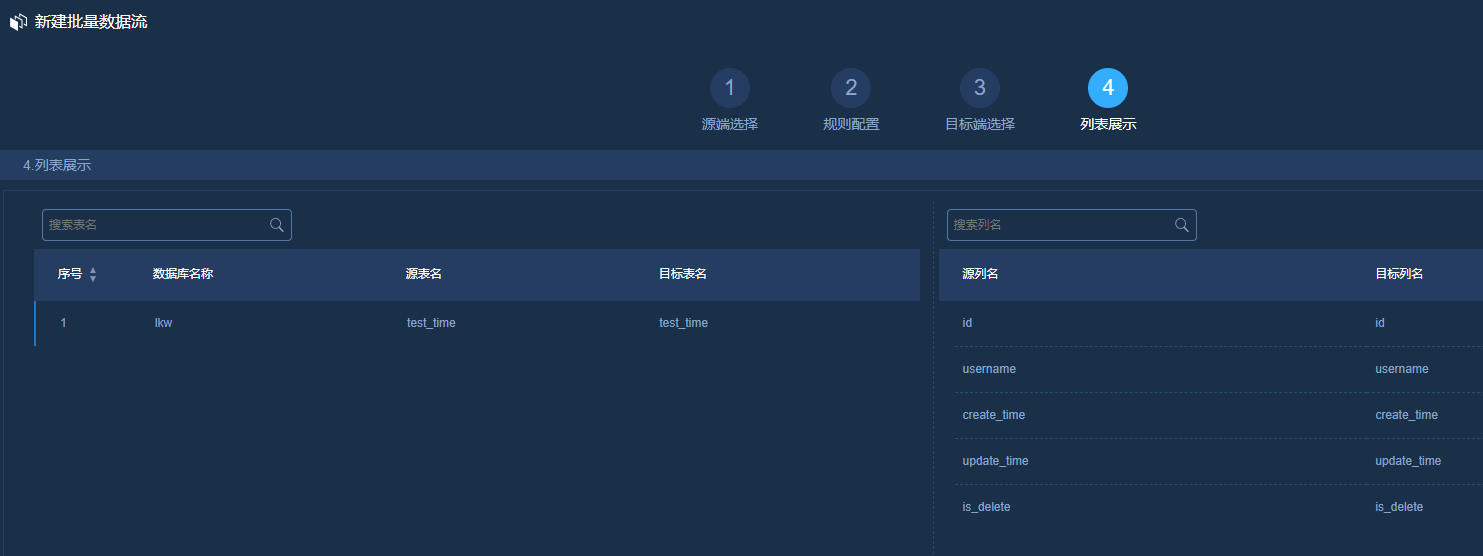
点击确定之后,批量数据流创建完成,点击到内部可以看到生成的数据流如下:
SyncJDBC_Reader:
ORCTransactionSync_Writer:
这里我们看下右上角初始的参数配置情况,tdt.job.record.last.original.value 和 tdt.job.record.last.value 均为空
step3:数据流调试(insert)
在mysql中模拟插入测试数据
INSERT INTO test_time(username,create_time)VALUES('zhangsan',NOW());
INSERT INTO test_time(username,create_time)VALUES('lisi',NOW());
INSERT INTO test_time(username,create_time)VALUES('wangwu',NOW());进入调试模式,点击调试按钮
首次调试,我们简单解析一下执行日志:
SyncJDBC_Reader阶段,通过jdbc读取源表,注意其中的mapreduce.jdbc.input.query,在第一次执行同步数据流时,由于参数中没有记录tdt.job.record.last.original.value 和 tdt.job.record.last.value,所以这里选取源数据中OP_TIME列<最大值的部分,相当于第一次做了一次全量导数。
CREATE TABLE default.TDT__INTERNAL__0ea678f4ab484def8661ab33da05b550 (
id int,username string,create_time timestamp,update_time timestamp,is_delete int
) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.tdt.JDBCSerde'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.tdt.JDBCDBInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
TBLPROPERTIES(
'mapreduce.jdbc.driver.class'='com.mysql.jdbc.Driver',
'mapreduce.jdbc.url'='jdbc:mysql://172.22.23.9:3306',
'mapreduce.jdbc.input.query'='select * from lkw.test_time where 1=1 and update_time <= \'2021-12-16 14:46:28.0\'',
'mapreduce.jdbc.input.count.query'='select count(*) from (select * from lkw.test_time where 1=1 and update_time <= \'2021-12-16 14:46:28.0\') tdt_sq_alias',
'mapreduce.jdbc.splits.number'='1',
'mapreduce.jdbc.username'='root', 'mapreduce.jdbc.password'='123456',
'mapreduce.jdbc.driver.file'='/tmp/transporter1/DRIVERS/mysql-connector-java-5.1.39_admin1638152300550.jar')--目标ORC事务表和源表table_data结构一致
CREATE TABLE IF NOT EXISTS default.test_time (
id int,username string,create_time timestamp,update_time timestamp,is_delete int
)
CLUSTERED BY
(id)
INTO
3 BUCKETS
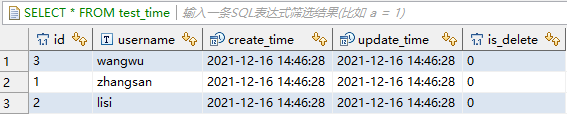
STORED AS ORC TBLPROPERTIES ('transactional'='true')这里我们看下参数变化,tdt.job.record.last.original.value 和 tdt.job.record.last.value 发生改变,值更新为2021-12-16 14:46:28.0 和 时间戳 1639637188
inceptor中当前数据:
step4:数据流调试(执行update)
在mysql中模拟update测试数据
UPDATE test_time set username='new_lisi' where id=2;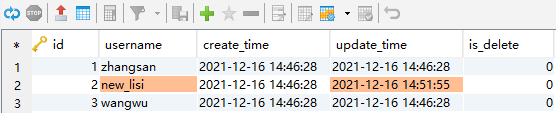
这里username和update_time均发生改变。
再次调试,分析一下日志:
SyncJDBC_Reader阶段,通过jdbc读取源表,注意其中的mapreduce.jdbc.input.query,update_time范围要求在tdt.job.record.last.original.value 和 当前源表最大值之间。
CREATE TABLE default.TDT__INTERNAL__4589588c772c401385b3583ca92d2a21 (
id int,username string,create_time timestamp,update_time timestamp,is_delete int
) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.tdt.JDBCSerde'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.tdt.JDBCDBInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
TBLPROPERTIES(
'mapreduce.jdbc.driver.class'='com.mysql.jdbc.Driver',
'mapreduce.jdbc.url'='jdbc:mysql://172.22.23.9:3306',
'mapreduce.jdbc.input.query'='select * from lkw.test_time where 1=1 and update_time <= \'2021-12-16 14:51:55.0\' and update_time > \'2021-12-16 14:46:28.0\'',
'mapreduce.jdbc.input.count.query'='select count(*) from (select * from lkw.test_time where 1=1 and update_time <= \'2021-12-16 14:51:55.0\' and update_time > \'2021-12-16 14:46:28.0\') tdt_sq_alias',
'mapreduce.jdbc.splits.number'='1',
'mapreduce.jdbc.username'='root',
'mapreduce.jdbc.password'='123456',
'mapreduce.jdbc.driver.file'='/tmp/transporter1/DRIVERS/mysql-connector-java-5.1.39_admin1638152300550.jar')inceptor中当前数据:
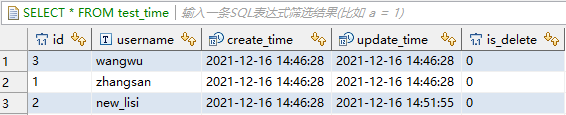
step5:数据流调试(执行delete)
在mysql中模拟逻辑删除数据
update test_time set is_delete=1 where id=3;
再次调试,分析一下日志:
SyncJDBC_Reader阶段,通过jdbc读取源表,注意其中的mapreduce.jdbc.input.query,UPDATE_TIME范围要求在tdt.job.record.last.original.value 和 最大值之间。
CREATE TABLE default.TDT__INTERNAL__dd1942d76bba44beacab9a83a51201df (
id int,username string,create_time timestamp,update_time timestamp,is_delete int
) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.tdt.JDBCSerde'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.tdt.JDBCDBInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
TBLPROPERTIES(
'mapreduce.jdbc.driver.class'='com.mysql.jdbc.Driver',
'mapreduce.jdbc.url'='jdbc:mysql://172.22.23.9:3306',
'mapreduce.jdbc.input.query'='select * from lkw.test_time where 1=1 and update_time <= \'2021-12-16 14:55:55.0\' and update_time > \'2021-12-16 14:51:55.0\'',
'mapreduce.jdbc.input.count.query'='select count(*) from (select * from lkw.test_time where 1=1 and update_time <= \'2021-12-16 14:55:55.0\' and update_time > \'2021-12-16 14:51:55.0\') tdt_sq_alias',
'mapreduce.jdbc.splits.number'='1',
'mapreduce.jdbc.username'='root',
'mapreduce.jdbc.password'='123456',
'mapreduce.jdbc.driver.file'='/tmp/transporter1/DRIVERS/mysql-connector-java-5.1.39_admin1638152300550.jar')inceptor中当前数据:
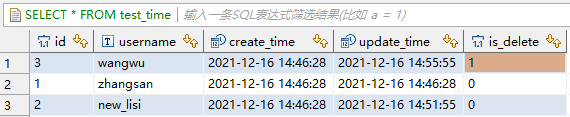
在做查询时,可以根据is_delete=0 来筛选有效数据。